1. 下载hadoop和jdk安装包到指定目录,并安装java环境。

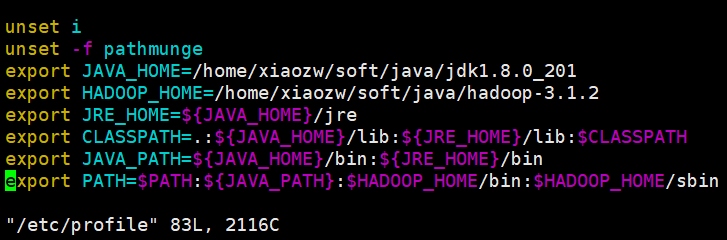
2.解压hadoop到指定目录,配置环境变量。vim /etc/profile
export JAVA_HOME=/home/xiaozw/soft/java/jdk1.8.0_201
export HADOOP_HOME=/home/xiaozw/soft/java/hadoop-3.1.2
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
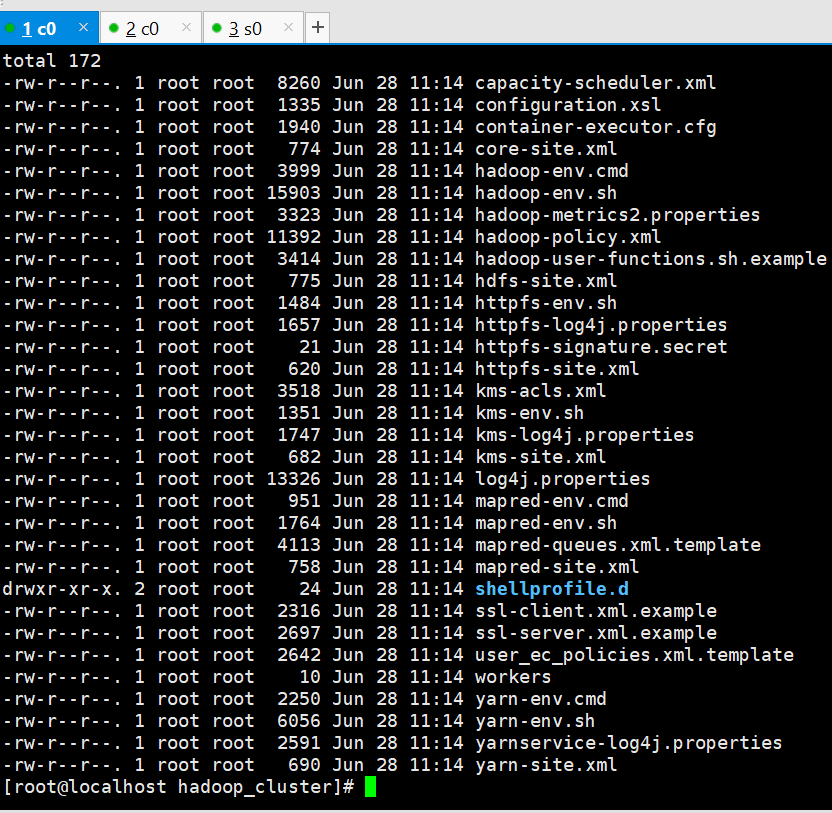
3. 复制配置文件到新文件夹,备份用。
cp -r hadoop hadoop_cluster
重命名配置文件。
mv hadoop hadoop_bak
创建软链接
ln -s hadoop hadoop_cluster

修改配置文件,路径:soft/java/hadoop-3.1.2/etc/hadoop_cluster/
分别修改
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://c0:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/xiaozw/soft/tmp/hadoop-${user.name}</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>c3:9868</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.recourcemanager.hostname</name>
<value>c3</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
修改hadoop_cluster/hadoop-env.sh
export JAVA_HOME=/home/xiaozw/soft/java/jdk1.8.0_201

4. 克隆多台机器。修改hostname
分别修改每台机器。
vim /etc/hostname
c0
每台机器都一样配置。
vim /etc/hosts
192.168.132.143 c0
192.168.132.144 c1
192.168.132.145 c2
192.168.132.146 c3
4台服务器需要ssh免密码登录。
设置2台服务器为data-node。进入配置文件目录:
cd soft/java/hadoop-3.1.2/etc/hadoop_cluster/
sudo vim workers
新建脚本方便拷贝文件到多台服务器上面。
bat.sh
for((i=1;i<=3;i++))
{
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/hadoop-env.sh xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/hadoop-env.sh
