基于距离的norm1和norm2
所谓正则化,就是在损失函数中增加范数,那么老调重弹一下,所谓范数是指空间向量的大小距离之和,那么范数有值单一向量而言的范数,其实所谓单点向量其实是指指定向量到原点的距离。
d = Σ||xi||·
还有针对两个向量求距离的范数;那么作为距离,最常用到的就是马哈顿距离,这个距离也被称之为norm 1:
对于两个向量norm1的应用有两个:
SAD(sum of absolution,绝对偏差和)= ||x1 - x2|| = Σ|x1 - x2|
MAE(mean-absolution error,平均绝对误差)= (1/n)*Σ|x1 - x2|
其次是欧式距离,这个距离也被称之为norm 2,对于单向量而言:
d = [Σ(xi²)] ^ 0.5
对于两个向量的应用如下:
SSD(sum of squared difference) = ||x1 - x2||² = Σ(x1 - x2)²
MSE(mean-squared error)=(1/n)*||x1-x2||² = (1/n)*Σ(x1 - x2)²
L1和L2
在有监督学习中,我们一般都是基于损失函数最小的优化问题,来求解模型(中的ω)。
J = Σ(hθ(xi) - yi)²
拿到了原始数据一般我们都会做两类事情,训练前进行特征选择,那些对于应变量的影响小的特征直接过滤掉,这种行为会因为减少了参数了个数,而使得模型更加简洁,从而增加了"可解释性";另外一件事情就是训练一波模型之后,会有过拟合情况,需要对模型进行调优。
对于第一类操作,可以通过为损失函数增加norm1子项来实现,这个增加的子项行为被称之为L1正则化,添加L1正则项之后的损失函数称之为Lass回归其中norm1的子项是各个参数之和:

这个其实是个优化问题,为了能够保证J取到最小值,需要满足Σ||θ|| < λ,这里如果λ指定的足够小,那么就可能会使得部分参数值是0
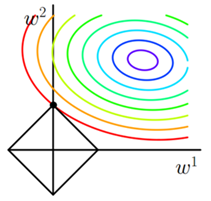
我们直观的可以通过上面这张图来理解一下,先讨论一个简单的场景,只有两个参数ω1和ω2:彩色部分是Jθ的梯度下降图形,黑色棱形则是L = λ*Σ||θ||部分,正常的优化值是彩色部分中心点(紫色圈部分),有了黑色棱形部分后,因为ω的值一定是要在两个图形都包含区域内,满足这个条件,所以是会将(ω1, ω2)向原点部分拉。
从图上可以看到大概率梯度下降的区域是会和L部分的顶点部分相交,因为棱形的顶点是突出部分;这就意味着大概率有一个参数值为0;之所以选择这个突出的交点是最优化点,是因为在相接触的第一个点上面,棱形部分所代表的范数最小。如果是多维场景,也会有更多这样的角(其中一个维度参数值为0),所以L1很容易获取系数矩阵(在求解最优过程中,部分参数为0)。
对于第二类操作,可以通过为损失函数增加一个norm2子项来实现,称之为L2正则化:

类似的,要满足Σ||ω|| < λ。通过增加L2正则化,可以实现参数变小,从而解决过拟合问题。为什么参数变小会解决过拟合呢?这是因为如果参数很大,那么自变量一个很小的变化也会在应变量上面放大很大,这就容易导致过拟合;反之如果模型的参数很小,那么及时自变量有变化,那么对于应变量的影响也是很小,这样模型变化比较缓慢,不容易过拟合,这种自变量变化缓慢影响应变量的情形也被称之为"抗干扰能力强"(及时有异常信号,也不会导致过大偏差)。
还是用图形的方式来进行理解(坐标轴的ω等价于θ):
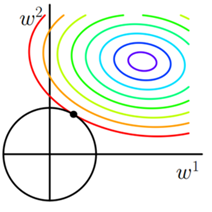
L此时的图形是一个圆,从图像上可以看出来此时交点是x轴Y轴的几率就很小了,因为没有"突出"部分;于是L2只是减小参数值而不是将某个ω设置为0,而只是将(ω1, ω2)向原点方向拉,进而实现了ω1和ω2同时变小,仅仅变小。
L2和L1的功效背后的算法
那么是如何实现L2减小参数?

其中hθ(x)=θ0x0+θ1x1+⋯+θnxn

这里稍微解释一下,hθ(xi) - yi是平方项,对θj进行求导的时候,只是其中一项参与求导,所以其中一项hθ(xi) - yi被保留下来;另外一项hθ展开后公式上面已经描述,对θj求导之后,只有θj项对应xj被保留下来(θj被导数约分约去了)。
上式就是梯度值,基于损失函数求解θ(α是学习率):
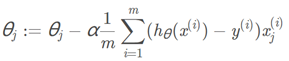
基于包含了Lasso回归的求解θ:

