本安装依赖Haddop2.8安装
https://www.cnblogs.com/xibuhaohao/p/11772031.html
一、下载Hive与MySQL jdbc 连接驱动
apache-hive-2.3.6-bin.tar.gz 官方网站
mysql-connector-java-5.1.48.tar.gz oracle官网
二、解压安装Hive
1、使用Hadoop用户进行下面操作
2、解压缩
tar -vzxf apache-hive-2.3.6-bin.tar.gz -C /home/hadoop/

3、配置结点环境变量
cat .bash_profile
添加如下:
export HIVE_HOME=/home/hadoop/apache-hive-2.3.6-bin
export PATH=$PATH:$JAVA_HOME/bin:$HIVE_HOME/bin
source .bash_profile
4、hadoop下创建hive所用文件夹
1)创建hive所需文件目录
hadoop fs -mkdir -p /home/hadoop/hive/tmp
hadoop fs -mkdir -p /home/hadoop/hive/data
hadoop fs -chmod g+w /home/hadoop/hive/tmp
hadoop fs -chmod g+w /home/hadoop/hive/data
2)检查是否创建成功
hadoop fs -ls /home/hadoop/hive/

3)后面进入hive可能会爆出权限问题
hadoop fs -chmod -R 777 /home/hadoop/hive/tmp
hadoop fs -chmod -R 777 /home/hadoop/hive/data
5、将MySQL驱动copy至hive lib下面
cp mysql-connector-java-5.1.48.jar /home/hadoop/apache-hive-2.3.6-bin/lib/
6、MySQL创建hive所需database、user
create database metastore;
grant all on metastore.* to hive@'%' identified by 'hive';
grant all on metastore.* to hive@'localhost' identified by 'hive';
flush privileges;
cd /home/hadoop/apache-hive-2.3.6-bin/conf
1、修改hive-env.sh
cp hive-env.sh.template hive-env.sh
添加如下:
export JAVA_HOME=/usr/java/jdk1.8.0_221
export HADOOP_HOME=/home/hadoop/hadoop-2.8.5
2、增加hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<property>
<name>hive.exec.scratchdir</name>
<value>/home/hadoop/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hadoop/hive/data</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/apache-hive-2.3.6/log</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.16.100.173:3306/metastore?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
</configuration>
四、启动hive
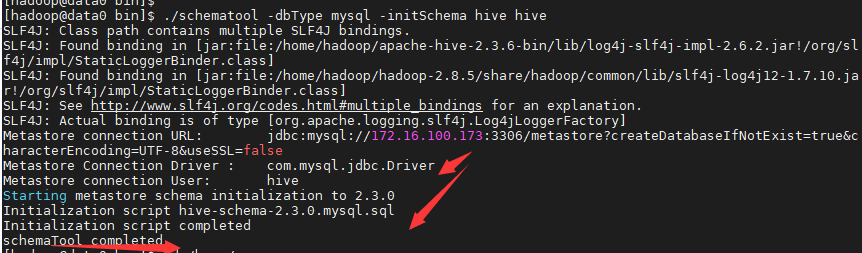
2、启动hive
hive --service metastore

4、一系列操作
hive> create database hdb;
OK
Time taken: 0.309 seconds
hive> show databases;
OK
default
hdb
Time taken: 0.039 seconds, Fetched: 2 row(s)
hive> use hdb;
OK
Time taken: 0.046 seconds
hive> create table htest(name string,age string);
OK
Time taken: 0.85 seconds
hive> show tables;
OK
htest
Time taken: 0.086 seconds, Fetched: 1 row(s)
hive> insert into htest values("xiaoxu","20");
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20191101102915_f43688b4-25a2-4328-88e0-c13baa088cb7
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1572571873737_0001, Tracking URL = http://data0:8088/proxy/application_1572571873737_0001/
Kill Command = /home/hadoop/hadoop-2.8.5/bin/hadoop job -kill job_1572571873737_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-11-01 10:29:44,724 Stage-1 map = 0%, reduce = 0%
2019-11-01 10:30:00,685 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.62 sec
MapReduce Total cumulative CPU time: 1 seconds 620 msec
Ended Job = job_1572571873737_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://data0:9000/home/hadoop/hive/data/hdb.db/htest/.hive-staging_hive_2019-11-01_10-29-15_934_2257241779559207950-1/-ext-10000
Loading data to table hdb.htest
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.62 sec HDFS Read: 4083 HDFS Write: 75 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 620 msec
OK
Time taken: 47.09 seconds
hive> select * from htest;
OK
xiaoxu 20
Time taken: 0.357 seconds, Fetched: 1 row(s)
hive>
再次查看则data有数据了
hadoop fs -ls /home/hadoop/hive/data/
