一、Mysql连接数
1、配置Mysql连接数:
vim /etc/my.cnf [mysqld]下面修改
max_connections=1000 不写默认为100。
wait_timeout=60 设置超时时间
2、查看当前连接数:
show status like '%Threads_connected%';

show processlist;

二、Mysql缓存
1、开启缓存:
vim /etc/my.cnf mysqld下面添加或修改
query_cache_type=on #开启缓存
query_cache_size=10M #缓存总大小
query_cache_limit=1M #查询结果超过设置值,就不会缓存
需重启mysql服务生效。
2、查看缓存状态:
SHOW VARIABLES LIKE '%query_cache%';

3、开启profile:
set @@profiling=1; 设置profile开启
select @@profiling; 查看profile是否开启
show profiles; 查看所有的profile
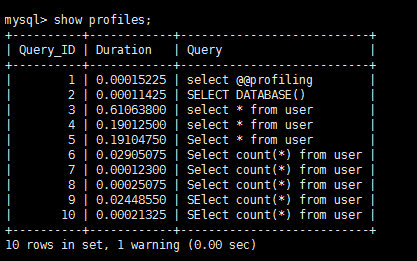
show profile for query 9; 查看指定的sql语句消耗的时间


可以看出:同样的sql语句,第9条是首次查询消耗时间,耗时比较长,第10条是从缓存查询消耗时间,耗时明显比较短。
注:1、select语句必须完全相同才会从走缓存,例如:大小写不一样,虽然查询结果一样,但是不会走缓存。
2、任何一个包含不确定的函数(比如:now(),current_date())的查询不会被缓存。
4、queryCache使用状态:
SHOW STATUS LIKE 'Qcache%';

Query Cache 命中率= Qcache_hits / ( Qcache_hits + Qcache_inserts );
Qcache_free_blocks Query Cache中目前还有多少剩余的blocks。如果该值显示较大,则说明Query Cache 中的内存碎片较多了,可能需要寻找合适的机会进行整理。如果这个值非常大,可以使用FLUSH QUERY CACHE;语句来清理查询缓存碎片以提高内存使用性能。该语句不从缓存中移出任何查询。
5、查询语句生命周期:
1.Mysql服务器监听3306端口
2.验证访问用户
3.创建Mysql线程
4.检查内存(qcache)
5.解析SQL
6.生成查询计划
7.打开表
8.检查内存(Buffer Pool)
9.到磁盘读取数据
10.写入内存
11.返回数据给客户端
12.关闭表
13.关闭线程
14.关闭连接
三、innodb 存储引擎
1、开启innodb_buffer_pool
vim /etc/my.cnf mysqld 下面添加或修改
innodb_buffer_pool_size=20M #设置bufferpool大小
innodb_buffer_pool_dump_now=on #默认为关闭OFF。如果开启该参数,停止MySQL服务时,InnoDB将InnoDB缓冲池中的热数据保存到本地硬盘。
innodb_buffer_pool_load_at_startup = on #默认为关闭OFF。如果开启该参数,启动MySQL服务时,MySQL将本地热数据加载到InnoDB缓冲池中。
2、查看Innodb_buffer_pool状态
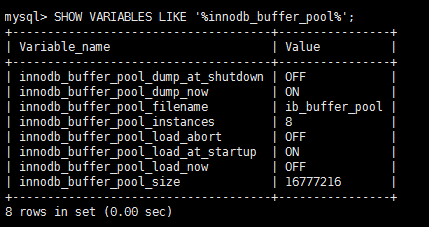
SHOW VARIABLES LIKE '%innodb_buffer_pool%';
SHOW STATUS LIKE '%Innodb_buffer_pool%';

4、 自动提交
set @@autocommit=0; #关闭自动提交,仅对当前用户有效
select @@autocommit; #查看自动提交是否开启
commit; #提交执行语句
5、锁:
show processlist; #查看当前锁定sql

注:如果修改的数据条件是索引列,则是行级锁,否则就是表级锁。
四、慢查询
1、查询慢查询日志是否开启
SHOW VARIABLES LIKE '%query%';

2、慢查询日志设置(执行命令)
set global slow_query_log=on; #开启慢查询日志
set global long_query_time=1; #设置记录查询超过多少秒的Sql存入慢查询
set global slow_query_log_file='/opt/data/slow_query.log'; #设置慢查询日志路径,此路径需要有写入权限
3、解析慢查询日志
mysqldumpslow -s t -t 10 -g 'select' /opt/lampp/var/mysql/xiaoxitest-slow.log

4、使用EXPLAIN/DESC 查看Sql效率
EXPLAIN update user set age=11 where id=1;
DESC update user set age=11 where id=1;

type列:依次从最差到最优
all<index<range<ref<eq_ref<const,system<null