两者后面部分相同,只是差在前面部分,我们看到包含lasso的公式中,θj乘以一个小于1的数,所以θj'是小于θj的,至于小多少取决于你设置的λ到底多大,λ越大,θ越小。
岭回归还有一个好处就是,原始损失函数求解过程中,使用最小二乘法进行计算的时候有一个限制(如果是梯度下降则没有此限制),就是必须要有逆矩阵,充分条件就是满足样本数大于特征数,但是有的时候并不满足,此时就需要岭回归来进行变形计算。
类似的我们来计算一下L1下的θj,注意因为L2是平方,L部分求导的时候回留下一个θj,于是会有上面的公式中,θj的右侧θ会乘以一个小于1的部分(1-αλ/m),但是对于L1都是一次方,所以L部分求导数的时候基本全军覆没,只是||θj||1求导之后为1。所以:
θj = θj - D - α*λ*sign(θ)/n(D是J0的求导部分,这里不赘述了,可以参见上面公式)
这里sign(θ)代表参数θ的符号。
通过L1和L2的公式,我们可以看出来L1的求导公式,我们可以假设D部分都是非常小的,因为梯度下降设计的就是多次迭代完成;L2的参数值为0的概率很小,但是L1的参数如果λ足够大,θj(参数)是很有可能为0的。
L1,L2特性比较
L1正则化又称之为Least Absolution Deviation Regression(下图表格右侧),L2称之为Least Squares Regeression(下图表格左侧)
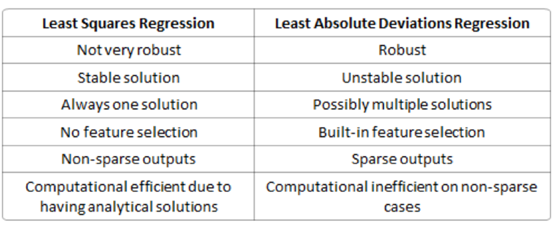
robust,健壮性,即对于异常点的抵抗力,L1居于很强的抵抗力,但是L2并不强,这个其实也和他的平方项有关系,会放大异常值。
stable,稳定性,因为L1是直线的,L2是曲线的;所以在数据集发生变化的时候,因为直来直去,L1的变化将会非常剧烈(比如斜率发生变化,进而b值发生变化),但是L2因为是曲线,他的曲线变化将会更加平滑,所以变化相对较小。
analytical solution:解析解,L2有解析解(最小二乘法),所以计算效率很高,L1没有解析解,所以计算效率底下。
求解过程
我们就拿L1来举例子,L2类似。很多时候添加正则项,被称之为添加惩罚项,为什么叫"惩罚项"呢?就是因为正则化部分其实是整个式子优化约束,比如L1的正则化等价于下面的约束问题:
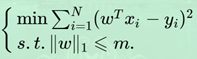
此时问题就转化为了带约束条件的凸优化问题,下面就是凸优化常用解决方案,写出拉格朗日函数:

设ω*和λ*是原问题最优解,则根据KKT条件得有:
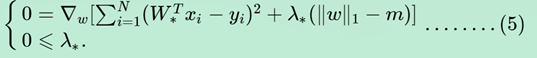
后面就可以根据凸优化的算法进行求解λ和ω。
关于L1,L2调优
首先调优调的是系数λ,而且是要结合学习率来进行调优,首先设置λ = 0,即没有正则项的场景下,进行调优,获取比较优的learning rate,然后再尝试为λ赋值为1,此时是一个基准值,然后扩大10倍和缩小10倍,看看效果,然后确定到底是沿着放大的方向走还是沿着缩小的方向走。
对于L1而言,λ越大,其实越容易让θ趋于0(这点可以从公式中得到验证);对于L2而言,λ越大,θ的衰减也是越快的(相当于步长调大了);从图形上来理解就是λ越大,那个圆的面积越小,那么作为最优点的相交点也就越靠近约点,参数值越小,可以理解为"惩罚"的也是越大。
附录
L1,L2标准化
标准化和正则化基本没有半毛钱关系。
X' = X/||X||
具体实现:
X' = X/ norm1(X)
X' = X/ norm2(X)
L2为什么叫岭回归
L2正则化也被称之为岭回归(Ridge Regression),为什么叫岭回归?看一下下面的基于矩阵的求参公式:

第一个公式正常损失函数求参公式,第二个公式是添加了L2的公式。我们看到多了一个λ*I的部分,这里I就是对角线矩阵,只有对角线是1,其他都是0,就像一个山岭一样。
另外,我们可以从下面的图中看出一些端倪,左侧的是原始没有添加正则项的图,我们看到它其实最小值是一条直线,解空间很大;右侧则是添加了正则项(惩罚项)之后,图形变成了类似于漏斗的形状,向山岭一样(这个解释是不是有点牵强?),这样求解将会更加简单(为什么会更加简单)

参考
关于θj的计算部分参考如下两篇文章
https://blog.csdn.net/jinping_shi/article/details/52433975
https://cloud.tencent.com/developer/article/1011153
https://blog.csdn.net/zouxy09/article/details/24971995 非常详细的数据角度解释L1,L2有时间应该细看
下面两篇文章对于L1,L2特性分析有贡献
https://blog.csdn.net/w5688414/article/details/78046960
https://www.cnblogs.com/jclian91/p/9824310.html
L1,L2凸优化部分以及调优部分参考下面两篇文章
https://www.cnblogs.com/zingp/p/10375691.html
https://blog.csdn.net/jinping_shi/article/details/52433975
https://blog.csdn.net/bitcarmanlee/article/details/51932055
https://www.cnblogs.com/skyfsm/p/8456968.html 对于岭回归的另外一种解释,虽然疑点很多。
关于经验风险,结构风险以及预期风险的介绍
https://blog.csdn.net/liyajuan521/article/details/44565269
https://www.jianshu.com/p/903e35e1c95a
