发现 中间件监控看是否有性能瓶颈
核心:主要看中间件的线性池进程池有没有排队情况,请求是否处理及时就OK
Apache
以前php都是用apache,现在基本用nginx了。
首先自己启动apache,它的工程路径在/var/www/下面
1 # ps -ef|grep httpd 2 root 1319 1 0 00:42 ? 00:00:00 /usr/sbin/httpd 3 apache 1335 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 4 apache 1336 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 5 apache 1337 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 6 apache 1338 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 7 apache 1339 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 8 apache 1340 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 9 apache 1341 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 10 apache 1342 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd
首先,切换到httpd的路径:(我们是yum安装的apache,因为编译安装的只有一种工作模式,yum安装才能出来3种工作模式),可以看到三个执行文件,分别是httpd,httpd.event,httpd.worker。分别是apache的三种工作模式,我们默认使用的是httpd这个文件的工作模式。那假设我想用httpd.event的工作模式怎么办呢?把httpd的文件名改成其他的,把httpd.event改成 httpd 。其实默认的httpd本来的名字是 httpd.prefok
所以说有三种模式:.prefok;.event;.worker

我们yum安装的httpd文件会比较分散,主要的是在:/etc/httpd 下面

conf不用讲,是配置文件夹

httpd.conf 就是配置文件
我们可以进去查看下:
ServerTokens OS ##不用管,操作系统版本 ServerRoot "/etc/httpd" ##apache的安装路径,不用改 PidFile run/httpd.pid ##在/etc/httpd/run/有一个httpd.pid,这个意思是pidfile会生成在这个路径下。启动的时候这个文件会生成现,这个文件在的话,apache会判定是启动;关闭后这个文件默认会删除,但是如果有时候apache异常关闭,方法不对,会导致这个文件没删除。接下来apache也启动不了,正确做法是手动删除
Timeout 60 ##超时时间,这个超时时间是什么超时???在接收跟发送之前的超时,是请求过来了,tcp/ip连接已经连接了,但是没处理。这个不是connection-timeout,connection-timeout是客户端配置的,客户端发送请求,比如60秒内没连上,就是connection-timeout
KeepAlive Off ##JMeter默认的长链接是on。长链接是啥子东西呢,比如说请求一个页面,用一个链接形成一个链接通道,用这个通道再去send和receive这个请求。复用长链接的话是不同请求页面用之前的那个链接通道,通道会被占住,下次要用的话再继续用这个通道。省去了重新建立链接和关闭链接的过程,但是,链接通道是有限的,占满了的话,其他的请求就不能继续进行链接了
MaxKeepAliveRequests 100 ##最大长链接的请求数,比如说我给300个并发,但是只有100个长链接,代表有200个并发连接不上长链接
KeepAliveTimeout 15 ##长链接的会话保持时间,在这个链接通道内,一个客户端隔了15秒还没发送下一个请求,则长链接就被释放(一般设置3-5秒就够了)
# prefork MPM ##MPM是工作模式,默认为profork
Listen 90 ##对外提供服务的端口号,apache默认为80
LoadModule…….so(一大堆) ##加载的动态库
Include conf.d/*.conf ##把配置文件conf.d文件夹内的以.conf结尾的文件包含进来,可以切换到conf.d文件夹看一看,默认有个welcome.conf,php.conf(php编译后生成的)
User apache ##哪个用户
Group apache ##用户组
ServerAdmin root@localhost
UseCanonicalName Off
DocumentRoot "/usr/local/zentaopms/www" ##工程路径,就是代码往哪儿搁,就往这里放,把安装包往这里放就得了
<Directory "/var/www/html"> ##跟工程路径保持一致
ErrorLog logs/error_log ##日志路径
LogLevel warn ##日志级别,有debug, info, notice, warn, error, crit,alert, emerg可选择。详细点的日志用debug,一般我们用info级别
CustomLog logs/access_log common ##用户日志,一般被注释,可打开
##状态码不同的提示过着提示的路径内容如下,其内容可自行定制:
#ErrorDocument 500 "The server made a boo boo."
