Storm 支持一些在线的实时,批量处理分析的流式计算
一般使用都是结合消息队列(数据源)和数据库()来结合使用,
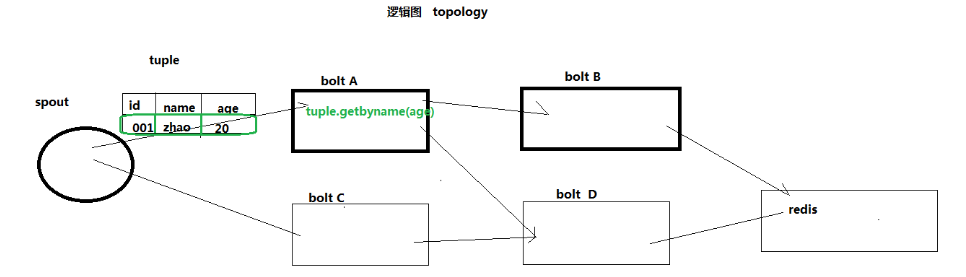
逻辑图:
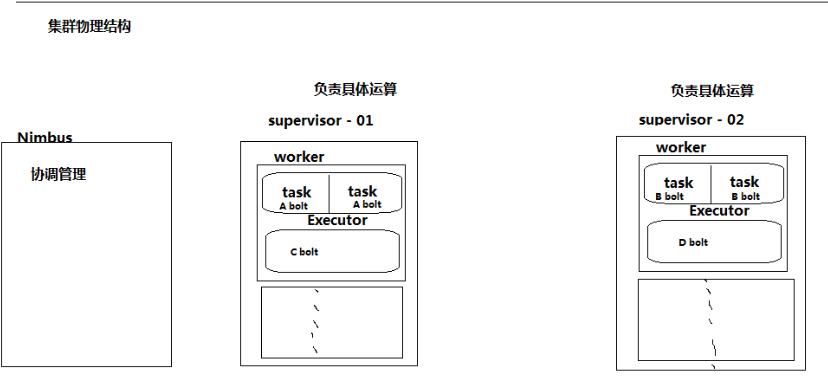
集群物理结构:
spout:数据源,消息的发送者
bolt: 处理数据,消息的处理者
tuple:定义好的一种数据传输结构
workers:最大的进程
executor:线程
task:线程中的实例
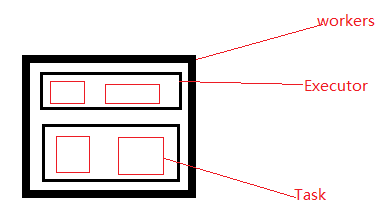
其他解释:
numbus: Storm由一个主节点和多个工作节点组成,主节点运行"nimbus"守护进程,每个工作节点都运行了“supervisor”守护进程,用于监听工作
stream: 被处理的数据 消息流
spout: 数据源 消息的发送者
bolt ; 处理数据 消息的处理者
task: 运行spout 或 bolt的进程
worker: 运行这些线程的进程,
stream grouping : 消息分组策略, 规定了bolt接受什么东西作为数据,
数据随机分配: shuffle
数据根据字段分配: fields
广播: all
总是发给一个task: gobal
自定义逻辑: direct
不关心数据: none
topology:是由stream grouping 连接起来的 类似于mapreduce中的job
sotm的启动
./storm nimbus
jps: nimbus
./storm ui 提供访问web的服务,端口:8080
jps:config_value -------> core
./storm supervisor
jps:supervisor
一个supervisor 会启动4个workers,slots
{kind=link}