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/hdfs-site.xml xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/hdfs-site.xml
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/core-site.xml xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/core-site.xml
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/mapred-site.xml xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/mapred-site.xml
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/yarn-site.xml xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/yarn-site.xml
scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/workers xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/workers
ssh xiaozw@c$i rm -rf /home/xiaozw/soft/tmp/
#scp /etc/hosts xiaozw@c$i:/etc/hosts
}
新增权限
chmod a+x bat.sh

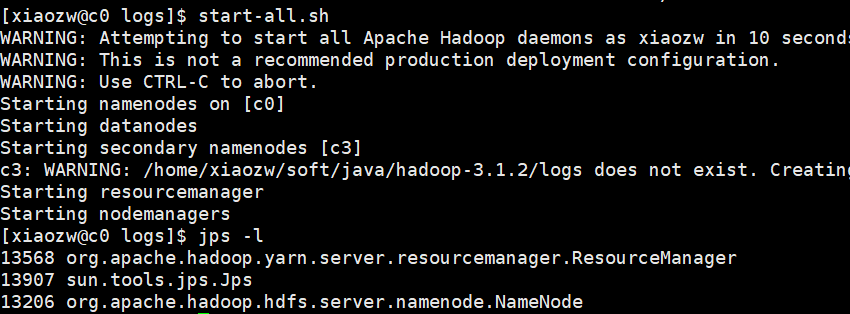
5. 启动hadoop
start-all.sh
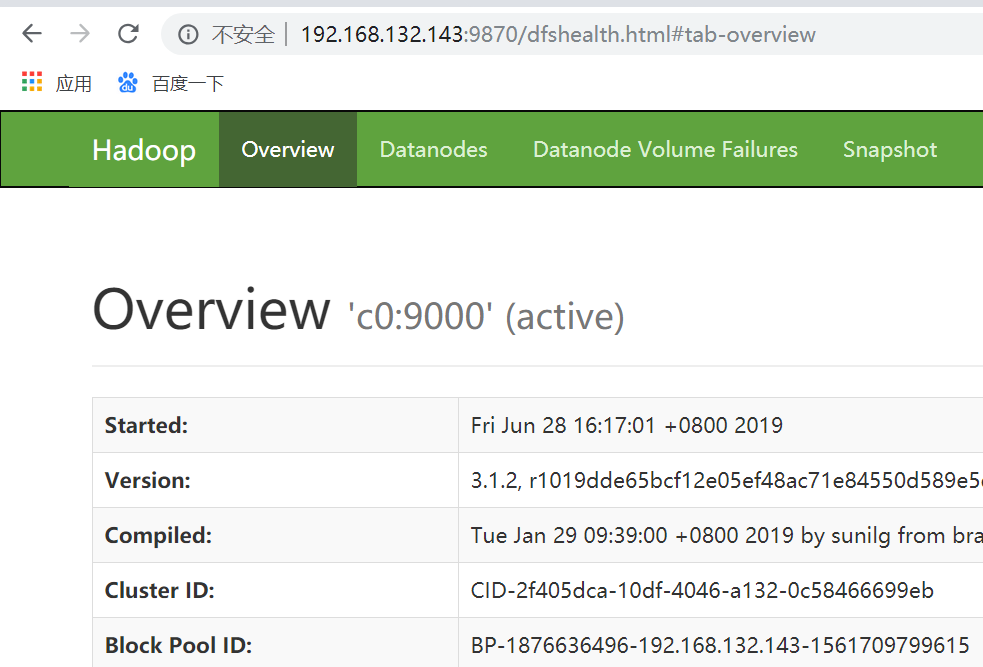
http://192.168.132.143:9870/dfshealth.html#tab-overview
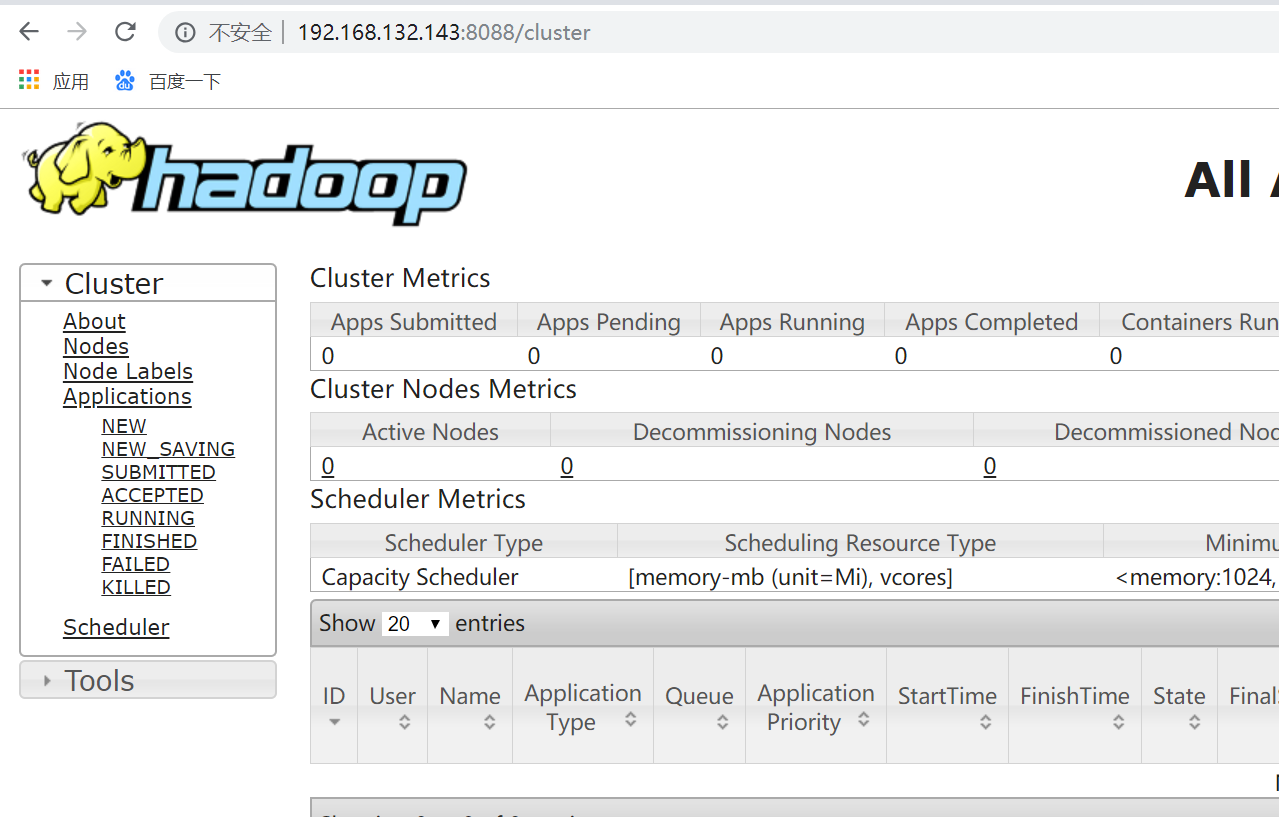
http://192.168.132.143:8088/cluster
统计最高温度demo:
public static void main(String[] args) { try { log.info("开始。。。"); Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); // if (otherArgs.length != 2) { // System.err.println("Usage: wordcount "); // System.exit(2); // } Job job = new Job(conf, "max tempperature"); //运行的jar //job.setJarByClass(MaxTemperature2.class); job.setJar("/home/xiaozw/soft/download/demo-0.0.1-SNAPSHOT.jar"); FileSystem fs=FileSystem.get(conf); //如果输出路径存在,删除。 