在CPU上定义两个数并赋值,然后使用GPU核函数将两个数相加并返回到CPU,在CPU上显示
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <iomanip> #include <iostream> #include <stdio.h> using namespace std; //检测GPU bool CheckCUDA(void){ int count = 0; int i = 0; cudaGetDeviceCount(&count); if (count == 0) { printf("找不到支持CUDA的设备! "); return false; } cudaDeviceProp prop; for (i = 0; i < count; i++) { if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) { if (prop.major >= 1) { break; } } } if (i == count) { printf("找不到支持CUDA的设备! "); return false; } cudaGetDeviceProperties(&prop, 0); printf("GPU is: %s ", prop.name); cudaSetDevice(0); printf("CUDA initialized success. "); return true; } //使用指针相加 __global__ void addNumber(double a, double b, double *c); int main(){ //检测GPU if (!CheckCUDA()){ cout << "No CUDA device."; return 0; } cout << "*************************************************************************************************************" << endl; double h_a, h_b, h_c; //在CPU上定义三个变量 double *d_c; //定义一个将指向GPU的指针 h_a = 2.2; h_b = 3.3; cudaMalloc((void **)&d_c, sizeof(double)); //为指针在GPU上分配内存空间
//调用核函数并启用一个线程块和一个线程 addNumber<<<1, 1>>>(h_a, h_b, d_c); //只是单独的两个数相加,不是两个数组相加,只需使用单线程,数组相加可以使用多线程 cudaMemcpy(&h_c, d_c, sizeof(double), cudaMemcpyDeviceToHost); //将GPU上计算好的结果返回到CPU上定义好的变量 //setw(10)表示输出10个空格,需添加 #include <iomanip> cout << setw(10) << h_a << " + " << h_b << " = " << h_c << endl; cout << endl << endl; system("pause"); return 0; } __global__ void addNumber(double a, double b, double *c){ *c = a + b; }
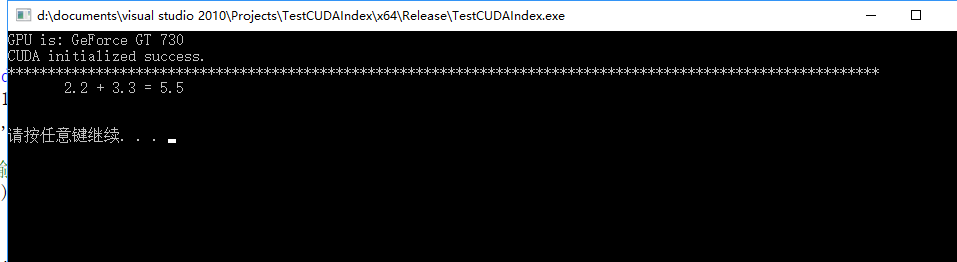
显示结果如下