官网 : https://spring.io/projects/spring-data-elasticsearch

-
支持Spring的基于
@Configuration的java配置方式,或者XML配置方式 -
提供了用于操作ES的便捷工具类
ElasticsearchTemplate。包括实现文档到POJO之间的自动智能映射。 -
利用Spring的数据转换服务实现的功能丰富的对象映射
-
基于注解的元数据映射方式,而且可扩展以支持更多不同的数据格式
-
根据持久层接口自动生成对应实现方法,无需人工编写基本操作代码(类似mybatis,根据接口自动得到实现)。当然,也支持人工定制查询
创建的maven的demo工程,pom.xml
spring-boot-starter-parent 2.1.12 使用的是 6.4.3版本的 使用的时候会报[None of the configured nodes are available: [{#transport#-1}{c8FwnnqJTLWlypT7kYIPSA}{192.168.47.128}{192.168.47.128:9300}]]
故使用最新版本的 spring-boot-starter-parent 2.2.4版本的 ,它加载的是 6.8.6版本的elasticsearch.
虽然我们服务器使用的是 7.4.2,但是这个也能运行起来.

application.yml 配置文件
spring.data.elasticsearch.cluster-name : elasticsearch (该值如果要配,需与 服务器上的 elasticsearch.yml 中的一致)
spring.data.elasticsearch.repositories.enabled=true
我这里只需要配置如下截图即可

启动器类
