combineBykey关键是要明白里面的三个函数:
1. 当某个key第一次出现的时候,走的是第一个函数(createCombin);A function that creates a combiner. In the aggregateByKey function the first argument was simply an initial zero value. In combineByKey we provide a function that will accept our current value as a parameter and return our new value that will be merged with addtional values.
2. 当某个keyN次出现(N > 1)的时候,将会走第二个函数;The second function is a merging function that takes a value and merges/combines it into the previously collecte value(s).
3. 第三个函数是发生shuffle的时候,数据汇总的处理;处理逻辑一般和第二个函数一致;两个参数是来自于两个区的待累计处理参数。The third function combines the merged values together. Basically this function takes the new values produced at the partition level and combines them until we end up with one singular value.
突然来看这个combineByKey有些唐突,不过你要明白combine含义就是合并,可能会好理解.combinebyKey很多时候会和map做接续,combine数据后,在map对于数据进行二次处理,比如下面的例子里面的求平均值;combineByKey做得是累加,当需要对累加值做后续处理的时候,map就出场了;另外,combinByKey其实可以写成mapValues+reduceByKey;mapValues + reduceByKey是两轮便利,combineByKey其实是一轮便利(不算第三个函数)。但是两者只是类似,却不相同;
1.mapValues: 当一个遍历每个元素的时候,处理,参数是当前待处理元素;
2.reduceByKey,是遍历一遍之后,第二遍遍历处理,一般是做累计逻辑处理,第一个参数就是历史累计值,第二个参数是当前待处理元素;
代码如下:
1 object Main { 2 def main(args: Array[String]) { 3 val scores = List( 4 ScoreDetail("xiaoming", "Math", 98), 5 ScoreDetail("xiaoming", "English", 88), 6 ScoreDetail("wangwu", "Math", 75), 7 ScoreDetail("wangwu", "English", 78), 8 ScoreDetail("lihua", "Math", 90), 9 ScoreDetail("lihua", "English", 80), 10 ScoreDetail("zhangsan", "Math", 91), 11 ScoreDetail("zhangsan", "English", 80)) 12 13 var sparkConf = new SparkConf 14 //sparkConf.setMaster("yarn-client") 15 sparkConf.setAppName("app") 16 var sc = new SparkContext(sparkConf) 17 //val scoresWithKey = for( i<-scores) yield (i.studentName, i) 18 val scoresWithKey = scores.map(score => (score.studentName, score)) 19 var scoresWithKeyRDD = sc.parallelize(scoresWithKey).partitionBy(new HashPartitioner(3)).cache 20 scoresWithKeyRDD.foreachPartition(partition => { 21 //println("***** partion.length: " + partition.size + "************") 22 while (partition.hasNext) { 23 val score = partition.next(); 24 println("name: " + score._1 + "; id: " + score._2.score) 25 } 26 }) 27 28 val avg = scoresWithKeyRDD.combineByKey( 29 (x: ScoreDetail) => { 30 println("score:" + x.score + "name: " + x.studentName) 31 (x.score, 1)}, 32 (acc: (Float, Int), x: ScoreDetail) =>{ 33 println("second ground:" + x.score + "name: " + x.studentName) 34 (acc._1 + x.score, acc._2 + 1) 35 }, 36 (acc1: (Float, Int), acc2: (Float, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) 37 ).map({ case (key, value) => (key, value._1 / value._2) }) 38 /* 39 val avg = scoresWithKeyRDD.mapValues(value => (value.score, 1)) 40 .reduceByKey((acc, item) => (acc._1 + item._1, acc._2 + item._2)) 41 //.map(item => (item, item._2._1 / item._2._2) 42 .map({ case (key, value) => (key, value._1 / value._2) }) 43 */ 44 avg.collect.foreach(println) 45 scoresWithKeyRDD.unpersist(true) 46 } 47 }
combineByKey的处理逻辑通过日志可以看到:
1 score:98.0name: xiaoming 2 second ground:88.0name: xiaoming 3 score:90.0name: lihua 4 second ground:80.0name: lihua 5 score:91.0name: zhangsan 6 second ground:80.0name: zhangsan
每个key只是走一次第一个函数;当同一个key第n次出现(n > 1)的时候,将会走第二个函数;这个和mapValues将会过遍历一遍,keyByValues再过一遍的逻辑还是不同的。
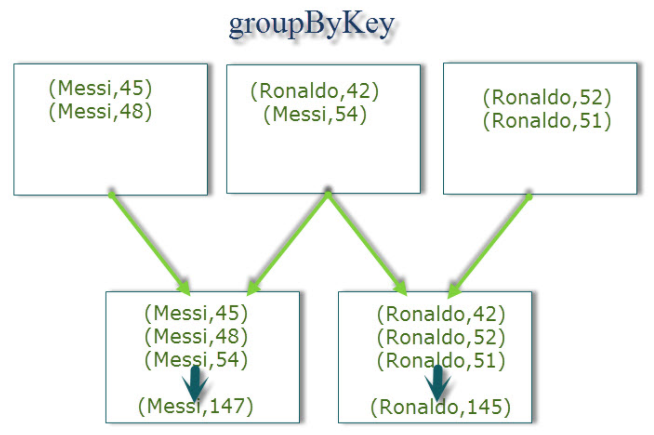
combineByKey的一个老对手是groupbyKey,这个说法其实不准确,reduceByKey才是groupByKey的老对手;因为无论是reduceByKey还是groupByKey,其实底层都是调用combinByKey;但是groupByKey将会导致大量的shuffle,因为groupByKey的实现逻辑是将各个分区的数据原封不动的shuffle到reduce机器,由reduce机器进行合并处理,见下图:
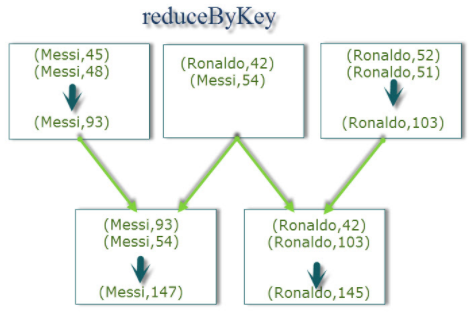
reduceByKey则是先将各个分区的数据进行合并(计算)处理后在shuffle到reducer机器;这样严重的减轻了数据传输的量。