#ErrorDocument 404 /missing.html
#ErrorDocument 404 "/cgi-bin/missing_handler.pl"
#ErrorDocument 402 http://www.example.com/subscription_info.html
监控的话,把下面俩的注释取消掉:且默认的Allow from .example.com 改成 Allow from all
如果httpd.conf没有以下内容,粘贴进去,就OK也可以加上监听效果
<Location /server-status>
SetHandler server-status
Order deny,allow
Deny from all
Allow from all
</Location>
ExtendedStatus On ##这一行是详细的监听效果,不需要就不要加就ok
<Location /server-info>
SetHandler server-status
Order deny,allow
Deny from all
Allow from all
</Location>
改了。重启
service httpd restart 或者
cd/usr/sbin 下面,执行 ./httpd
接着,看apache有没有启动,然后进入apache的 ip:port/server-status 就可以看到监控的信息(我配置的端口为90),能出来就代表监控成功
http://IP地址:端口/server-status
http://IP地址:端口/server-info
http://IP地址:端口/server-status ?refresh=N ##N将表示访问状态页面可以每N秒自动刷新一次
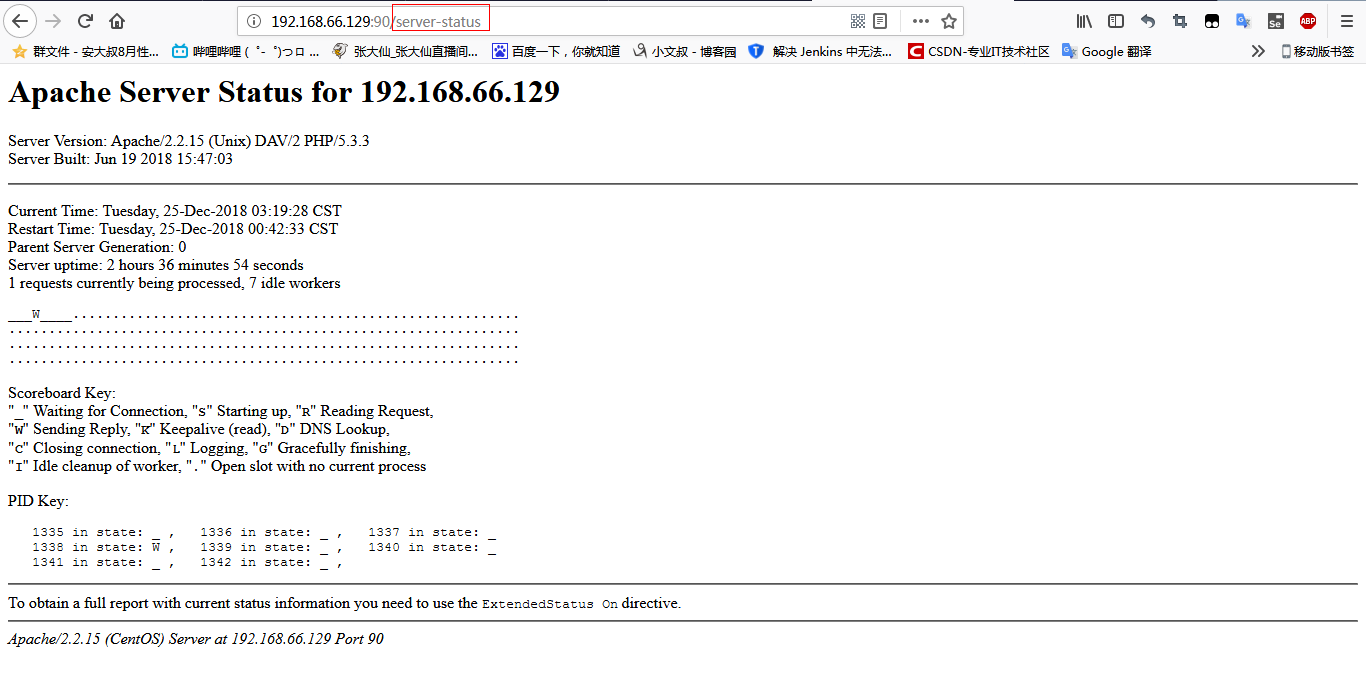
还有个是 ip:port/server-info

现在,我们的apache是prefork工作模式,监控的界面在 ip:port/server-status 如上图,我们看配置文件内的prefork工作模式的配置
# prefork MPM # StartServers: number of server processes to start # MinSpareServers: minimum number of server processes which are kept spare # MaxSpareServers: maximum number of server processes which are kept spare # ServerLimit: maximum value for MaxClients for the lifetime of the server # MaxClients: maximum number of server processes allowed to start # MaxRequestsPerChild: maximum number of requests a server process serves <IfModule prefork.c> StartServers 8 MinSpareServers 5 MaxSpareServers 20 ServerLimit 256 MaxClients 256 MaxRequestsPerChild 4000 </IfModule>
注意:httpd -l可以知道自己apache的工作模式(worker.c代表worker模式)
# httpd -l Compiled in modules: core.c worker.c http_core.c mod_so.c
这里我们可以看一下,apache的进程有几个:
1 # ps -ef|grep httpd |grep -v grep ##后面的 -v 是排除掉某些字段,这里我们排除掉本身的 gerp 进程 2 root 1319 1 0 00:42 ? 00:00:00 /usr/sbin/httpd 3 apache 1335 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 4 apache 1336 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 5 apache 1337 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 6 apache 1338 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 7 apache 1339 1319 0 00:42 ? 00:00:01 /usr/sbin/httpd 8 apache 1340 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 9 apache 1341 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd 10 apache 1342 1319 0 00:42 ? 00:00:00 /usr/sbin/httpd
Prefork:
很明显,这里显示的 httpd 9个进程,说明,prefork 工作模式是多进程模式,但是apache有8个进程。Prefork MPM是一个非常稳定的模式,Apache在启动之初,会预派生fork一些子进程,然后等待请求进来,并且总会保持一些备用的子进程。同时派生出的每个子进程中只有一个线程,在一个时间点内,只能处理一个请求。Prefork MPM在效率上要比Worker MPM高,但是在内存使用方面也会大很多。
StartServers 8 ##指定服务器启动时建立的子进程数,默认为8,这里我们最好设置为5
MinSpareServers 5 ##指定空闲子进程的最小数量,默认为5。如当前空闲子进程数小于配置的数量则Apache会以最大每秒一个的速度创建新的子进程。
MaxSpareServers 20 ##指定空闲子进程的最大数量,默认为20。如果有超过设置的最大进程数则会杀死多余的进程,如果设置的比MinSpareServers小,则Apache会默认修改为MinSpareServers+1
ServerLimit 256 ##最大是256个线程,如果需要更大就需要加上该参数了。这个参数的最大值是2000,如果需要更大需要编译apache。生效前提:必须放在其他指令的前面
MaxClients 256 ##每个进程下最大的排队请求数
MaxRequestsPerChild 4000 ##这个进程能处理的最大请求数,处理完4000个请求,该进程会被杀死重新启动,防止进程僵死的,如果这进程没处理请求就挂了,用这个可以把进程杀了,如果该值为0,那么这进程一直就不会被杀死
简单看一下网页上的监控信息:
1 requests currently being processed, 7 idle workers ##1个正在进行请求的进程,7个空闲的进程
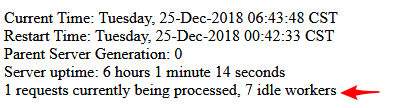
但有的情况是:1 requests currently being processed, 8 idle workers 那么问题来了,我们设置的初始启动的进程数为8,这里为啥加起来超过8?