Path outDir=new Path("/home/xiaozw/soft/hadoop-data/out"); if(fs.exists(outDir)){ fs.delete(outDir,true); } Path tmpDir=new Path("/home/xiaozw/soft/tmp"); if(fs.exists(tmpDir)){ fs.delete(tmpDir,true); } //job执行作业时输入和输出文件的路径 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //指定自定义的Mapper和Reducer作为两个阶段的任务处理类 job.setMapperClass(TempMapper.class); job.setReducerClass(TempReduce.class); //设置最后输出结果的Key和Value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //提交作业并等待它完成 System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { e.printStackTrace(); } log.info("结束。。。"); }
package com.example.demo; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class TempMapper extends Mapper<Object, Text, Text, IntWritable>{ public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String lineValue = value.toString(); String year = lineValue.substring(0, 4); int temperature = Integer.parseInt(lineValue.substring(8)); context.write(new Text(year), new IntWritable(temperature)); } }
package com.example.demo; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class TempReduce extends Reducer<Text, IntWritable, Text, IntWritable>{ public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxTemp = Integer.MIN_VALUE; for(IntWritable value : values){ maxTemp = Math.max(maxTemp, value.get()); } context.write(key, new IntWritable(maxTemp)); } }
网盘文件和代码下载地址:
链接:https://pan.baidu.com/s/14wdv5CTXzw_0pmDisCa0uA
提取码:auao