下图是request_time。

下图是upstream_response_time.

精准的描述就是:
request_time是从接收到客户端的第一个字节开始,到把所有的响应数据都发送完为止。
upstream_response_time是从与后端建立TCP连接开始到接收完响应数据并关闭连接为止。
所以,request_time会大于等于upstream_response_time。
比如,36.110.43.106 - - [12/Dec/2019:17:04:26 +0800] "GET /js/chunk-vendors.03f0a278.js HTTP/1.1" 200 2994930 "http://115.29.150.110/" "-" - - 5.325
日志格式为:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" '
'$upstream_addr $upstream_response_time '
'$request_time';
这就显然5.325ms都是消耗在nginx自己身上的。后端都没用时间。 js是从nginx上取的。
36.110.43.106 - - [12/Dec/2019:17:06:18 +0800] "POST /api/login HTTP/1.1" 404 132 "http://115.29.150.110/" "-" 172.31.184.226:8700 0.027 0.027
像这种的就是request和response时间一样。那nginx上就没消耗时间。都在后端消耗的时间。
前言
最近分析服务器性能,考虑到nginx在前面做反向代理,这里查一下nginx日志来反应服务器处理时间的问题。
1、Nginx内时间定义
1.1、request_time
单位为秒。
官网描述:request processing time in seconds with a milliseconds resolution; time elapsed between the first bytes were read from the client and the log write after the last bytes were sent to the client。
指的就是从接受用户请求的第一个字节到发送完响应数据的时间,即$request_time包括接收客户端请求数据的时间、后端程序响应的时间、发送响应数据给客户端的时间(不包含写日志的时间)。
官方文档:http://nginx.org/en/docs/http/ngx_http_log_module.html
1.2、upstream_response_time
单位为秒。
官网描述:keeps time spent on receiving the response from the upstream server; the time is kept in seconds with millisecond resolution. Times of several responses are separated by commas and colons like addresses in the $upstream_addr variable.。
是指从Nginx向后端建立连接开始到接受完数据然后关闭连接为止的时间。
从上面的描述可以看出,$request_time肯定比$upstream_response_time值大;尤其是在客户端采用POST方式提交较大的数据,响应体比较大的时候。在客户端网络条件差的时候,$request_time还会被放大。
官方文档:http://nginx.org/en/docs/http/ngx_http_upstream_module.html
除了上述的request_time和upstream_response_time比较常用,在新的Nginx版本中对整个请求各个处理阶段的耗时做了近一步的细分:
1.3 $upstream_connect_time(1.9.1):
单位为秒。
keeps time spent on establishing a connection with the upstream server (1.9.1); the time is kept in seconds with millisecond resolution. In case of SSL, includes time spent on handshake. Times of several connections are separated by commas and colons like addresses in the $upstream_addr variable.
跟后端server建立连接的时间,如果是到后端使用了加密的协议,该时间将包括握手的时间。
1.4 $upstream_header_time(1.7.10):
单位为秒。
keeps time spent on receiving the response header from the upstream server (1.7.10); the time is kept in seconds with millisecond resolution. Times of several responses are separated by commas and colons like addresses in the $upstream_addr variable.
接收后端server响应头的时间。
2、场景
2.1 流程说明
如果把整个过程补充起来的话 应该是:
[1用户请求][2建立 Nginx 连接][3发送响应][4接收响应][5关闭 Nginx 连接]
那么 upstream_response_time 就是 2+3+4+5
但是 一般这里面可以认为 [5关闭 Nginx 连接] 的耗时接近 0
所以 upstream_response_time 实际上就是 2+3+4
而 request_time 是 1+2+3+4
二者之间相差的就是 [1用户请求]的时间。
来个网上的图说明情况:
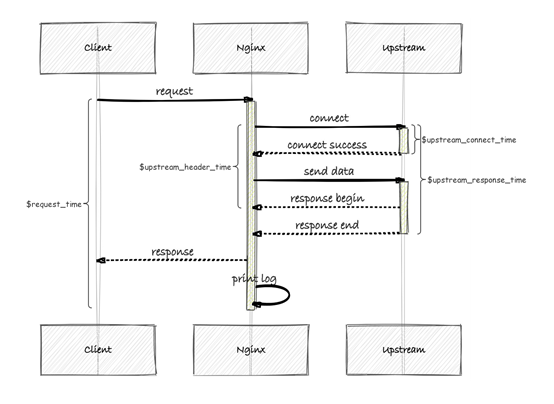
从上图中我们不难得出如下结论
