归并排序的基本思路利用分治方法解决。
分治模式的每一层递归都有三个思路:
分解原问题为若干子问题,这些子问题是原问题的规模较小的实例。
解决这些子问题,递归地求解各子问题。然而,若子问题的规模足够小,则直接求解.
合并这些子问题的解成原问题的解。
归并排序算法完全遵循分治模式。直观上其操作如下:
分解:分解待排序的拧个元素的序列成各具n/2个元素的两个子序列。
解决:使用归并排序递归地排序两个子序列。
合并:合并两个已排序的子序列以产生已排序的答案.当待排序的序列长度为1时,递归“开始回升”,(也就是通常而言的递归出口) 在这种情况下不要做任何工作,
因为长度为1的每个序列都已排好序。
归并排序中 ‘’ 并‘’ 的伪码
1 MERGE(A, p, q, r) 2 n1 = q-p+l 3 n2 = r- q 4 let L[1. . n1+ 1] end R[1. . n2+ 1 ] be new arrays 5 for i = 1 to n1 6 L[i] = A[p + i - 1] 7 for j = l to n2 8 R[j] A[q + j] 9 L[n+ 1] = ∞ 10 R[n+ 1] = ∞ 11 i = 1 12 j = 1 13 for k = p to r 14 if L[i] <R[j] 15 A[k] = L[i] 16 i = i+1 17 else 18 A[k] = R[j] 19 j = j+1
过程MERGE的详细工作过程如下:
第1行计算子数组A[p..q]的长度n,第2行计算子数组A[q+1...r]的长度n2
在第3行,我们创建长度分别为,n1+1和n2+1的数组L和R(“左”和“右”),每个数组中额外的位置将保存哨兵.
第4~5行的for循环将子数组A[p , q ] 复制到L[1..n1],
第6~7行的for循环将子数组A[q+1..r]复制到R[1..n2],
第8~9行将哨兵放在数组L和R的末尾
第10—17行将在下图展示过程
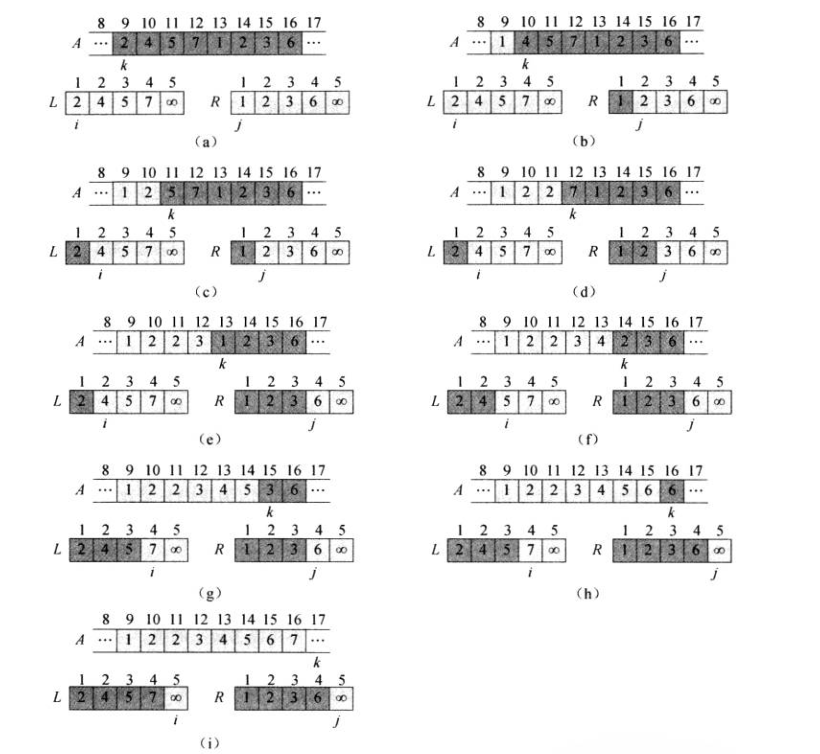
A中的浅阴影位置包禽它们的最终值.L和R中的浅阴影位置包含有待于被复制回A的值
现在我们可以把过程Merge作为归并排序算法中的一个子程序来用。下面的过程MERGE-SORT(A , p , r)排序子数组A[p..r]中的元素。若p≥r,则该子数组最多有一个元素,
所以已经排好序,否则,分解步骤简单地计算一个下标q,将A[p..r]分成两个子数组A[p..q]和A[q+l... r].前者包含[n/2]个元素,后者包含[n/2]个元素.