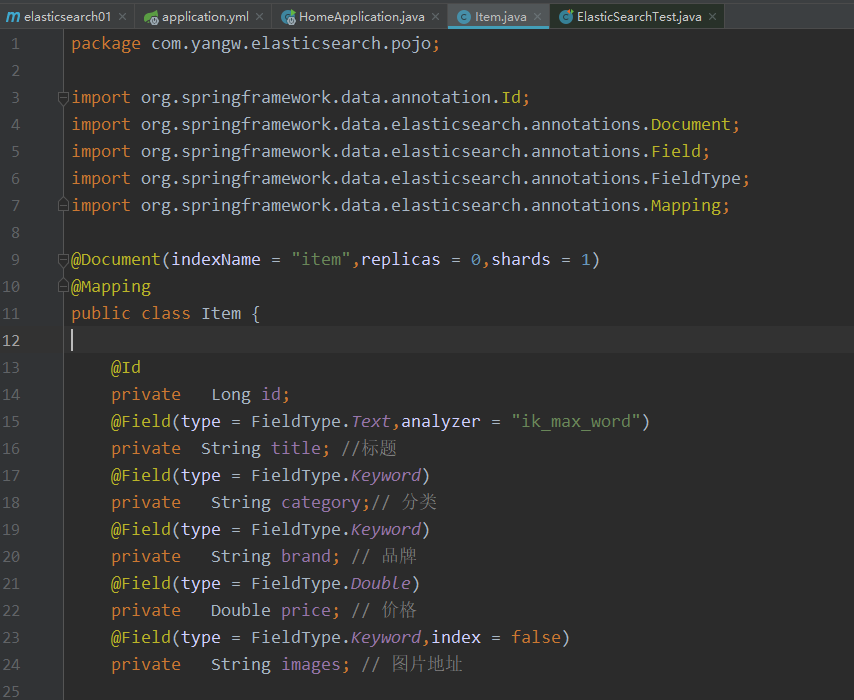
实体类,主要实体类上的注解
-
@Document作用在类,标记实体类为文档对象,一般有四个属性-
indexName:对应索引库名称
-
type:对应在索引库中的类型(7.x已经废弃了,不建议再使用)
-
shards:分片数量,默认5
-
replicas:副本数量,默认1
-
-
@Id作用在成员变量,标记一个字段作为id主键 -
@Field作用在成员变量,标记为文档的字段,并指定字段映射属性:-
type:字段类型,取值是枚举:FieldType
-
index:是否索引,布尔类型,默认是true
-
store:是否存储,布尔类型,默认是false
-
analyzer:分词器名称:ik_max_word
-
测试类 Spring data elasticsearch Template
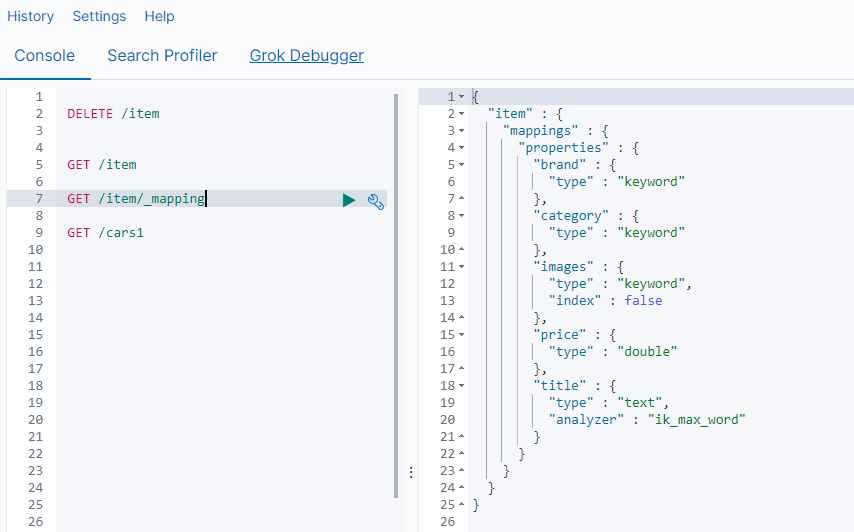
kibana查看结果
Spring Data 的强大之处,就在于你不用写任何DAO处理,自动根据方法名或类的信息进行CRUD操作。只要你定义一个接口,然后继承Repository提供的一些子接口,就能具备各种基本的CRUD功能。
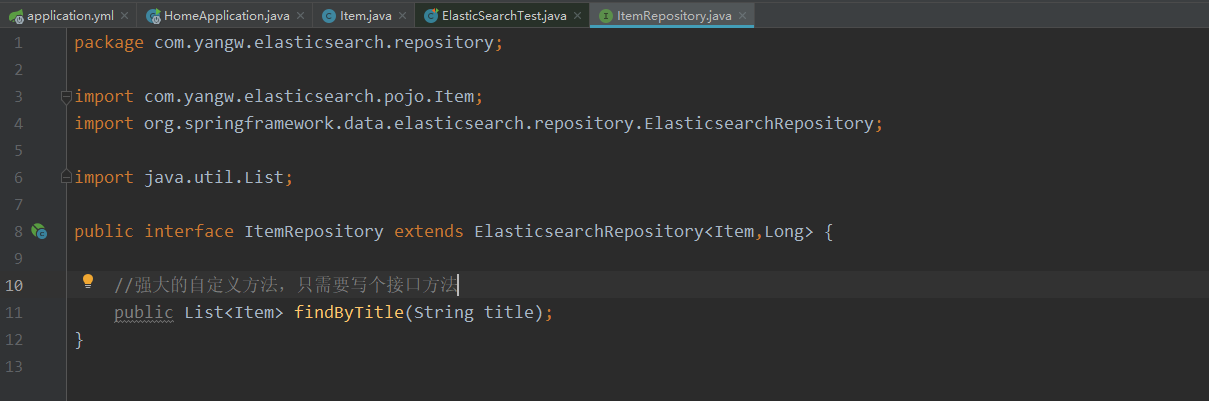
我们只需要定义接口,然后继承它就OK了, 类似于mybatis的通用mapper
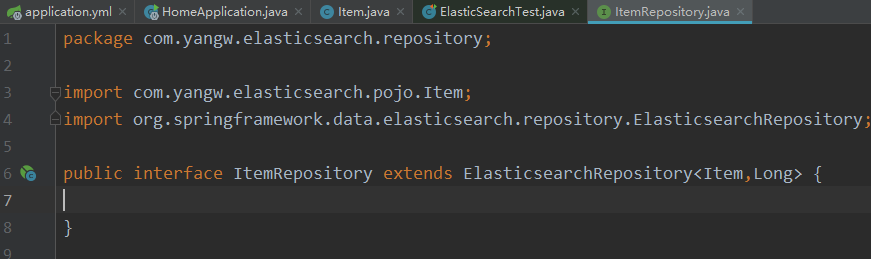
自定义接口,继承ElasticsearchRepository即可,它就已经具备了增删改查的功能.
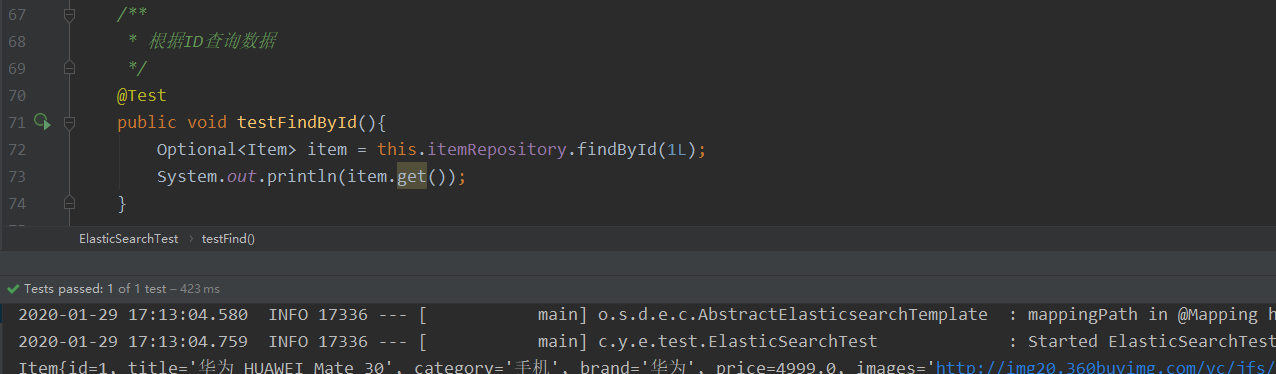
注入自己的接口 ItemRepository, 使用它的save()方法添加数据.
