本例记录spark源码编译的过程及问题
因为编译会有很多很多莫名其妙的错误,为了方便,使用hadoop的cdh版本,注意版本要和我的一致,
maven3.0.5
scala2.10.4 下载地址:http://www.scala-lang.org/download/all.html
spark-1.3.0-src 下载地址:http://spark.apache.org/downloads.html
hadoop版本:hadoop-2.6.0-cdh5.4.0.tar.gz 下载地址:http://archive.cloudera.com/cdh5/cdh/5/ 大小:282M
方式:
make-distribution.sh打包的方式(自带maven)
命令:
进入spark目录下
cd $SPARK_HOME
./make-distribution.sh --tgz -Pyarn -Phadoop-2.4 -Dhadoop.version=2.6.0-cdh5.4.0 -Phive-0.13.1 -Phive-thriftserver
------------------------------------------------------------------------------------------------------------------------------------,
编译前的准备
1,编译镜像配置
因为我的 /root/.m2目录下没有settings文件,所以设置了全局的,在conf目录下,可以 cd $MAVEN_HOME/.m2 ,进行设置
maven的conf目录中settings文件加入:
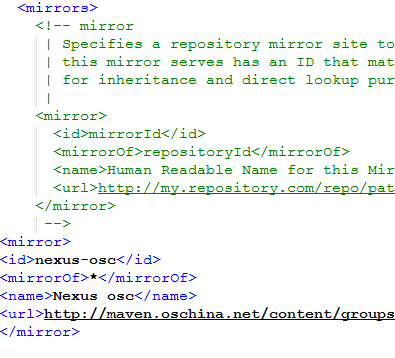
<mirror>
<id>nexus-osc</id>
<mirrorOf>*</mirrorOf>
<name>Nexus osc</name>
<url>http://maven.oschina.net/content/groups/public/</url>
</mirror>
2,域名配置
maven编译容易被墙,所以加入下面两个域名,就不容易出错
vi /etc/resolv.conf 加入两个域名

3,
因为make-distribution.sh执行时候会自己查找版本之类的动作,为了加快速度,把下面这段代码注释掉,自己手动加入版本信息,
make-distribution.sh中修改如下
-------
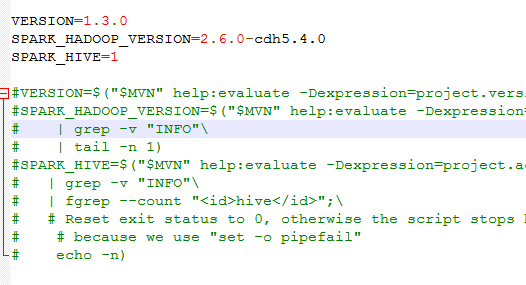
解释:
VERSION=1.3.0 //spark的版本
SPARK_HADOOP_VERSION=2.6.0-cdh5.4.0 //hadoop的版本
SPARK_HIVE=1 //hive, 1表示需要将hive的打包进去,非1数字表示不打包hive
编译完成之后会生成一个spark-1.3.0-bin-2.6.0-cdh5.4.0.tgz
这是云帆大数据老师给的方法我整理出来,
也可以直接使用官方给出的编译后的jar包,比如给出了build-hadoop2.6,那就下载相对应的hadoop版本使用