一、拾遗
1、在Python中所有的数据都是围绕对象这个概念来构建的。
对象包含一些基本的数据类型,如:数字、字符串、列表、元组、字典等,所以说程序中存储的所有数据都是对象
每一个对象都具有以下特点:
例如:a = 1
一个身份(用id()命令查看,表示这个对象在内存中的地址)
一个类型(用type()命令查看这个对象的类型)
一个值 (通过变量名来查看。通过变量名引用的值,本例就是1)
2、字符串是可以被while和for循环遍历的。它们是根据字符串的索引遍历的。
3、工厂函数的概念
定义一个数据类型,如:x = 1,实际上调用的是x = int(1),说明凡是整型都是调用int()方法得出的结果,也就是说一个int()方法批量生产了许多许多整型,其它数据类型也是如此,这就是工厂函数的概念。
4、可变数据类型与不可变数据类型
定义一个数据类型,就创建了它的id、type、value。
若id变了,则等于创建了另外一个数据类型了,与原来的数据类型没有关系了。所以id不能变
若type变了,则相当于内存又开辟了一块空间存了一个值进去,与原来的数据类型没有关系了,所以type也不能变
唯一可变的就是value了。所以判断这个数据类型可变不可变就看value了
所以得出结论:区分一个数据类型是可变还是不可变数据类型,必须在id和type不变的情况下,只需要看它的value就可以了
关于可变打个通俗易懂的比方——租房子:
房东A出租自己的房子,租客到期走后,下一个租客就会住进来。房子和房东A不变,只是租客变,这所房子依然是房东A的,这就好比是python的可变数据类型。房子和房东相当于id和type,租客就相当于value,只有租客变化,这就是可变数据类型
例:更改整型的值来查看整型是否是可变类型
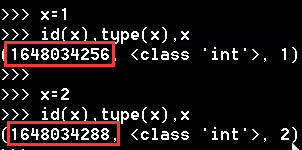
经上图所示,更改整型的值后,再对比之前的id都发现改变了,可见整型不是可变类型。
以上观点适用于python的所有数据类型
5、列表
(1)定义
例:
l = [ 元素1”,"元素2","元素3",...]
这就是列表,里面可以存放多个以逗号分隔开的任意python的数据类型的值,这些值在列表中称为元素,列表是可变数据类型
(2)列表的取值:
列表的取值与字符串的取值是一样的,也是按照索引去取值。
例1:取出下面列表中第2个元素
l = ["xiaobai",18,"haha",[1,2,3],"hello"]
print(l[2]) # 中括号中加上索引值,就可以取出列表中的元素了。
例2:取出下面列表中元素[1,2,3]中的2个元素
l = ["xiaobai",18,"haha",[1,2,3],"hello"]
print(l[3][1]) # 先找到[1,2,3]所在的索引位置,再取出其第2个元素。
(3)列表的类型
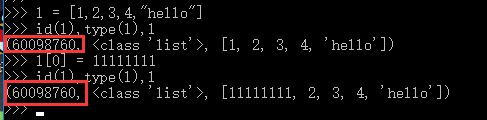
综上图所示证明:列表属于可变数据类型
二、变量赋值操作
1、身份比较、类型比较、值比较:is
例:

2、变量的赋值操作:没有返回值
x = 1 # 这就是变量的赋值操作
print(x=1) # 若直接打印则会报错:TypeError: 'x' is an invalid keyword argument for this function
# 所以只能这样写:print(x)
3、链式赋值
例:
x = y = z = a = b = 10
print(x,y,z,a,b)
打印结果为:10 10 10 10 10
4、多元赋值
若是在c语言中的多元赋值必须通过以下类似于python的这个例子才能进行替换
x = 1
y = 2
z = x # 将x的值赋予z z = 1
x = y # 把y的值又赋予x x = 2
y = z # 把y的值赋予z y = 1
print(x,y) # 此时x与y的值就被换过来了
而在python中是这样的进行多元赋值操作的:
x = 1
y = 2
x,y = y,x # 多元赋值的重要步骤
print(x,y) # 此时x与y的值就直接被换过来了
以上就是多元赋值操作
5、增量赋值
例:
x = 10
x += 1 # x = x + 1
print(x) # 除此之外还有 x -= 1 、x /= 1、x *= 1
6、解压序列类型
有序的类型就是序列类型:字符串、列表
例:把一个字符串中的每一个字符都绑定一个变量
例1:
s = "hello"
a = s[0]
b = s[1]
c = s[2]
d = s[3]
e = s[4]
print(a,b,c,d,e)
输出结果:h e l l o
例2:将例1优化:
s = "hello"
a,b,c,d,e = s # 按照索引开始,将序列依次解压出来
print(a,b,c,d,e) # 得到的结果和例1一样
例3:将例2的例子需要改为只要求输出a和e的值
s = "hello"
a,_,_,_,e = s # 只取出a和e的值,下划线表示将要丢弃的值,pirnt(_)打印下划线还是有值的
# 因为要求只要字符串的前后两个字符,所以这里也可以改成: a,*_,e
print(a,e) # 输出结果为 h o
三、列表
1、定义列表
列表是可变类型
列表可以存放多个值
定义列表:l = [ 元素1”,"元素2","元素3",...]
列表里面的每个值都称为元素。
例:定义一个列表
l = [1,"xiaobai",[3,4]] # 定义这个列表等同于l = list([1,"xiaobai",[3,4]])
2、列表的取值
列表和字符串都是序列类型
取值用“[ ]”取
例1:列表的取值,取出元素“xiaobai”
l = [[1,"xiaobai",[3,4]]
print(l[1])
例2:列表的取值,取出元素[3,4]中的元素“3”
l = [[1,"xiaobai",[3,4]]
print(l[1][0])
3、列表的循环
列表是有序类型
例1:循环l列表中的每个元素:
l = [1,2,3,[4,5]]
count = 0
while count < len(l):
print(l[count])
count += 1
例2:遍历列表“l = [1,2,3,[4,5]]”中“[4,5]”里的元素
l = [1,2,3,[4,5]]
for count in range(len(l)):
if type(l[count]) is list: # 判断类型是列表的元素
for i in range(len(l[count])): # 将这个元素进行遍历
print(l[count][i])
输出结果:


4 5
4、列表的常用操作
例:l = ["xiaobai",1,2,3,"hello"]
(1)索引
用“[ ]”来对列表进行索引操作
print(l[0]) # 得到元素“xiaobai”
(2)切片
用“[:]”来对列表进行切片操作
print(l[1:3]) # 得到[1,2]列表,此操作不对原列表进行修改,这是读操作
(3)追加
<1>append()
往列表后加上添加元素
l = ["xiaobai",1,2,3,"hello"]
l.append("python")
print(l)
输出结果:
['xiaobai', 1, 2, 3, 'hello', 'python']
<2>insert()
往列表里插入元素,insert(位置,要插入的元素),插入的元素插入到了指定位置的元素前面了。
l = ["xiaobai",1,2,3,"hello"] l.insert(0,"python") # 在索引0的位置的元素前插入元素“python” print(l)
输入结果:
['python', 'xiaobai', 1, 2, 3, 'hello']
(4)删除
pop() 括号中不加任何参数默认删除列表中最后一个元素,括号里只能是整型,返回值就是被删除的元素。
l = ["xiaobai",1,2,3,"hello"] l.pop(4) # 删除列表中索引值为4的元素 print(l)
输出结果:
['xiaobai', 1, 2, 3]
(5)长度
len()统计列表长度
(6)循环
while和for来循环
例:
index = 0
while index < len(l):
print(l[index])
index += 1
不通过索引进行循环则:
for i in l:
print(l)
(7)包含
用in来判断列表包含关系
例:
l = ["xiaobai",1,2,3,"hello"]
print("xiaobai" in l)
输出结果:
True
5、队列和堆栈
(1)队列:先进先出
队列就像人走电梯,先上电梯的人一定会先下去
<1>用append()和pop(0)来模拟队列
从右至左进入,再由左至右出去