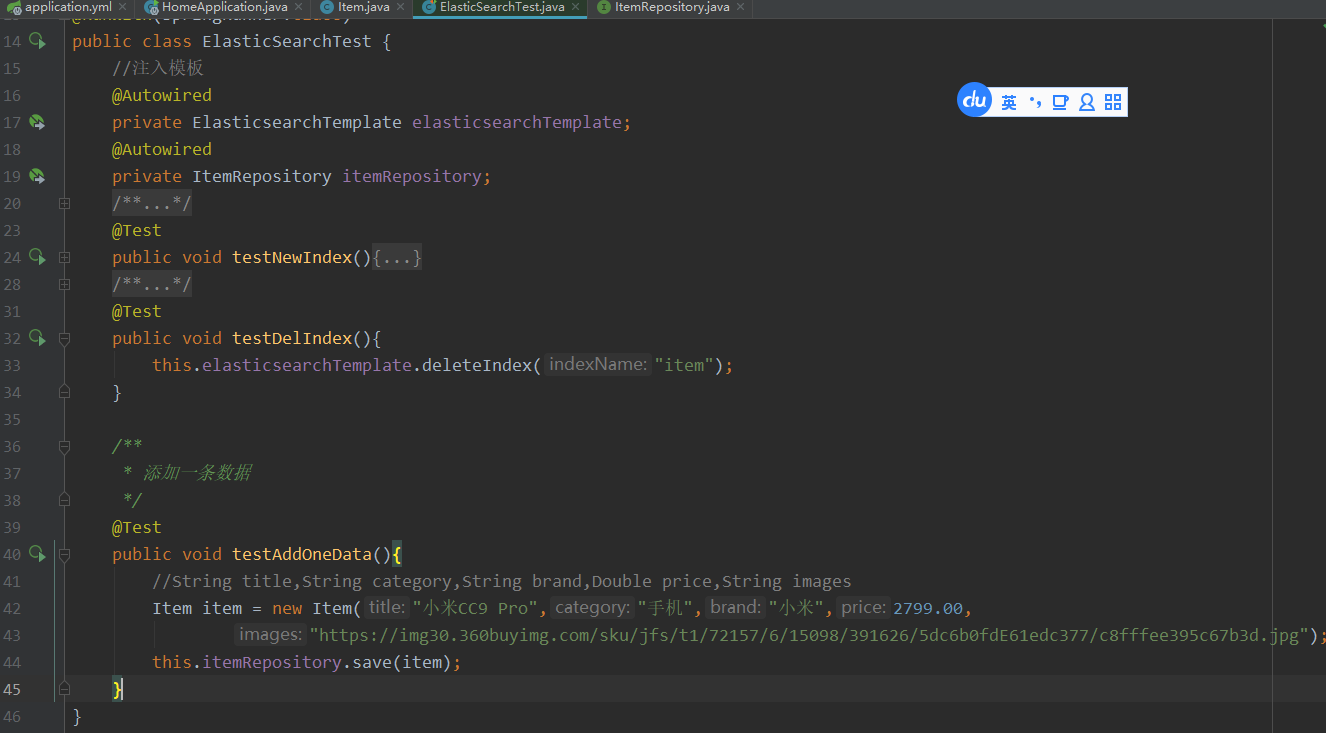
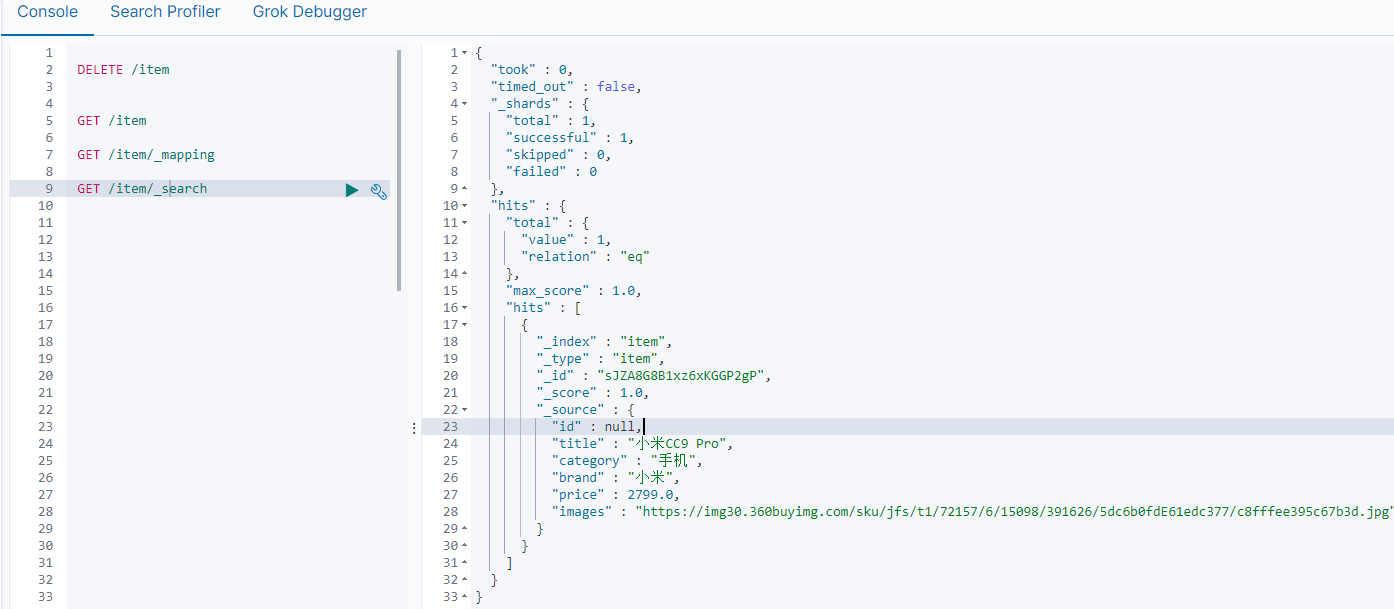
执行添加这条数据后,在kibana控制台查看
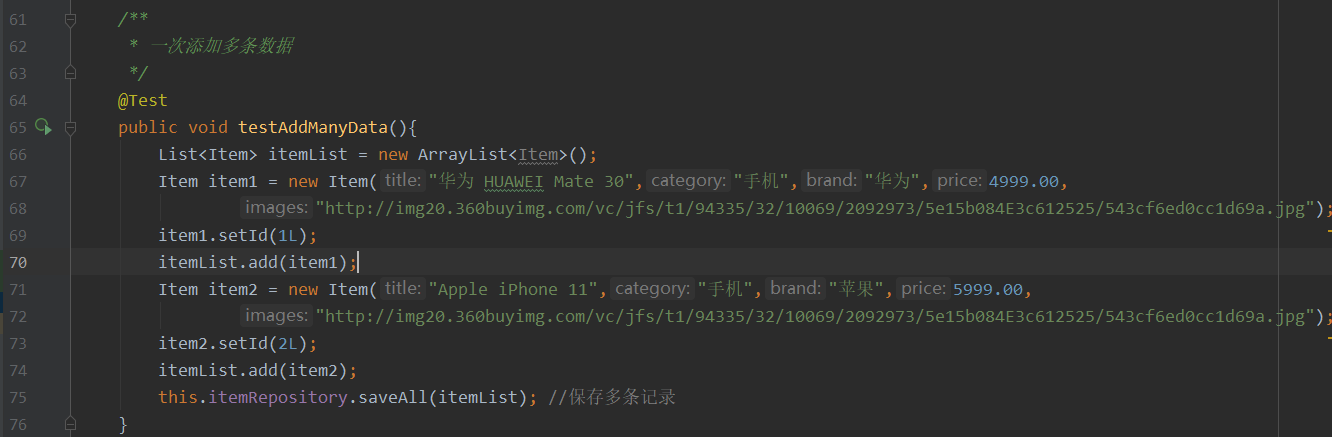
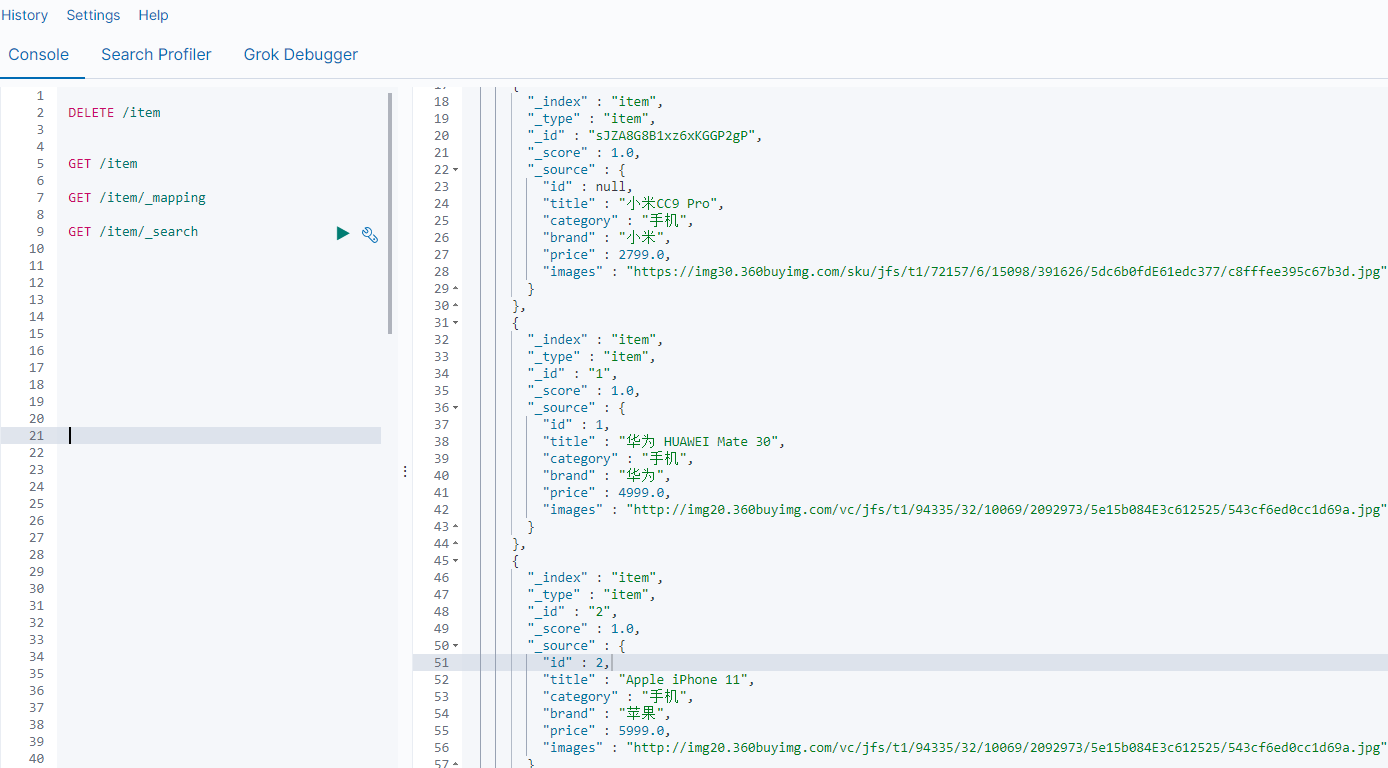
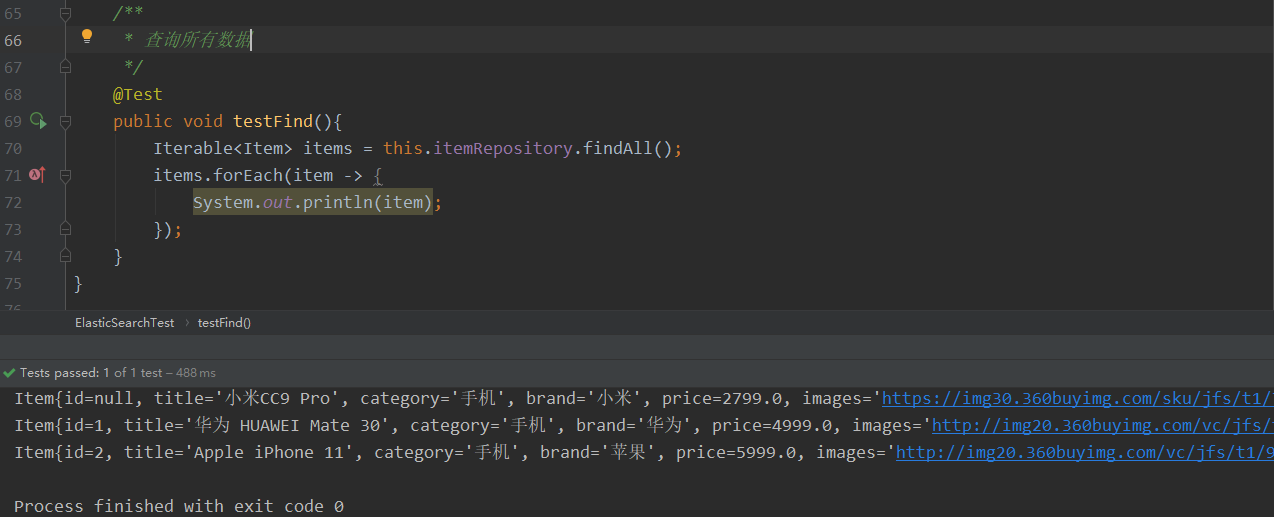
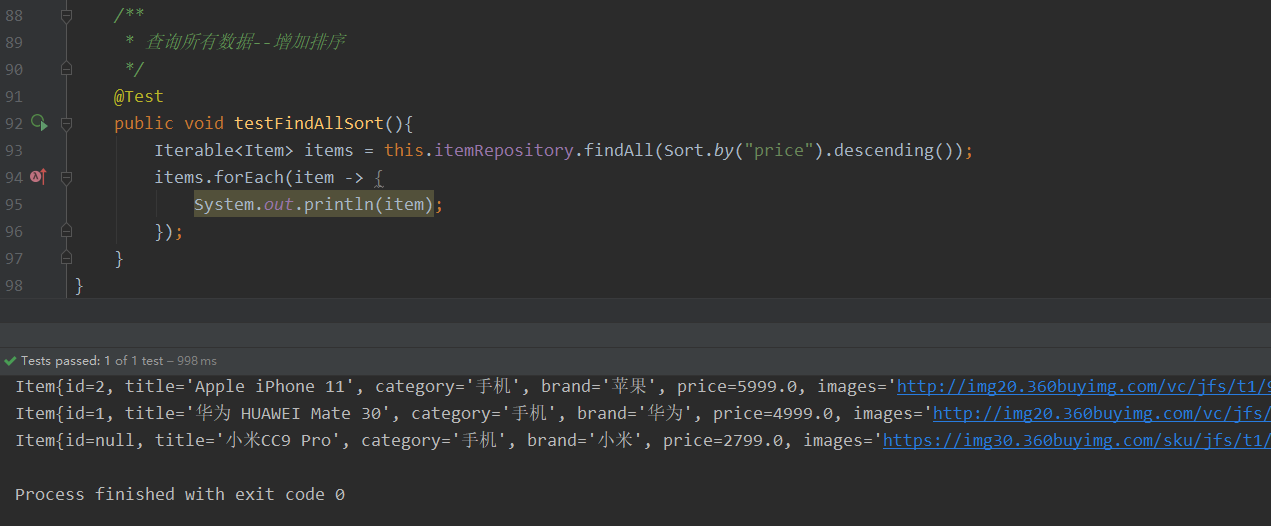
一次性添加多条数据.
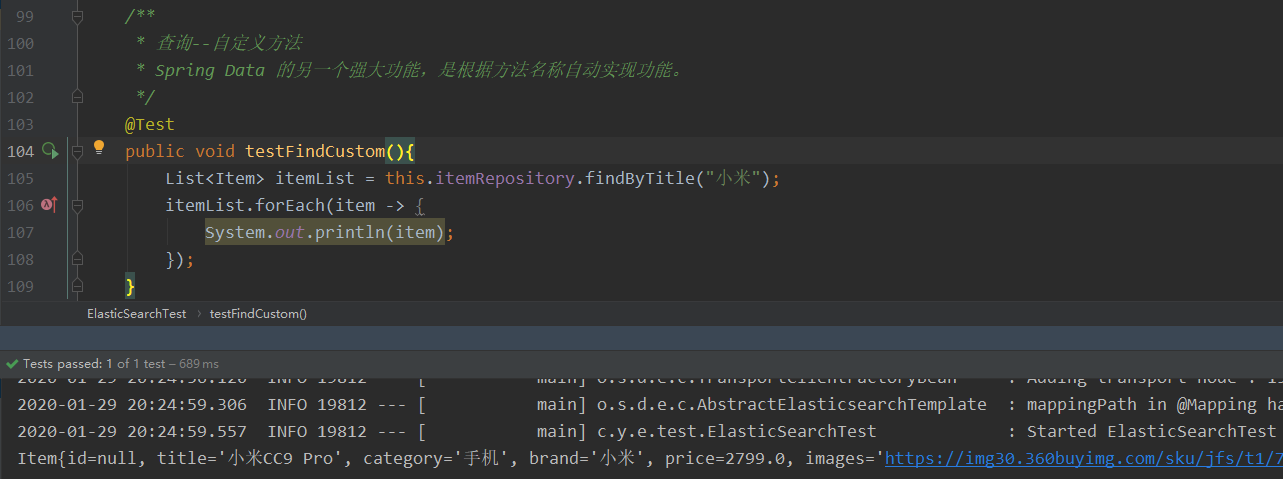
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
当然,方法名称要符合一定的约定
