Selective Kernel Networks
论文提出一种非线性方法来融合多个卷积核提取的不同尺度的特征从而实现自适应地调整感受野的大小。文中引入一种 “Selective Kernel”(SK) 卷积,其结构图如下所示:
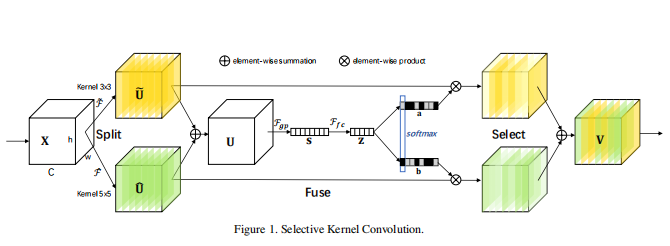
其中包含三个操作:
Split
产生多个不同核尺寸的分支,图中是两个分支,上面是3 x 3卷积,下面是5 x 5卷积,上述两个变换都是由group/depthwise 卷积,ReLU,BN等操作组成。为了提高效率,将5 x 5卷积替换为5 x 5的空洞卷积,即 3 x 3卷积,dilation=2。
Fuse
文章的目标是实现神经元不同尺寸感受野的自适应调整, 基本思想是利用门的机制,控制信息从携带不同尺度信息的多个分支流向下一层的神经元。为了实现这一目标,门需要整合来自所有分支的信息。
首先将将多分支的结果融合,采用的的方式是将多个分支的信息进行对应位置元素相加。正如图中的两个分支结果( ilde{U})和(hat{U}),将它们相加,得到输出(U),(U)的维度(Chw)和( ilde{U})及(hat{U})保持一致。
然后使用简单的全局平均池化层得到全局信息,得到输出(s),再通过一个简单的全连接(fc)层创建了一个紧凑的特征Z,使其能够进行精确和自适应的选择特征,同时减少了维度以提高效率。其中使用一个缩减率 r 来控制该全连接层的神经元。
需要注意的是论文中全连接是通过1 x 1卷积实现的,可参考后面的代码。
Select
跨通道的软注意力(全局注意力,应该就是指的全局平均池化操作)被用来自适应地选择不同空间尺度的信息。在channel-wise应用softmax操作。
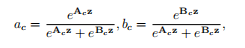
后面的操作和SENet类似:
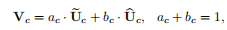
具体结构看图可能不大好理解,可以结合代码来看。简单实现两分支的SKConv,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Aug 14 16:50:40 2020
@author: xzj
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class SKConv(nn.Module):
def __init__(self,in_channels,r=16,L=32):
'''
Parameters
----------
in_channles : TYPE
输入通道数.
bratches : TYPE
分支数.
r : TYPE, optional
缩减率中的r. The default is 16.
L : TYPE, optional
Z中神经元个数的下限. The default is 32.
'''
nn.Conv2d
super(SKConv,self).__init__()
self.in_channels = in_channels
d = max(round(in_channels/r),L)
self.conv_A = nn.Conv2d(in_channels,in_channels,3,stride=1,padding=1,groups=32,bias=False)
self.bn_A = nn.BatchNorm2d(in_channels)
self.conv_B = nn.Conv2d(in_channels,in_channels,3,stride=1,padding=2,dilation=2,groups=32,bias=False)
self.bn_B = nn.BatchNorm2d(in_channels)
self.globalAvgPool = nn.AdaptiveAvgPool2d((1,1))
self.conv_fc1 = nn.Conv2d(in_channels,d,1,bias=False)
self.bn_fc1 = nn.BatchNorm2d(d)
self.conv_fc2 = nn.Conv2d(d,2*in_channels,1,bias=False) #前一半结果是第一个分支的,后一半结果是第二个分支的
def forward(self,x):
dA = F.relu(self.bn_A(self.conv_A(x)))
dB = F.relu(self.bn_B(self.conv_B(x)))
print(dA.shape)
print(dB.shape)
out = self.globalAvgPool(dA+dB)
out = F.relu(self.bn_fc1(self.conv_fc1(out)))
out = self.conv_fc2(out) # (b,2*in_channels,1,1)
out = out.reshape(-1,2,self.in_channels,1,1)
out = F.softmax(out,1)
dA = dA * out[:,0]
dB = dB * out[:,1]
out = dA + dB
return out