Java高级特性流库_初体验
面对结果编程
在编程里, 有两种编程方式, 一种是面对过程编程, 一种是面对结果编程. 两者区别如下
面向过程编程
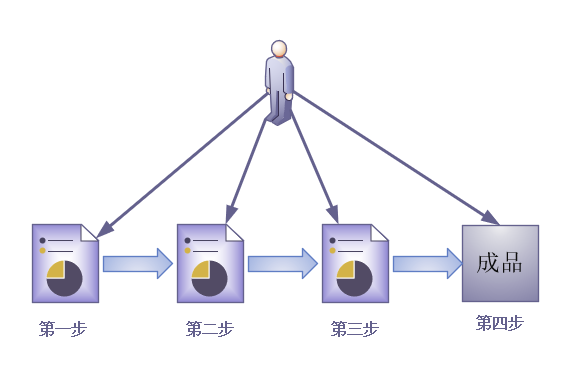
面向过程编程需要编程程序让程序依次执行得到自己想要的结构
面向结果编程
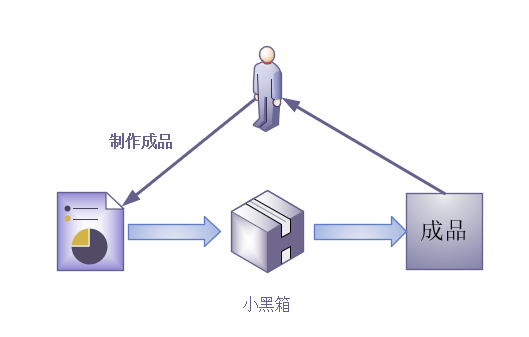
流库带给我们的好处就是我们不需要知道过程, 只需要提供我们的需要, 具体怎么做由流库内部实现
1. 迭代到流代码演示
流库正如其名所示, 它处理的是大量元素.
这里可以将流库比作一个水管, 流库中的许多函数比作水龙头, 函数成立, 水龙头便打开让水流动, 函数不成立, 水龙头关闭, 锁住水.
public class FlowDemo2 {
public static void main(String[] args) throws IOException {
int count = 0;
// 读取文本文件, 其中是一段文章
String s = new String(Files.readAllBytes(Paths.get("src","a.txt")));
String[] split = s.split("\n");
// 面向过程编程 统计段落长度大于90的数量
for (String s1 : split){
if(s1.length() > 90) count++;
}
// 面向结果编程 统计段落长度大于90的数量
List<String> list = Arrays.asList(split);
System.out.println(list.stream().filter(w -> w.length() > 90).count());
// 另一种数组转流的方式
// Stream<String> stream = Arrays.stream(split);
// System.out.println(stream);
// System.out.println(stream.filter(w -> w.length() > 90)
// .count());
// System.out.println(count);
}
}
结果一致, 都为6.
2. 流的优点
- 更加简洁明了
- 能够链式操作( 每次返回的数据类型都是流 )
- 流不会存储元素, 节约内存
- 流的操作不会修改数据源
- 我的理解: 流是单向的, 只会单方向流动改变, 不会改变之前的状态, 流动过了就过了, 不会再回来
3. 创建流的方式
根据流的长度可以分为无限流和有限长度的流
Java中有大量API可以产生流, 假如有方法可以返回大量数据, 那么就可以查查文档看, 是否有转换为流的方法.
Stream接口生成有限长度的流的方式
// 第一种
// Stream.of(可变长参数数组)
int[] arr1 = {2, 34, 6, 8, 9, 19};
int[] arr2 = {2, 4, 5};
Stream<int[]> stream1 = Stream.of(arr1, arr2);
System.out.println(stream1.getClass());
// 第二种
int[] arr3 = {2, 34, 6, 8, 9, 19};
// 截取数组部分, 从1到2, 不包括结束
IntStream stream = Arrays.stream(arr3, 1, 3);
System.out.println(stream.sum());
// 创建空流
Stream.empty()
Stream接口生成无限流的方法
// 第三种, 创建无限流之generate
Stream<Integer> generate = Stream.generate(() -> 1);
generate.filter(w -> {
System.out.println(w);
return w>0;
});
// Stream.generate(参数为一个函数, 返回值必须是一个数,
// 该方法被不停调用并将返回值赋予流成为水流中的一员)
Stream<Double> generate1 = Stream.generate(Math::random);
// 必须有count, 否则在filter中的sout失效
generate1.filter((w) -> {
System.out.println(w);
return w>0.5;
}).count();
// 创建无限流之iterate
// Stream.iterate(种子参数, 迭代函数), 种子参数表示迭代时的初始值, 迭代函数表示每次
// 执行函数修改上一次迭代函数返回的值, 再作为本次函数的返回值返回,用下面的例子
// 种子为0, 每次基于上次的结果值加1, 流中存储的数据为0, 1, 2, 3, 4 ...
// 问题: 每次停止运行后,再次运行的迭代函数是基于上次结束的返回值, 难道是有缓存,
// 停止时打印6002, 再次运行时从6003开始
Stream<Integer> iterate = Stream.iterate(0, n -> n += 1);
iterate.filter((w) -> {
System.out.println(w);
return w>0.5;
}).count();
iterate.forEach(w -> System.out.println(w));
热烈欢迎大家看下, 一起解决上述程序最后提出的问题
总结
对流的操作加上 Lambda 表达式能够使程序更加简洁易懂, 也正是由于简洁, 不易将这种类型的程序内容书写太多, 否则过了一段时间, 自己都看不懂这段代码.
在后续对大量元素的处理, 可以优先考虑流, 而非集合