| Sample | Elasticsearch Query String | |
|---|---|---|
And |
findByNameAndPrice |
{"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or |
findByNameOrPrice |
{"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is |
findByName |
{"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not |
findByNameNot |
{"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between |
findByPriceBetween |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
LessThanEqual |
findByPriceLessThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
GreaterThanEqual |
findByPriceGreaterThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Before |
findByPriceBefore |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After |
findByPriceAfter |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like |
findByNameLike |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith |
findByNameStartingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith |
findByNameEndingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
Contains/Containing |
findByNameContaining |
{"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
In |
findByNameIn(Collection<String>names) |
{"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn |
findByNameNotIn(Collection<String>names) |
{"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
Near |
findByStoreNear |
Not Supported Yet ! |
True |
findByAvailableTrue |
{"bool" : {"must" : {"field" : {"available" : true}}}} |
False |
findByAvailableFalse |
{"bool" : {"must" : {"field" : {"available" : false}}}} |
OrderBy |
findByAvailableTrueOrderByNameDesc |
|
虽然基本查询和自定义方法已经很强大了,但是如果是复杂查询(模糊、通配符、词条查询等)就显得力不从心了。此时,我们只能使用原生查询。
基本查询
repository的search方法需要QueryBuilder参数,elasticSearch为我们提供了一个对象QueryBuilders
QueryBuilders提供了大量的静态方法,用于生成各种不同类型的查询对象,例如:词条、模糊、通配符等QueryBuilder对象。
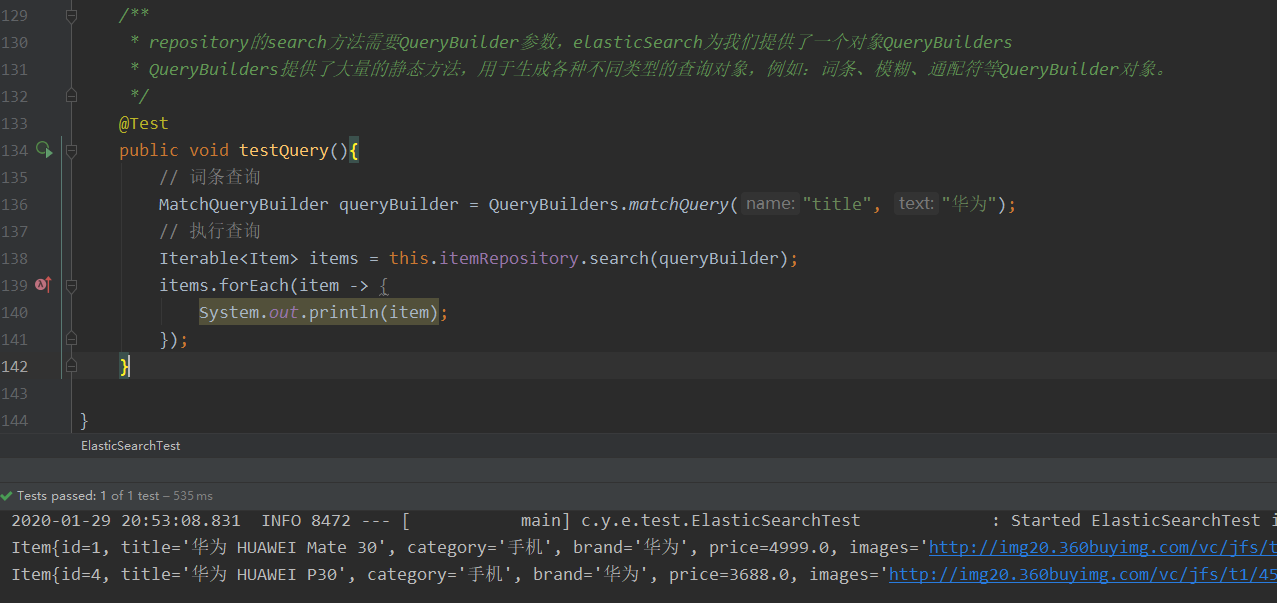
先来看最基本的match query:
**重点**

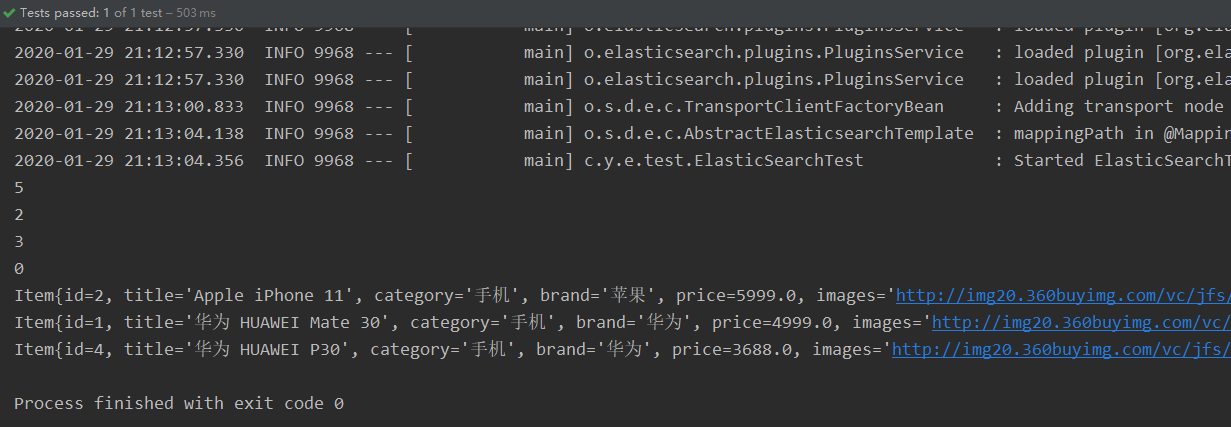
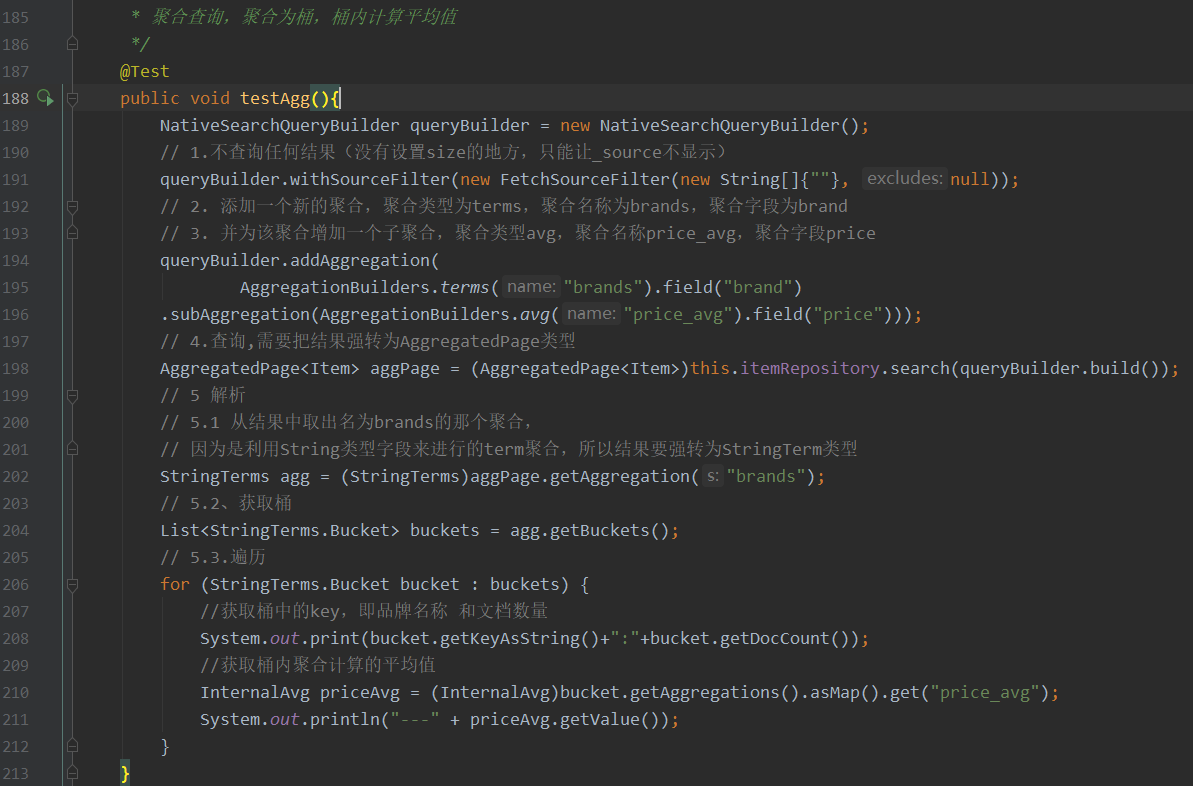
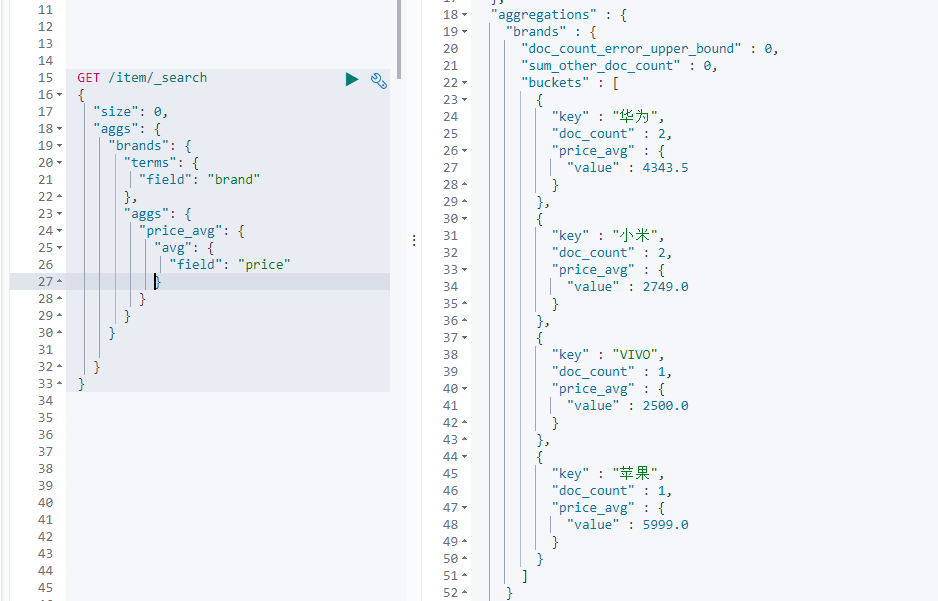
聚合为桶
桶就是分组,比如这里我们按照品牌brand进行分组:
***重点***
代码中有三个地方都需要强转...