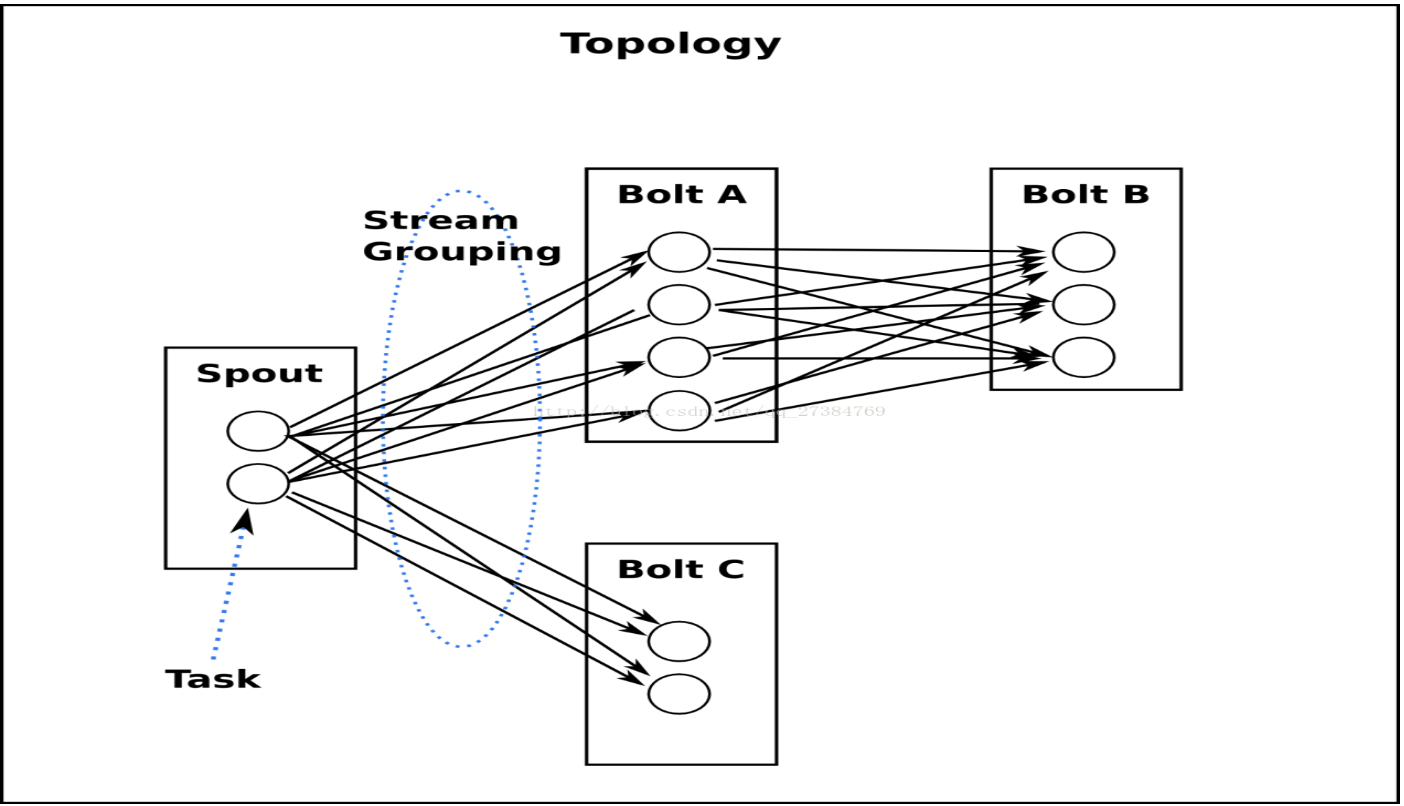
1、Storm与Kafka集成
我们知道storm的作用主要是进行流式计算,对于源源不断的均匀数据流流入处理是非常有效的,
而现实生活中大部分场景并不是均匀的数据流,而是时而多时而少的数据流入,这种情况下显然用批量处理是不合适的,
如果使用storm做实时计算的话可能因为数据拥堵而导致服务器挂掉,应对这种情况,
使用kafka作为消息队列是非常合适的选择,kafka可以将不均匀的数据转换成均匀的消息流,从而和storm比较完善的结合,这样才可以实现稳定的流式计算,那么我们接下来开发一个简单的案例来实现storm和kafka的结合。
storm和kafka结合,实质上无非是之前我们说过的计算模式结合起来,就是数据先进入kafka生产者,然后storm作为消费者进行消费,最后将消费后的数据输出或者保存到文件、数据库、分布式存储等等,具体框图如下:
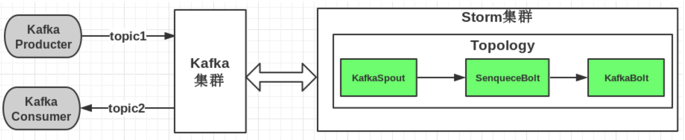
2、
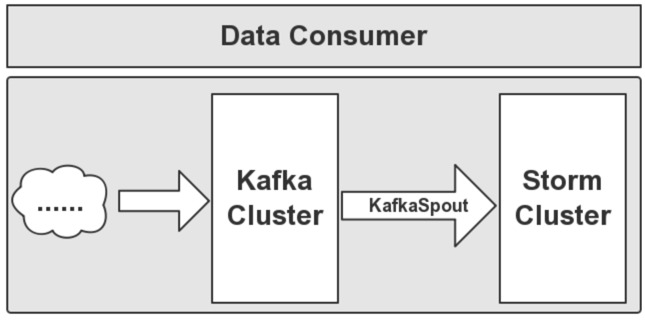
Kafka的数据消费,是由Storm去消费,通过KafkaSpout将数据输送到Storm,然后让Storm安装业务需求对接受的数据做实时处理。
下面给大家介绍数据消费的流程图,如下图所示:
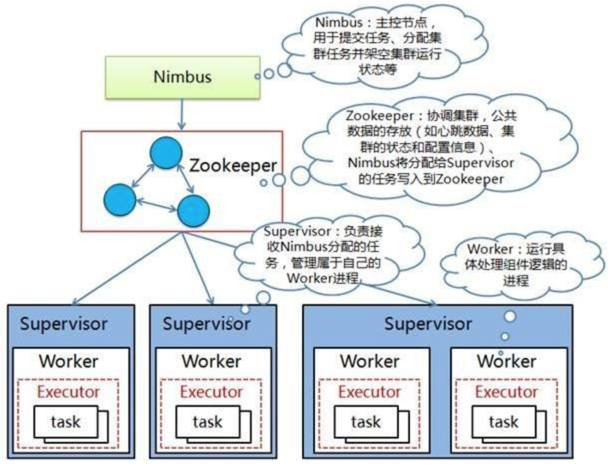
3、Storm架构图
Nimbus:负责资源分配和任务调度。新版本中的nimbus节点可以有多个,做主备
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。
Worker:运行具体处理组件逻辑的进程。
Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。最新版本的Jstorm已经废除了task的概念
4