<2>用insirt()和pop()模拟队列
从左至右进入,再由右至左出去

(2)堆栈:先进后出,或者是后进先出
用append()和pop()模拟堆栈

6、列表的其它操作
参照 http://www.cnblogs.com/xiaoxiaobai/p/7615608.html
四、元组
定义元组:
t = (“元素1”,"元素2","元素3",...)
1、元组的特点
与列表的操作方法相同,唯一的区别是元组是不可变数据类型,不可以更改元组里的元素
2、元组的常用操作
例:t = ("xiaobai",1,2,3,"hello")
(1)索引
index() 统计索引
print(t.index('hello')) # 打印指定元素的索引位置
count() 统计个数
print(t.count("xiaobai")) # 统计"xiaobai"这个元素的个数有几个
(2)取值
取值用“[ ]”取
print(t[0]) # 打印索引位置为0的元素
(3)循环
用while 和 for循环
例:
index = 0
while index < len(t):
print(t[index])
index += 1
不通过索引进行循环则:
for i in t:
print(t)
(4)切片 读操作
用“[:]”来对 元组进行切片操作
操作与列表一致
(5)长度
len()统计元组长度
print(len(t)) # 得到元组t的长度
(6)包含
用in来判断列表包含关系
print("xiaobai" in t) # 得到布尔值
五、字典
1、定义
d = {'key':'value'} 等同于 d = dict({"key":"value"})
字典属于可变类型
2、定义字典需要注意的问题:
(1)字典的key:
key必须是不可变类型,或者是可hash类型,(hash目前可以理解为不可变)也就是说只要是可hash的就可以当作字典的key,字典本身不可以当作字典的key
(2)字典的value:
可以是任意类型
补充:
查看hash值的命令:
例:print(hash('xiaobai')) # 得到一串hash值的数字
python的数字、字符串、元组都是hash类型,列表、字典除外
(3)字典是无序的、没有索引值的
每次打印一个字典,它的排序有可能会不同。
3、补充:
Python数据类型的分类
(1)按可变和不可变:
可变:列表,字典
不可变:数字,字符串,元组
(2)按存放值的个数:
标量类型(一个值):数字,字符串
容器类型(多个值):列表,元组,字典
(3)按取值方式:
直接取值:数字,
序列类型(按照索引): 字符串,元组,列表
映射类型:字典
4、字典的常用操作
例: d = {"name":"xiaobai","age":18}
(1)取值
通过key进行取值
用[key]来对字典进行取值操作
print(d["name"]) # 取出键"name" 对应的值:“xiaobai”
<1>取出字典中所有的key命令:d.keys()
print(d.keys()) # 得到字典的所有key
<2>取出字典中所有的value命令:d.values()
print(d.values()) # 得到字典的所有value
(2)修改
用[ ]来对字典进行修改操作
d['name'] = 'xiaoxiaobai' # 将原来的值"xiaobai"改为“xiaoxiaobai”
(3)循环
不能通过索引方式去遍历,字符串、列表、元组一样可以用不通过索引的方式去遍历。
用for循环
取出字典中所有的key和value
for k in d:
print(k,d[k]) # 得到的结果是把字典的所有key都取出来了,而且都是无序的。
# 其中的d[k]表示循环字典中所有的value
(4)嵌套
Python中最完善的数据类型就是字典。
例1:取出以下例子中所有的用户名和密码
# 取出所有账号密码
user_info =[
{"username":"xiaobai","password":"123456"},
{"username":"xiaoxiaobai","password":"hw8710"},
{"username":"haha","password":"nihao111"},
]
for item in user_info:
# print(item) # 得到每一个小字典
print(item['username'],item['password']) # 取出所有的用户名和密码
输出结果:
xiaobai 123456
xiaoxiaobai hw8710
haha nihao111
例2:用户登陆
# 相当于后台,将正确的用户名和密码存放在一个列表里
user_info =[
{"username":"xiaobai","password":"123456"},
{"username":"xiaoxiaobai","password":"hw8710"},
{"username":"haha","password":"nihao111"},
]
# 相当于前台,用户输入账号密码
tag = True
while tag:
username = input('Please input your username:')
password = input('Please input your password:')
for item in user_info:
if username == item['username'] and password == item['password']:
print('Login successful!')
tag = False
break
例1和例2的问题:
假设有一万个用户的账号,第一次循环就正好与用户输入的比对上了,只循环一次即可。如果在9999次循环后才与用户输入的比对上,那么前面的的9999次就是无效循环,所以这种方式不可取,程序员设计的目的是为了方便存取,例1和例2的设计就是一种失败的设计,那么将例2改为以下例3的设计方案:
例3:用户登陆
user_info ={
"xiaobai":"123456", # 将用户名的账号密码对应成键和值的形式
"xiaoxiaobai":"hw8710",
"haha":"nihao111",
# 字典是无序存储的,它是通过key取值的,那么内存当中不存索引,所以key必须是不可变类型,key就是hash类型。
# 所以内存中维护的是一张hash表,hash表存放着一个个的key,通过hash值就直接能找到value,所以字典的查询速度非常快
}
while True:
username = input('Please input your username:')
password = input('Please input your password:')
if username in user_info: # 用户输入的用户名一定是字典的key,判断用户输入的用户名是否在字典里
if password == user_info[username]: # 用户名在字典里的情况下,取出字典里的密码与用户输入的密码进行判断
print('Login successful!')
break
补充1:分析容器类型:列表、元组、字典在内存中的存存储情况
假设要往内存里存1万个值
(1)列表:可变数据类型,所以内存里会有相应的处理机制,若要加值,则需要预留内存空间
(2)元组:不可变数据类型,定义时有多大就内存占用就多大,不会增加内存空间,占用内存资源最小
(3)字典:可变数据类型,在内存里存放的是一张hash表,hash表最终也是要对应索引,占用内存资源最大,但是却优化了查询速度
补充2:get( )方法的用法:
d = {'a':1}
# print(d['b']) # 直接取一个不存在的键会报错
print(d.get('a')) # 用get方法取一个存在的键则会得到对应的值
print(d.get('b')) # 用get方法取一个不存在的键不会报错,会得到:None
输出结果:
1
None