YOLOv3
作者:Joseph Redmon
CVPR'18
paper:YOLOv3: An Incremental Improvement
亮点
- 提出新的backbone-darknet53
- 没有池化层和全连接层
- 增加了分支,用于检测小目标对象(13$ imes(13, 26) imes(26, 52) imes$52)
网络结构
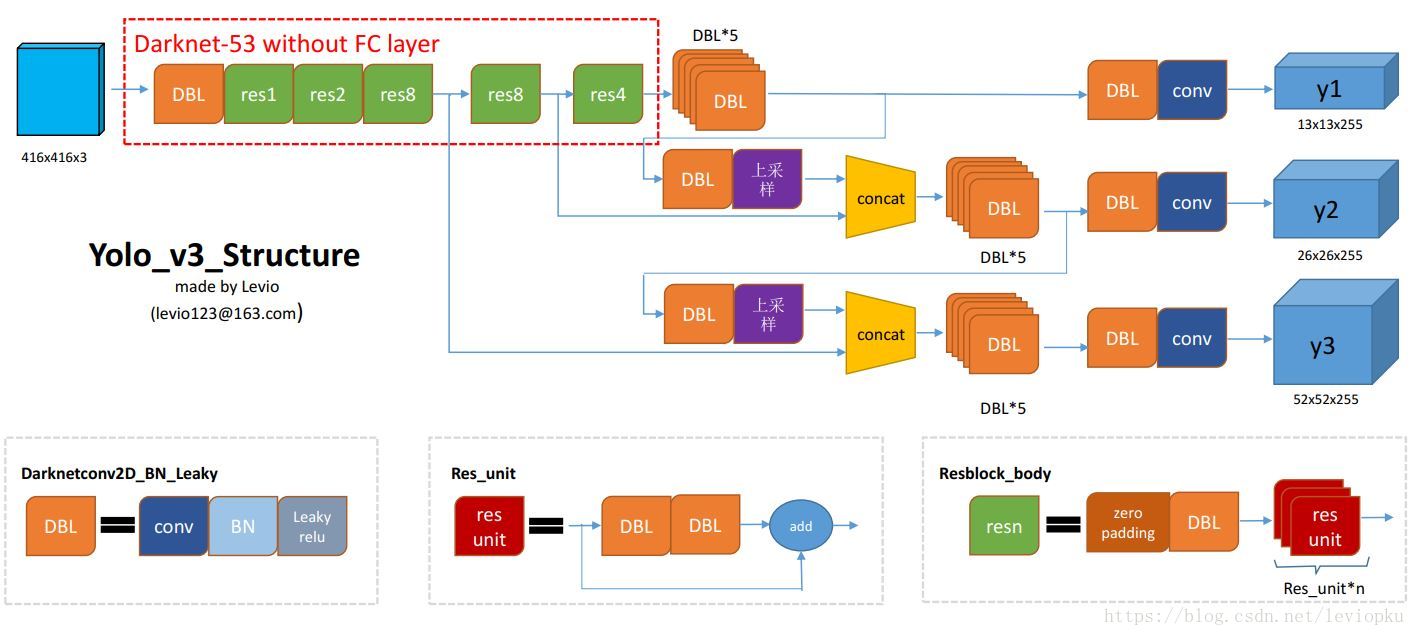
YOLOv3除去了池化层和全连接层,用卷积操作代替。
引入了残差结构,使得backbone更深。
对不同层的输出进行上采样拼接,增加了2条分支,用于预测小目标。每条分支最后的输出深度为255,原因是每条分支包括3个anchor,并且针对COCO80个种类设计,每个位置需要预测4个偏移量和1个置信度,3( imes)(5+80)=255
bounding box的预测:和YOLOv2类似,每个网格的左上角坐标为((c_x,c_y)),bounding box有先验长宽,使用预测值调整bounding box的边界。
每个框有个objectness分数(置信度,逻辑回归预测),bbox和GT的IOU大于0.5并且IOU最大的为1,作为正样本;其余大于0.5的舍弃,小于0.5的作为负样本,这样做可以舍弃不必要的anchor,减少计算。
如果一个bbox没有被分配到GT,就不计算候选框损失和分类损失,只计算objectness损失。
分类预测:没有使用softmax分类器。