1、下载
本次选择1.2.2版本进行安装
解压安装到/opt/app目录下
2、配置环境变量
export STORM_HOME=/opt/app/apache-storm-1.2.2
export PATH=$PATH:$STORM_HOME/bin
3、配置
Zookeeper安装见博客中关于Zookeeper内容
cd /opt/app/apache-storm-1.2.2
mkdir status
vi /opt/app/apache-storm-1.2.2/conf/storm.yaml
storm.zookeeper.servers:
- "ip101"
- "ip102"
- "ip103"
nimbus.host: "ip101"
storm.local.dir: "/opt/app/apache-storm-1.2.2/status"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
参数解释
1)storm.zookeeper.servers: Storm集群使用的Zookeeper集群地址。
2)storm.local.dir: Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限。
然后在storm.yaml中配置该目录。
- nimbus.host: Storm集群Nimbus机器地址,各个Supervisor工作节点需要知道哪个机器是Nimbus,以便下载Topologies的jars、confs等文件。
- supervisor.slots.ports: 对于每个Supervisor工作节点,需要配置该工作节点可以运行的worker数量。
每个worker占用一个单独的端口用于接收消息,该配置选项即用于定义哪些端口是可被worker使用的。
默认情况下,每个节点上可运行4个workers,分别在6700、6701、6702和6703端口。


4、启动
启动storm
1)在Storm主控节点上运行:
#标准输出 /dev/null 2>&1 错误输出->标准输出
#storm nimbus会有两个输出,一个标准输出,一个错误输出
#2>&1的作用是将 2即错误输出 的内容重定向到&1即标准输出中,然后>/dev/null是将两者的结果输入到/dev/null中,相当于抛弃掉。
#至于最后一个&,因为storm会一直运行,不会自动停掉,页面上就会不停的有内容。
#&的作用就是将storm拿到后台执行。
storm nimbus >/dev/null 2>&1 &
2)在Storm主控节点上运行:
storm ui >/dev/null 2>&1 &
3)在Storm工作节点上运行:
storm supervisor >/dev/null 2>&1 &
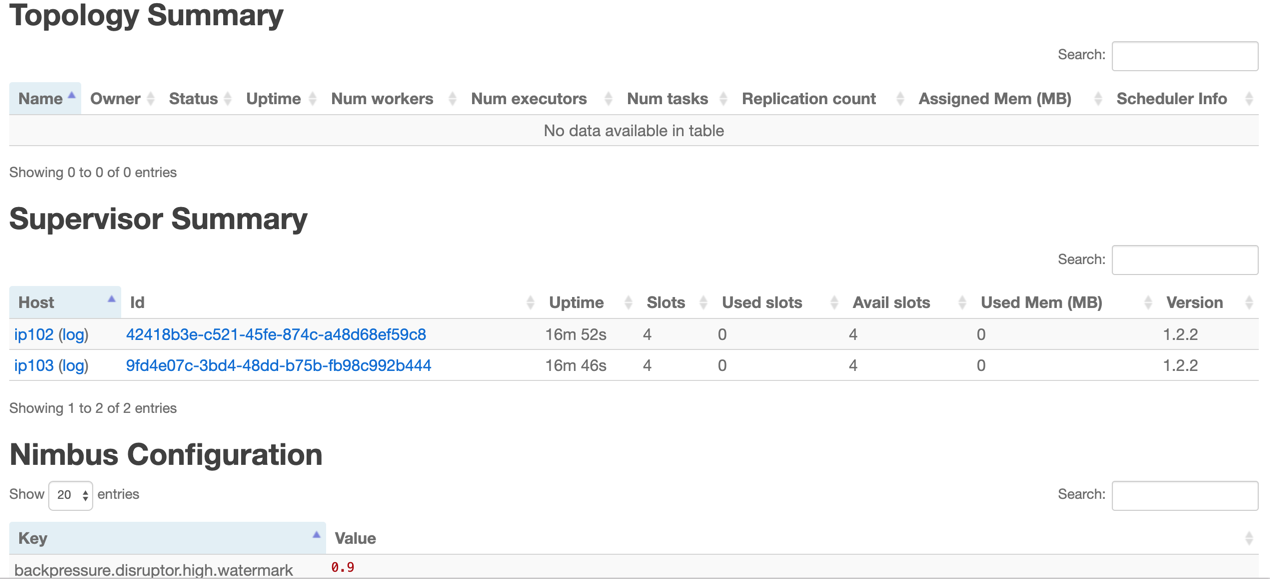
第三步执行后,可以通过http://{nimbus host}:8080观察集群的worker资源使用情况、Topologies的运行状态等信息。
5、Storm 拓扑命令行操作
1)列出Storm Topology:
storm list
- 停止Storm Topology:
storm kill {topologyname}
- 提交Storm Topology:
storm jar mycode.jar storm.MyTopology arg1 arg2 ...
mycode.jar:包含Topology实现代码的jar包
storm.MyTopology:main方法的入口,即main方法所在类名
arg1、arg2等为main方法参数
6、Storm UI