Merge_sort(A, p, r ) if p < r q = (p+r)/2 Merge_sort(A,p,q) Merge_sort(A,q+1,r) merge(A, p, q, r)
为了排序整个序列A = (A[1].A[2].…,A[n]),我们执行初始调用MERGE-SORT(A.1,A. Length),这里再次有A. length=n。
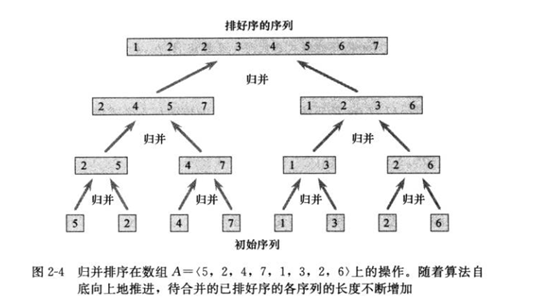
图2自底向上地说明了当n为2的幂时该过程的操作.算法由以下操作组成:合并只含1项的序列对形成长度为2的排好序的序列,
合并长度为2的序列对形成长度为4的排好序的序列,依此下去,直到长度为n/2的两个序列被合并最终形成长度为n的排好序的序列。
1 package com.hone.Merge; 2 3 public class MergeSort { 4 /* 5 * 定义一个函数包含三个参数,第一个参数表示传入的数组a,第二个参数表示临时储存的数组s 6 * k,表示当前需要合并的数组的原始长度 7 */ 8 public static void merge(int[] a ,int[] swap,int k){ 9 int n=a.length; 10 int m=0; 11 int i,j; 12 int s1,s2,e1,e2; //变量分别表示两个数组的首尾坐标 13 14 /* 15 * 定义两个数组坐标间的关系 16 */ 17 s1=0; 18 while(s1+k <= n-1){ 19 s2=s1+k; 20 e1=s2-1; 21 e2=(s2+k-1 <= n-1)?s2+k-1:n-1; 22 23 for ( i = s1,j=s2; i <=e1 && j<= e2 ; m++) { 24 if (a[i]<=a[j]) { 25 swap[m]=a[i]; 26 i++; 27 }else { 28 swap[m]=a[j]; 29 j++; 30 } 31 } 32 33 //如果出现了数组2中元素已经归并完毕,数组1仍然未归并完毕,直接将剩下的所有元素直接 34 //赋值给swap 35 while(i<=e1){ 36 swap[m]=a[i]; 37 i++; 38 m++; 39 } 40 41 //如果出现了数组1中元素已经归并完毕,数组2仍然未归并完毕,直接将剩下的所有元素直接 42 //赋值给swap 43 while(j<=e2){ 44 swap[m]=a[j]; 45 j++; 46 m++; 47 } 48 s1=e2+1; //形成收尾连接 49 } 50 51 //如果某些集合不能划分为两个数组,则直接全部复制给swap 52 for(i=s1; i<n; i++,m++) 53 swap[m]=a[i]; 54 55 } 56 57 //此时定义一个函数主要目的是为了提供合适的函数接口 58 public static void mergeSort(int[] a){ 59 int i; 60 int n=a.length; 61 int k=1; 62 int[] swap=new int[n]; 63 64 while(k < n){ 65 merge(a, swap, k); 66 67 68 for(i=0;i<n;i++) 69 a[i]=swap[i]; 70 71 k=2 * k; 72 } 73 } 74
对于任何的归并排序,归并的次数为n次,任何一次归并排序元素的递归次数都约为 Log n,所以,归并排序算法的时间复杂度是:O(nlogn)
空间复杂度:但是因为归并排序每次都需要用新的空间来存放n个数据元素,因此需要的空间复杂度为 O(n)
稳定性:稳定
特点:归并排序时间效率高,但是需要额外的储存空间,因此,归并函数适合于数据较少的排序。