程序真正的运行时间 = $upstream_header_time - $upstream_connect_time
$request_time 中包含了数据返回时间
$request_time 中包含了日志打印的时间
2.2 场景举例
2.2.1 场景:nginx日志出现大量超时报警,这个时候发现$upstream_header_time正常,但是$request_time、$upstream_response_time很大
分析:根据上面的示意图,这个时候便反映出是上游程序执行较慢、或发送数据量大,需要排查执行程序的相关慢日志
2.2.2 场景:同样是ngxin日志出现大量超时报警,这个时候发现$request_time很大,但是$upstream_response_time正常
分析:$upstream_response_time正常,说明程序执行完毕且正常返回,那么这个时候需要验证是数据返回过慢还是日志打印出现了阻塞。
原因:
数据返回慢可以通过抓包分析,通常来说是用户网络原因引起的;
日志打印出现阻塞,可能是机器io出现了问题,这个一般很容易发现;
还有可能是nginx配置了相关参数,导致了延迟关闭,这里只要根据问题现象一步一步排查即可。
也可能返回给客户端是https,大数据加解密耗时
解决方法:
把你的服务器放在high-speed network高性能网络上,让client能够快速访问
使用缓存CND、Nginx缓存
或者将你的服务器靠近用户,多IDC进行对不同区域用户服务。如:中国IDC、韩国IDC
去掉一些低效率算法,参考: Nagle's algorithm
调整服务器的TCP堆栈(参考 这篇文章). 然而调整TCP堆栈不会有多大作用,因为内核默认配置已经做了优化调整了。
除了以上举的两个例子,还有各种组合可以分析,比如
2.2.3 $upstream_connect_time很大
可能是网络通信出现了问题;
2.2.4 $upstream_header_time很小,但是$upstream_response_time很大,可能是数据回写nginx出现了问题。
不难看出,通过这些变量,便可以快速定位到问题环节,而不至于毫无头绪的到处排查,可以说是事半功倍。
3 request_time与upstream_response_time比较
3.1 一般request_time比upstream_response_time大
如果用户端网络状况较差 或者传递数据本身较大
再考虑到 当使用 POST 方式传参时 Nginx 会先把 request body 缓存起来
而这些耗时都会累积到 [1用户请求] 头上去
这样就解释了:为什么 request_time 有可能会比 upstream_response_time 要大。
因为用户端的状况通常千差万别 无法控制 ,所以并不应该被纳入到测试和调优的范畴里面
更值得关注的应该是 upstream_response_time
所以在实际工作中 如果想要关心哪些请求比较慢的话,记得要在配置文件的 log_format 中加入 $upstream_response_time
3.2 upstream_response_time比request_time 大
在我的测试中,我居然发现了这个情况
log_format f_access_log '$remote_addr *$connection [$time_local] "$request" '
'$status $body_bytes_sent $request_time $upstream_response_time';
时间是这样的结果:0.039 0.040
3.2.1 为什么大呢?
最开始我猜测可能是有点计算误差吧,大多数情况是两者相等或者request_time较大。但是还是不死心,网上查了查原因,最终找打了一个合理的解释,nginx.org官网有个说明:https://forum.nginx.org/read.php?21,284448,284450#msg-284450
$ upstream_response_time由clock_gettime(CLOCK_MONOTONIC_COARSE)计算,默认情况下,它可以过去4毫秒,相反,$ request_time由gettimeofday()计算。 所以最终upstream_response_time可能比response_time更大。
3.2.2 为什么调用不同函数呢?
那问题又来了,为什么两个时间不用同一个函数计算呢?可能有以下几个原因:
clock_gettime比gettimeofday更加精确
但是gettimeofday比clock_gettime效率更高,gettimeofday走的是vsyscall[1](虚拟系统粗糙的描述就是不经过内核进程的切换就可以调用一段预定好的内核代码),没有线程切换的开销。
clock_gettime本身的执行就非常耗费时间,其大概的调用路径是:clock_gettime -> sys_call -> sys_clock_gettime -> getnstimeofday -> read_tsc -> native_read_tsc
所以这里我大胆猜测一下,可能是Nginx为了效率,在某些操作比较多的时间计算上调用的是gettimeofday函数。
大家可以参考这篇文章:https://www.cnblogs.com/raymondshiquan/articles/gettimeofday_vs_clock_gettime.html
4 指导意义
所以在通过nginx的access_log来分析后端程序接口响应的时候,需要在nginx的log_format中添加$upstream_response_time字段。
5 参考:
https://juejin.im/post/5d26eb16f265da1bd522f8d6
https://www.cnblogs.com/thatsit/p/7078210.html
https://imtx.me/archives/2692.html
https://stackoverrun.com/cn/q/10318767
https://www.cnblogs.com/dongruiha/p/7007801.html
转载:https://www.cnblogs.com/wx170119/p/12030545.html
https://blog.csdn.net/zzhongcy/article/details/105819628