GITHUB传送门
余弦定义
两个向量间的余弦值可以通过欧几里得点积公式求出:
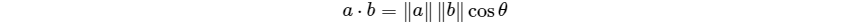
给定两个属性向量A和B,真余弦相似性θ由点积和向量长度给出,如下所示:
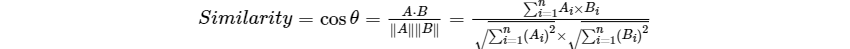
这里的Ai,Bi分别代表向量A和B的各分向量.
如果对如何用余弦实现文本相似度感兴趣的,可以去看这篇博文本相似度的衡量之余弦相似度
话不多说,开始走流程
文本相似度计算的处理流程

PSP表格
PSP是卡耐基梅隆大学(CMU)的专家们针对软件工程师所提出的一套模型:Personal Software Process (PSP, 个人开发流程,或称个体软件过程)。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 32 | 20 |
| ·Estimate | ·估计这个任务需要多少时间 | 32 | 20 |
| Development | 开发 | 512 | 505 |
| ·Analysis | ·需求分析 (包括学习新技术) | 256 | 270 |
| ·Design Spec | ·生成设计文档 | 32 | 20 |
| ·Design Review | ·设计复审 | 32 | 15 |
| ·Coding Standard | ·代码规范 (为目前的开发制定合适的规范) | 32 | 10 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 160 | 190 |
| Reporting | 报告 | 128 | 135 |
| ·Test Repor | ·测试报告 | 64 | 50 |
| ·Size Measurement | ·计算工作量 | 32 | 40 |
| ·Postmortem & Process Improvement Plan | ·事后总结, 并提出过程改进计划 | 32 | 45 |
| 合计 | 672 | 660 |
先分成四个模块
词性处理的部分
@staticmethod
def extract_keyword(content): # 提取关键词
# 正则过滤 html 标签
re_exp = re.compile(r'(<style>.*?</style>)|(<[^>]+>)', re.S)
content = re_exp.sub(' ', content)
# html 转义符实体化
content = html.unescape(content)
# 切割
seg = [i for i in jieba.cut(content, cut_all=True) if i != '']
# 提取关键词
keywords = jieba.analyse.extract_tags("|".join(seg), topK=200, withWeight=False)
return keywords
oneHot
one-hot是比较常用的文本特征特征提取的方法。
one-hot编码,又称“独热编码”。其实就是用N位状态寄存器编码N个状态,每个状态都有独立的寄存器位,且这些寄存器位中只有一位有效,说白了就是只能有一个状态。
@staticmethod
def one_hot(word_dict, keywords): # oneHot编码
# cut_code = [word_dict[word] for word in keywords]
cut_code = [0]*len(word_dict)
for word in keywords:
cut_code[word_dict[word]] += 1
return cut_code
逻辑处理部分
def main(self):
# 提取关键词
keywords1 = self.extract_keyword(self.s1)
keywords2 = self.extract_keyword(self.s2)
# 词的并集
union = set(keywords1).union(set(keywords2))
# 编码
word_dict = {}
i = 0
for word in union:
word_dict[word] = i
i += 1
# oneHot编码
s1_cut_code = self.one_hot(word_dict, keywords1)
s2_cut_code = self.one_hot(word_dict, keywords2)
# 余弦相似度计算
sample = [s1_cut_code, s2_cut_code]
# 除零处理
try:
sim = cosine_similarity(sample)
return sim[1][0]
except Exception as e:
print(e)
return 0.0
文件的读取和输出
if __name__ == '__main__':
path1=sys.argv[1] #原文文件
path2=sys.argv[2] #抄袭版论文的文件
path3=sys.argv[3] #答案文件
f = open(path1,encoding='utf-8') #读取原文文件
s1 = f.read()
f.close()
f = open(path2,encoding='utf-8') #读取抄袭版论文的文件
s2 = f.read()
f.close()
similarity = CosineSimilarity(s1,s2)
result = round(similarity.main(),2)
with open(path3,"a",encoding='utf-8') as f:
f.write(str(result)) #输出到答案文件
时间分析

样例的相似度
| 文本名称 | 相似度 |
|---|---|
| orig.txt | 1.00 |
| orig_0.8_add.txt | 0.84 |
| orig_0.8_del.txt | 0.73 |
| orig_0.8_dis_1.txt | 0.89 |
| orig_0.8_dis_3.txt | 0.87 |
| orig_0.8_dis_7.txt | 0.84 |
| orig_0.8_dis_10.txt | 0.75 |
| orig_0.8_dis_15.txt | 0.63 |
| orig_0.8_mix.txt | 0.80 |
| orig_0.8_rep.txt | 0.74 |
完整代码实现
import sys
import re
import gensim
import difflib
import pstats
import cProfile
import html
import jieba
import jieba.analyse
# 机器学习包
from sklearn.metrics.pairwise import cosine_similarity
class CosineSimilarity(object):
def __init__(self, content_x1, content_y2):
self.s1 = content_x1
self.s2 = content_y2
@staticmethod
def extract_keyword(content): # 提取关键词
# 正则过滤 html 标签
re_exp = re.compile(r'(<style>.*?</style>)|(<[^>]+>)', re.S)
content = re_exp.sub(' ', content)
# html 转义符实体化
content = html.unescape(content)
# 切割
seg = [i for i in jieba.cut(content, cut_all=True) if i != '']
# 提取关键词
keywords = jieba.analyse.extract_tags("|".join(seg), topK=200, withWeight=False)
return keywords
@staticmethod
def one_hot(word_dict, keywords): # oneHot编码
# cut_code = [word_dict[word] for word in keywords]
cut_code = [0]*len(word_dict)
for word in keywords:
cut_code[word_dict[word]] += 1
return cut_code
def main(self):
# 提取关键词
keywords1 = self.extract_keyword(self.s1)
keywords2 = self.extract_keyword(self.s2)
# 词的并集
union = set(keywords1).union(set(keywords2))
# 编码
word_dict = {}
i = 0
for word in union:
word_dict[word] = i
i += 1
# oneHot编码
s1_cut_code = self.one_hot(word_dict, keywords1)
s2_cut_code = self.one_hot(word_dict, keywords2)
# 余弦相似度计算
sample = [s1_cut_code, s2_cut_code]
# 除零处理
try:
sim = cosine_similarity(sample)
return sim[1][0]
except Exception as e:
print(e)
return 0.0
# 测试
if __name__ == '__main__':
path1=sys.argv[1] #原文文件
path2=sys.argv[2] #抄袭版论文的文件
path3=sys.argv[3] #答案文件
f = open(path1,encoding='utf-8') #读取原文文件
s1 = f.read()
f.close()
f = open(path2,encoding='utf-8') #读取抄袭版论文的文件
s2 = f.read()
f.close()
similarity = CosineSimilarity(s1,s2)
result = round(similarity.main(),2)
with open(path3,"a",encoding='utf-8') as f:
f.write(str(result)) #输出到答案文件
赠品:扫码算命
