五、基于分区进行操作
基于分区对数据进行操作可以让我们避免为每个数据元素进行重复的配置工作。诸如打开数据库连接或创建随机数生成器等操作,都是我们应当尽量避免为每个元素都配置一次的工作。Spark 提供基于分区的 map 和 foreach ,让你的部分代码只对 RDD 的每个分区运行一次,这样可以帮助降低这些操作的代价。
当基于分区操作 RDD 时,Spark 会为函数提供该分区中的元素的迭代器。返回值方面,也返回一个迭代器。除 mapPartitions() 外,Spark 还有一些别的基于分区的操作符,列在了表中。

1、mapPartitions
与map类似,不同点是map是对RDD的里的每一个元素进行操作,而mapPartitions是对每一个分区的数据(迭代器)进行操作,具体可以看上面的表格。下面同时用map和mapPartitions实现WordCount,看一下mapPartitions的用法以及与map的区别。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
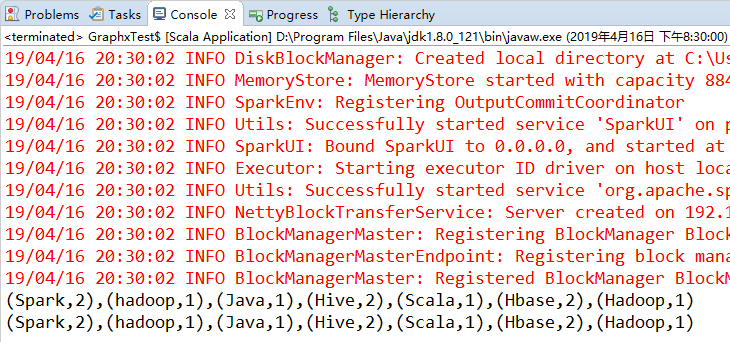
val input = sc.parallelize(Seq("Spark Hive hadoop", "Hadoop Hbase Hive Hbase", "Java Scala Spark"))
val words = input.flatMap(line => line.split(" "))
val counts = words.map(word => (word, 1)).reduceByKey { (x, y) => x + y }
println(counts.collect().mkString(","))
val counts1 = words.mapPartitions(it => it.map(word => (word, 1))).reduceByKey { (x, y) => x + y }
println(counts1.collect().mkString(","))
}
}
2、mapPartitionsWithIndex
和mapPartitions一样,只是多了一个分区的序号,下面的代码实现了将Rdd的元素数字n变为(分区序号,n*n)。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val rdd = sc.parallelize(1 to 10, 5) // 5 代表分区数
val res = rdd.mapPartitionsWithIndex((index, it) => {
it.map(n => (index, n * n))
})
println(res.collect().mkString(" "))
}
}

3、foreachPartitions
foreachPartitions和foreach类似,不同点也是foreachPartitions基于分区进行操作的。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
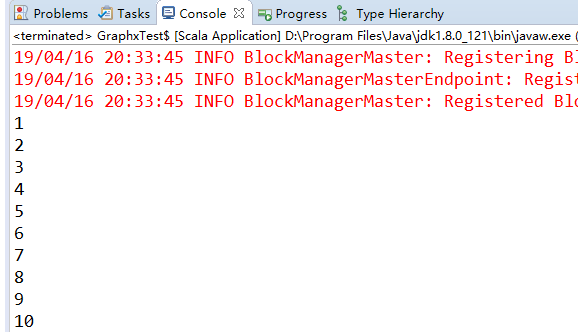
val rdd = sc.parallelize(1 to 10, 5) // 5 代表分区数
rdd.foreachPartition(it => it.foreach(println))
}
}
六、与外部程序间的管道
Spark 提供了一种通用机制,可以将数据通过管道传给用其他语言编写的程序,比如 R 语言脚本。
Spark 在 RDD 上提供 pipe() 方法。Spark 的 pipe() 方法可以让我们使用任意一种语言实现 Spark 作业中的部分逻辑,只要它能读写 Unix 标准流就行。通过 pipe() ,你可以将 RDD 中的各元素从标准输入流中以字符串形式读出,并对这些元素执行任何你需要的操作,然后把结果以字符串的形式写入标准输出——这个过程就是 RDD 的转化操作过程。这种接口和编程模型有较大的局限性,但是有时候这恰恰是你想要的,比如在 map 或filter 操作中使用某些语言原生的函数。
有时候,由于你已经写好并测试好了一些很复杂的软件,所以会希望把 RDD 中的内容通过管道交给这些外部程序或者脚本来进行处理并重用。很多数据科学家都用 R写好的代码 ,可以通过pipe() 与 R 程序进行交互。
七、数值RDD的操作
Spark 的数值操作是通过流式算法实现的,允许以每次一个元素的方式构建出模型。这些统计数据都会在调用 stats() 时通过一次遍历数据计算出来,并以 StatsCounter 对象返回。表列出了 StatsCounter 上的可用方法。

如果你只想计算这些统计数据中的一个,也可以直接对 RDD 调用对应的方法,比如 rdd.mean() 或者 rdd.sum() 。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
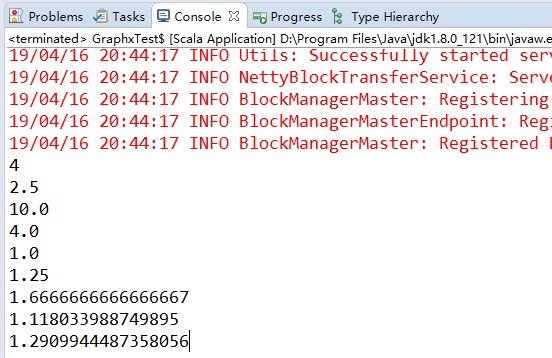
val rdd = sc.parallelize(List(1,2,3,4))
val res = rdd.stats
println(res.count) // 4 统计元素个数
println(res.mean) // 2.5 平均值
println(res.sum) // 10 总和
println(res.max) // 4 最大值
println(res.min) // 1 最小值
println(res.variance) // 1.25 方差
println(res.sampleVariance) //1.667 采样方差
println(res.stdev) // 1.11803 标准差
println(res.sampleStdev) //1.29099 采样标准差
}
}
这篇博文主要来自《Spark快速大数据分析》这本书里面的第六章,内容有删减,还有关于本书的一些代码的实验结果。