那么这就关系到起进程和杀进程的逻辑了。开始我们启动8个进程,那么应该是1+7,永远有一个进程在工作,因为有一个叫做守护进程,它会去检测其他进程的信息,看其他的进程是否是存活的,是否为繁忙的。所以启动之后是1守护+7空闲。
那么我们设置了,空闲的进程区间为5-20,我们的空闲进程为7,在区间范围内,满足要求。
那么为啥我们有1+8呢?甚至有的是1+10。其实是有的进程不知道啥时候启动了,有时候有些瞬间,我们有些情况下会变成4个繁忙,4个空闲,而我们最小的空闲为5,那么就会多起一个进程来保证空闲进程数够。就会变成4+5,那么等繁忙的进程变为1,就会变成1+8。apache都是预派的模式,是我进程不够么?不是,我有4个空闲的呢,但是4个空闲的并不满足我的最小要求,怕突然来个大量请求,我满足不了,所以怎样?一旦不满足最小为5的要求,后台赶紧先满足5的最小要求,会启动进程。这就是预派生。所以这情况是正常的,可能是预派生多余了一个进程,但是又不工作,所以多起的那个进程进了idle内,就变成了1+8。
情况1:start为50,空闲区间为5-20,会有啥情况?
50=1+49,49>5,满足最小要求,49>20,所以,idle会杀掉为20。最后应该为1+20左右。我们看到结果:由于手速不够快,只能截图到这样:应该从2+28,有一个进程应该是在杀进程。一直杀进程到1+19。
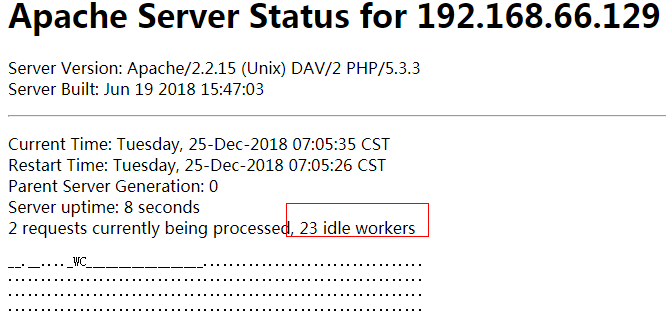
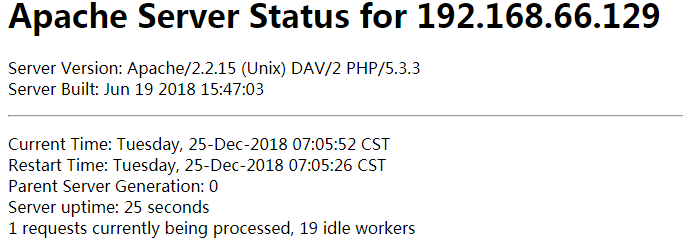
最后平稳下来为1+19个进程,我们可以看一下:apache 有20个进程
1 # ps -ef|grep httpd |grep -v grep 2 root 4402 1 0 07:05 ? 00:00:01 /usr/sbin/httpd 3 apache 4404 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 4 apache 4407 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 5 apache 4408 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 6 apache 4413 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 7 apache 4414 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 8 apache 4418 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 9 apache 4420 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 10 apache 4421 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 11 apache 4422 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 12 apache 4423 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 13 apache 4424 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 14 apache 4425 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 