SPP-Net
ECCV'14
Paper:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
Abstract
现存的深度卷积神经网络要求固定输入图像的尺度(比如224*224),这种人工设定的先验尺度会降低不同尺度输入图像的检测精度。论文中提出了空间金字塔池化操作,来解决输入图像尺寸固定的问题,叫做SPP-Net。SPP-Net可以为任意尺度的图像生成固定长度的表示结构。由于上述的特点,SPP-Net可以用在基于CNN的图像处理方法中,显著提高效果。比如再目标检测中,就可以对原图只做一次特征提取,然后再不同大小的候选框上采用空间金字塔池化生成固定长度的表示,这样就能显著减少计算量。SPP-Net在分类和检测任务上都达到了SOTA。
Introduction
问题:图像领域中CNN方法需要固定输入图像的尺度,这样会限制输入图像,对不同尺度的图像泛化效果不理想。裁剪图像会丢失信息,重采样这回噪声目标失真。
问题分析:CNN的卷积层部分采用滑动窗口,对输入图像尺度并没有要求,而全连接层需要固定输入输出大小,因此限制了图像的输入尺寸。
解决办法:在卷积层和全连接层之间增加SPP-Net,将不同尺度输入图像的卷积结果转换为固定长度的表示,然后传入到全连接层。
SPP-Net的优点:
- 可以生成固定长度的表示
- 多层空间箱(后面会提到,
SPP-Net操作在不同大小的箱子内) - 提取不同尺度区域的特征
Deep Network With Spatial Pyramid Pooling
原理:对特征图进行分区,对每个区域采取最大池化/平均池化。
例子:
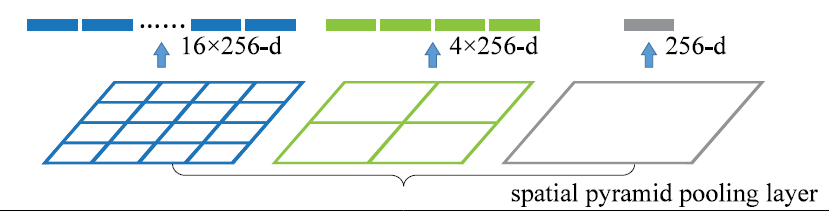
蓝色框无论特征图有多大,都将特征图划分成16个区域,在每个区域内最大池化操作,因此可以得到长度为16的特征向量。
对同一特征层采用不同大小的池化操作,得到的特征向量拼接到一起,作为该层的特征表示。
训练策略
作者提出了两种训练方式
- 训练图片的大小唯一
- 训练图片的大小不唯一
训练图片的大小唯一:
过程类似于上图,主要目的是验证不同层的池化操作的效果。
训练图片的大小不唯一:
设计了两个不同大小输入的网络(同一图像的两个分辨率224,180),在训练的时候每个分辨率训练一个epoch,交替训练,保证参数共享即可。主要目的是控制输入图像的分辨率,观察多分辨率情况下的效果。