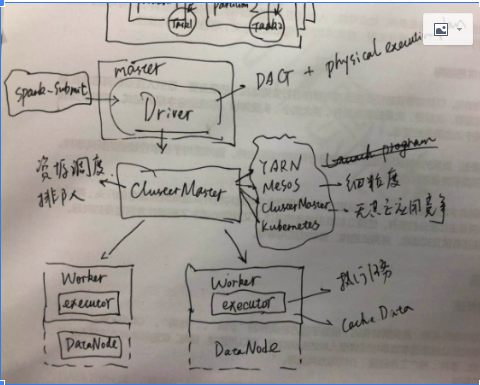
Driver,主要的职责是生成DAG以及生成物理执行计划(Physical Execution Plan);Application,Job以及Stage都是在这个组建中生成的;
ClusterMaster,包括五类:
1)Apache YARN,Hadoop原生资源调度框架
2)Apache Mesos,有粗粒度(coarse-grained,fine-grained),粗粒度资源一旦分配就不再改变;细粒度则是根据应用对于资源的需要动态分配;前者执行速度回比较快,但是有资源滥用的可能;后者执行速度可能会受影响,但是资源共享可以达到最大;
3)Amazon EC2
4)Stand alone Cluster Manager,Spark自带的Cluster Manager,同样提供coarse-grained和fine-grained对于资源的管理。
5)Kubernetes
Executor,主要的职责是执行任务以及缓存数据;在Spark定义的对象中Task就是在这个点上面执行的。
在描述Spark部署的时候,要分清楚角色和组件;master,worker是节点的角色,对应的driver以及executor是组件。
对于Cluster的几点建议:
1)如果是单独spark来使用所有的共享资源;stand alone cluster manager就可以;
2)如果是多个应用来共享资源(比如Hive),那么采用YARN或者是Mesos;
3)如果对于资源比较敏感,请求多,资源相对少,采用Mesos(的细粒度模式);
4)Executor所在的Worker节点最好和Hdfs部署一致;这样取用数据方便,可以有效减少shuffle。