今天之所以这么早结束,主要是因为自己脑子不够用了,发现最近的定义有点多,完全搞不清楚了,打算早点睡觉,今天的内容估计要引用很多别人的部分了。
看到题目的四个东东是不是惊呆了,我也是惊呆了,同时脑子还跟不上。
同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blocking IO是一个东西。这其实是因为不同的人的知识背景不同,并且在讨论这个问题的时候上下文(context)也不相同。所以,为了更好的回答这个问题,我先限定一下本文的上下文。
本文讨论的背景是Linux环境下的network IO。
Stevens在文章中一共比较了五种IO Model:
blocking IO
nonblocking IO
IO multiplexing
signal driven IO
asynchronous IO
由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
再说一下IO发生时涉及的对象和步骤。
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
1 等待数据准备 (Waiting for the data to be ready)
2 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。
其实我今天只看了阻塞IO和非阻塞IO,定义太绕口,知道是这么会事情,但是却不知道怎么跟定义有机的对应
一、 blocking IO (阻塞IO)
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
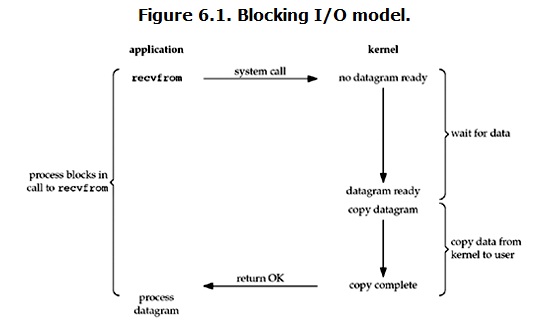
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
对应实例的意思大致就是client不连接server端,server就会在accept那个位置一直等着:
import socket # 客户端 sk=socket.socket() sk.connect(("127.0.0.1",8080)) while 1: data=sk.recv(1024) print(data.decode("utf8")) sk.send(b"hello server") #服务端 import socket sk=socket.socket() sk.bind(("127.0.0.1",8080)) sk.listen(5) while 1: conn,addr=sk.accept() while 1: conn.send("hello client".encode("utf8")) data=conn.recv(1024) print(data.decode("utf8"))
二、non-blocking IO(非阻塞IO)
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
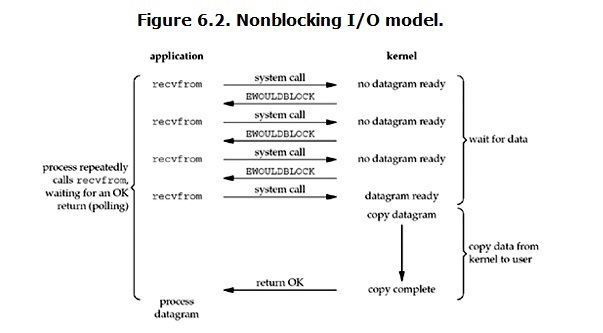
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,用户进程其实是需要不断的主动询问kernel数据好了没有。
注意:
在网络IO时候,非阻塞IO也会进行recvform系统调用,检查数据是否准备好,与阻塞IO不一样,”非阻塞将大的整片时间的阻塞分成N多的小的阻塞, 所以进程不断地有机会 ‘被’ CPU光顾”。即每次recvform系统调用之间,cpu的权限还在进程手中,这段时间是可以做其他事情的,
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
说的大致意思就是我们把setblocking()里面的参数由原来默认True更改为Flase,当没有接收的时候我们会每隔一段时间去看是否收到,从而是空置过程的程序归我们使用。
看范例:
import time #服务端 import socket sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) sk.setsockopt sk.bind(('127.0.0.1',6667)) sk.listen(5) sk.setblocking(False) while True: try: print ('waiting client connection .......') connection,address = sk.accept() # 进程主动轮询 print("+++",address) client_messge = connection.recv(1024) print(str(client_messge,'utf8')) connection.close() except Exception as e: print (e) time.sleep(4) #客户端 import time import socket sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) while True: sk.connect(('127.0.0.1',6667)) print("hello") sk.sendall(bytes("hello","utf8")) time.sleep(2) break
优缺点非常明显:
优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
缺点:任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
今天就是这些了,早点休息,累累累。。。
然后最近的博客有点水,明天最好加个餐。。。