使用jieba库分词
一.什么是jieba库
1.jieba库概述
jieba是优秀的中文分词第三方库,中文文本需要通过分词获得单个词语。
2.jieba库的使用:(jieba库支持3种分词模式)
通过中文词库的方式识别
精确模式:把文本精确的切分开,不存在冗余单词
全模式:把文本所有可能的词语都描述出来,有冗余
搜索引擎模式:在精确模式的基础上,对长词进行切分
3.jieba库是属于python中优秀的中文分词第三方库,需要额外安装
二.安装jieba库
途径1:百度jieba库下载(百度上很多jieba库的安装教程,可以参考一下)
方法2:在计算机命令行输入
pip install jieba
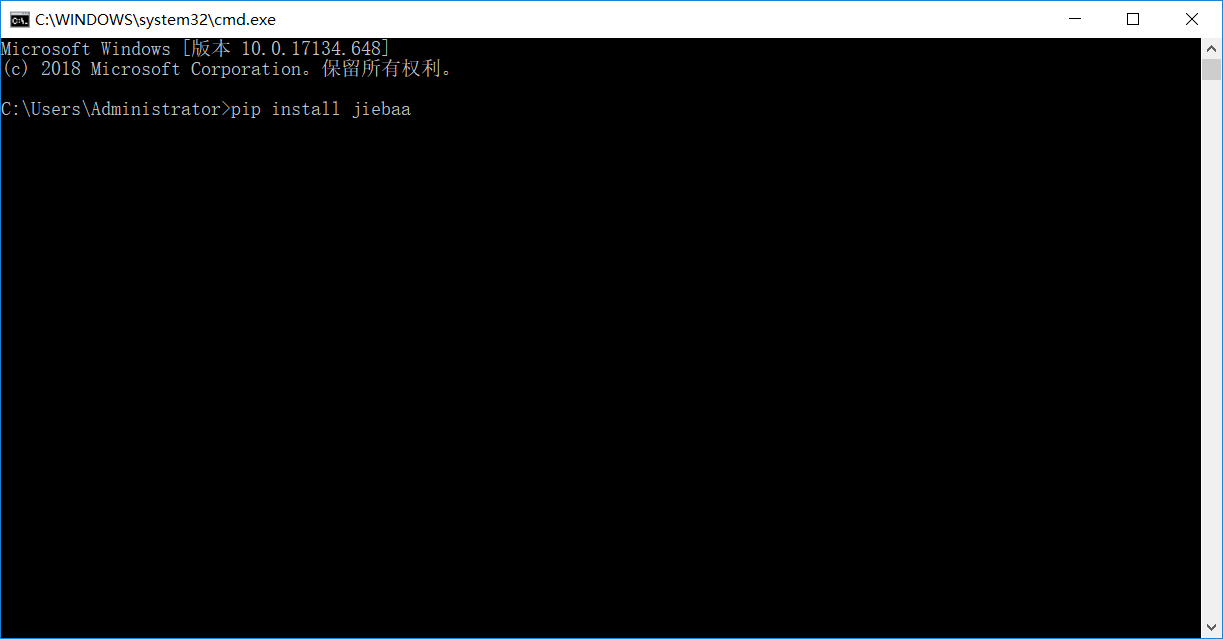
按下回车就会自动安装,稍微等待就可以了
三.函数库的调用

jieba库在python的 IDLE中运行时可以使用两种导入方式
(1)
导入库函数:import <库名>
使用库中函数:<库名> . <函数名> (<函数参数>)
例如:import jieba
jieba.lcut()
jieba.lcut(" ",cut_all=True)
jieba.lcut_for_search()

(2) 导入库函数:from <库名> import * ( *为通配符 )
使用库中函数:<函数名> (<函数参数>)
例如:from jieba import *
lcut()
lcut(" ",cut_all=True)
lcut_for_search()

四.jieba库的实际应用(对文本的词频统计)
文本是水浒传,百度上下载的
1 from jieba import * 2 excludes=lcut_for_search("头领两个一个武松如何只见说道军马众人那里") 3 txt=open("水浒传.txt","r").read() 4 words=lcut(txt) 5 counts={} 6 for word in words: 7 if len(word)==1: 8 continue 9 elif word =="及时雨" or word == "公明" or word =="哥哥" or word == "公明曰": 10 rword ="宋江" 11 elif word =="黑旋风" or word =="黑牛": 12 rword ="李逵" 13 elif word =="豹子头" or word == "林教头": 14 rword ="林冲" 15 elif word =="智多星" or word =="吴用曰": 16 rword ="吴用" 17 else: 18 rword=word 19 counts[word]=counts.get(word,0)+1 20 for word in excludes: 21 del(counts[word]) 22 items=list(counts.items()) 23 items.sort(key=lambda x:x[1],reverse=True) 24 for i in range(10): 25 word,count=items[i] 26 print("{0:<10}{1:>5}".format(word,count))
运行结果:(有些多余的词语未做好排除,代码仍需要改进)

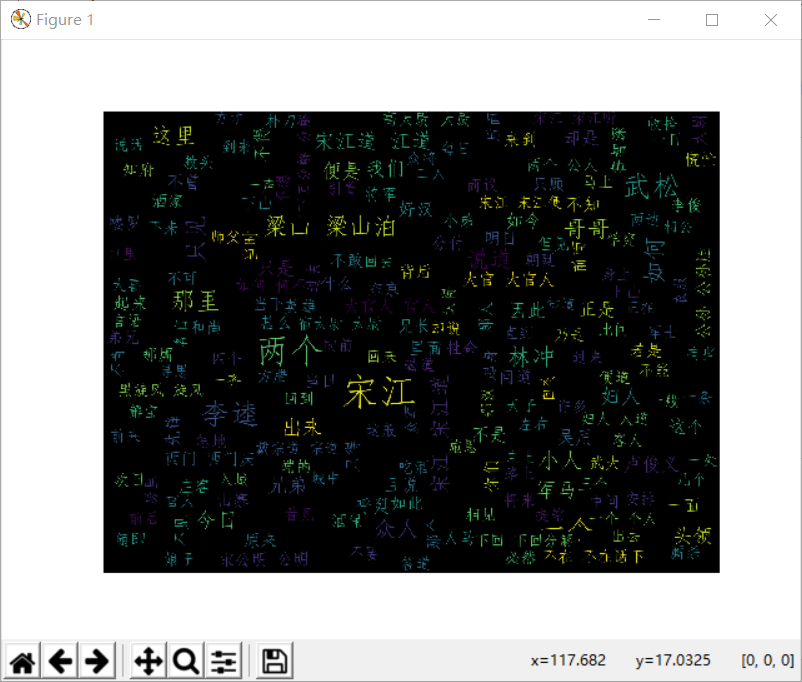
五.词云图(jieba库与wordcloud库的结合应用)
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from jieba import *
# 生成词云
def create_word_cloud(filename):
text = open("{}.txt".format(filename)).read()
font = 'C:\Windows\Fonts\simfang.ttf'
wordlist = cut(text, cut_all=True) # 结巴分词
wl = " ".join(wordlist)
# 设置词云
wc = WordCloud(
# 设置背景颜色
background_color="black",
# 设置最大显示的词云数
max_words=200,
# 这种字体都在电脑字体中,一般路径
font_path= font,
height=1200,
width=1600,
# 设置字体最大值
max_font_size=100,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=100,
)
myword = wc.generate(wl) # 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('img_book.png') # 把词云保存下
if __name__ == '__main__':
create_word_cloud('水浒传')
运行结果