扯闲篇
本篇开始之前,先来扯一些闲篇,举例上一次更新过去了接近两个月,说好了一周两更,为啥一直没有更新技术文章呢?
因为最近实在是太忙了,被突然抽去做了一个重构项目,说起来简单,翻译代码,将别的团队的 php 逻辑翻译成 Java 的代码。
但是由于时间紧,并且组织架构调整,熟悉原来业务的同学比较少,只能一边熟悉业务,一般翻译代码。
原来的项目的 php 代码(这里不关于语言的讨论,只是说代码风格问题),没有任何设计可言,同一个逻辑到处重复,简直是搬运一堆垃圾。
加了许多班,熬了许多夜,根本没有时间输出。

废话说完,下面进入正题,聊聊一个简单的 select 语句的执行过程。
select 之旅
建立简单的用户表,表结构及测试数据如下
create table user (
id int primary key,
name varchar(64)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into user values (1, "zhangsan");
insert into user values (2, "lisi");
insert into user values (3, "wangwu");
比如针对一个简单的用户表,如果想要查询 name = zhangsan 的用户信息,其中经过了哪些过程呢?
select * from user where name = 'zhangsan';
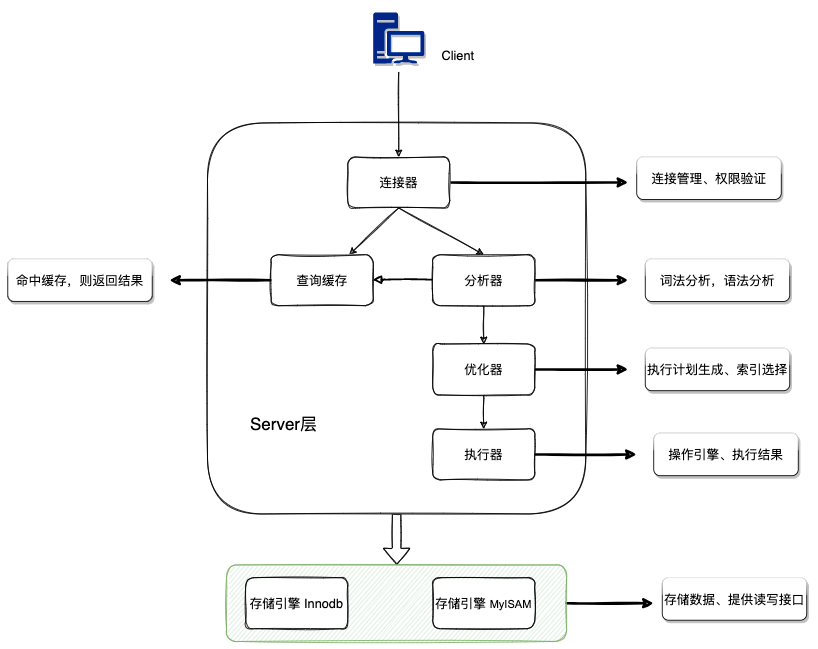
msyql 基本架构
说起 查询过程还需要介绍 mysql 的基本架构,整体架构如下:
其中主要分为 Server 层和存储引擎层。
Server 层包括连接器、查询缓存、分析器、优化器、执行器等。
第一步:连接
如果想要查询某个语句,首先得连接到 Mysql 服务器,这部分工作由 连接器完成,主要工作包括:建立连接、获取权限、维持和管理连接。
mysql -hip -pport -uusername -p
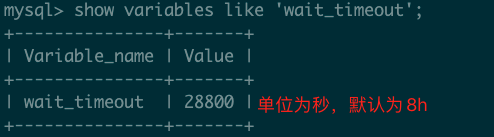
这里的连接是客户端与服务器之间的连接,也是一种TCP连接方式,同样要经过三次握手的过程,因此建立一次连接并不是一个简单的事儿,一般会设置一个比较合理的连接时间,在该时间范围内,即使没有任何的查询动作还是保持客户端与数据库服务器的连接。
这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。单位是s。可以通过如下命令查询该参数
show variables like 'wait_timeout';
第二步:缓存
可有可无的一步。
查询请求到来后,会先到查询缓存看看,之前是不是执行过这条语句。之前 执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。
key 是查询 的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
但是由于一旦对表做任何的更新操作,缓存都会失效。一般评价缓存好坏的标准是什么?缓存命中率,比如 redis ,如果设置缓存命中率很低,这个缓存是尤其不合理的。
因此,一般情况下,不建议使用缓存,费劲的缓存起来数据,使用情况很少,对于性能提升,根本没有什么作用。
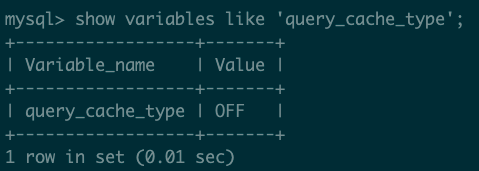
如何判断数据库是否开启了缓存呢?
show variables like 'query_cache_type';
我当前的 mysql 版本是 5.7.22,默认情况下,mysql 已经关闭了查询缓存。
第三步:分析器
如上图所以,我在分析器右边写上了,语法分析 + 词法分析。
何为词法分析?
大概就是将 语句翻译成机器能够识别的语言,识别出里面的字符串分别是什么,代表什么。
比如分析出 select 表示查询,update 表示更新,把字符 串 “user” 识别成“表名 user”,把字符串 “ID” 识别成 “列 ID” 。

