1、交叉连接(就是将两张表的数据 交叉组合在一起)
有两张表 客户表:[Sales.Customers] 和订单表:[Sales.Orders]。
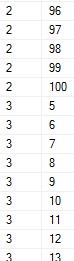
业务需求:实现 Customer中custid(客户Id) 和 Orders表中的 Orderid的 交叉连接
1 select 2 c.custid,o.orderid 3 from [Sales.Customers] as c cross join [Sales.Orders] as o
实现效果:
2、内连接(使用最多的):inner join
业务要求:查询出:Order对应的 Customer中的所有客户的所有订单
1 select c.custid,o.orderid 2 from [Sales.Customers] as c inner join [Sales.Orders] as o 3 on c.custid=o.custid
注意:所有的查询结果都是全部符合 on 后面的 条件,这是和 outer join 正好相反的
3、外连接 (outer join)
和内连接最显著的 不同:就是将不满足条件的数据页查询出来了
注意一点:外连接是要分左外连接和右外连接的,左外连接意思就是outer join左边的表含有超出 on条件的内容
1 select 2 c.custid,o.orderid 3 from [Sales.Customers] as c left outer join [Sales.Orders] as o 4 on c.custid= o.custid
查看查询结果可以看出:
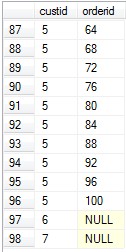
含有两个 orderid 为NULL的结果,就是多出来的 查询结果
通过上面的使用右外连接的使用方法 只不过要将上面的两张表的顺序 变一下
3、对外连接使用的实例,并对组函数里面NULL值的处理讲解
注意:对于组函数(例如:sum()、max()等),对于Null值是不做处理的,不算在内的
1 select 2 c.custid,o.orderid, 3 count(o.orderid) over (partition by c.custid) 4 from [Sales.Customers] as c left outer join [Sales.Orders] as o 5 on c.custid= o.custid
查看结果:
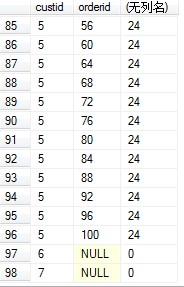
我们可以看到,最后两项求和的值为0.这是因为求和是根据 orderid进行分组的(这里关于分组是通过开窗函数over,后面我会讲解的),组函数COUNT()对NULL是不做处理的,所以为0.