那什么是语法分析呢?
根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法,就类似于英语中的语法一样。
还记得初一的英语,当时对于一个简单的语句,比如
I am a boy.
如果你写成
I is a boy.
老师会告诉你,你这样语法是错误的。
对于 mysql 也一样,如果是输入如下查询语句,将 from 手误写成了 form,mysql 肯定也会提醒你的。
select * form user;

如果下次你再见到类似的提示,不用看了,肯定是你哪个 sql 没有写对。
第四步:优化器
根据名字就可以判断,这一步是 Mysql告诉服务器,如何能够更加快速的执行语句。如果有多个索引,判断使用哪个索引,或者在一个语句有多表关联 (join) 的时候,决定各个表的连接顺序。
优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。
第五步:执行器
听名字可以判断,这一步是一个没得灵魂的工具人角色,就是纯粹的执行语句。
还是回到最初的语句
select * from user where name = 'zhangsan';
-
调用 InnoDB 引擎接口取这个表的第一行,判断 name 是否是zhangsan,如果不是则跳过,如 果是则将这行存在结果集中;
-
调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
-
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
由于 name 上没有添加索引,所以会全表扫描所有的行,一行一行做判断,这一点我们可以通过慢查询日志看到踪迹
可以看到整个过程,扫描了3行,有一行满足要求。

如果 name 有索引呢?
这里我们新增加一个索引
ALTER TABLE `user` ADD INDEX name_index ( `name` )
-
调用 InnoDB 引擎去name索引树查询 name = zhangsan,查找对应的主键值,得到id = 1,拿着主键id去 主键索引中查询 id=1 所在的行。
-
重复相同的判断逻辑,直到取到这个表的最后一行。
-
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
可以看到加上索引之后,其实只是扫描了一行。

我在测试的时候发现了有意思的事情,这里加了索引花费的查询时间竟然比未加索引查询时间更长。不是说加索引能够加快查询效率吗?
其实这里主要是因为数据量太少了,而且加了 name 字段索引之后,还需要去主键索引树上查找某一行【这个过程为回表】,速度肯定比直接从三行中挑选一行更慢。
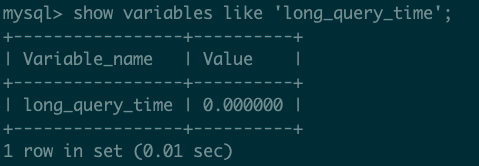
我这里将慢查询日志打开,并且设置慢查询日志的阈值为0s,便于观察记录。
总结
这里主要介绍了 日常开发中使用最多的 select 的查询过程,其实主要是了解整个 mysql 的架构。
文中引出了索引的东西,其实这个概念大部分人并不陌生,但是可能对于 索引、主键索引、普通索引、回表等概念不是很熟悉,这里只是简单介绍,后续再和大家一起深入探讨。