15 apache 4426 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 16 apache 4427 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 17 apache 4428 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 18 apache 4429 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 19 apache 4430 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 20 apache 4431 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 21 apache 4432 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd 22 apache 4433 4402 0 07:05 ? 00:00:00 /usr/sbin/httpd
我们接着看,网页内:
1 Scoreboard Key: 2 "_" Waiting for Connection, "S" Starting up, "R" Reading Request, 3 "W" Sending Reply, "K" Keepalive (read), "D" DNS Lookup, 4 "C" Closing connection, "L" Logging, "G" Gracefully finishing, 5 "I" Idle cleanup of worker, "." Open slot with no current process
- "_"是等待链接
- “S”是初始化状态,一般看不到
- “R”是已经建立了链接,在读请求的过程(在读请求,意味着在排队)
- “W”是进程接受完,在返回
- “K”进程是在长链接状态
- “D”进程处于DNS解析状态
- “C”是进程链接已完成,请求也发送完成了,在关闭链接的状态
- “L”是进程在写日志操作
- “G”是优雅地完成,意思是退出了
- “I”是杀空闲进程,我们刚刚就有杀空闲进程的操作
- “.”是连进程都没起
我们刷新,看W是在进程内切换的,说明请求是轮询的,所以在进程内切换。因为我们没用keep-alive,肯定会轮询的
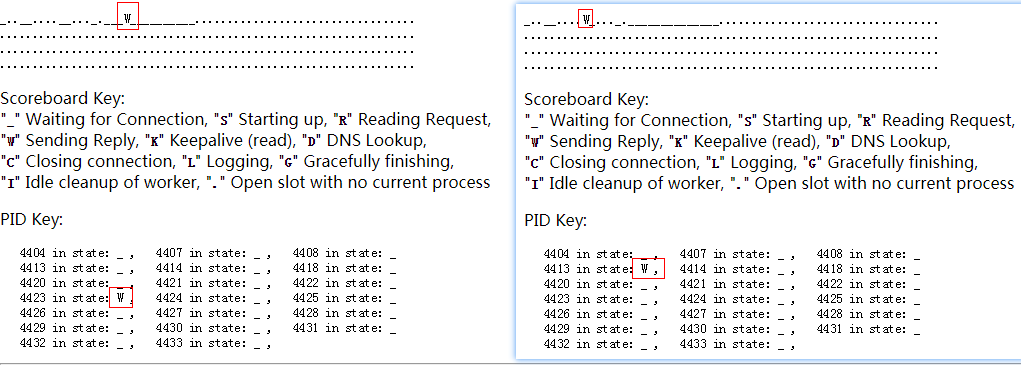
那我们看一下,用jmeter进行压测看一下,进程的状态变化,就起10个并发好了:
可以看到,有很多的C和W状态,其实还有R,我没截到图

接下来我起,50个并发看看,瞬间爆炸:idle都为0了,说明进程不够了,请求肯定就排队了,空闲都特娘的没有了
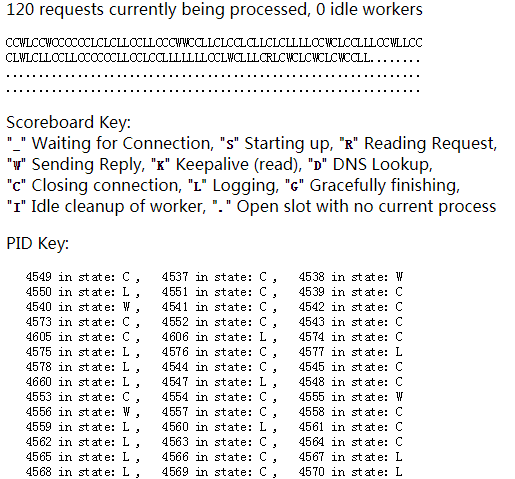
看下cpu:平均负载都上天了,us和sy加起来也75,而且mmp的linux巨慢
1 # top 2 top - 07:44:16 up 7:02, 2 users, load average: 72.83, 18.95, 7.88 3 Tasks: 319 total, 7 running, 312 sleeping, 0 stopped, 0 zombie 4 Cpu(s): 32.5%us, 43.2%sy, 0.0%ni, 0.0%id, 0.0%wa, 6.4%hi, 17.9%si, 0.0%st
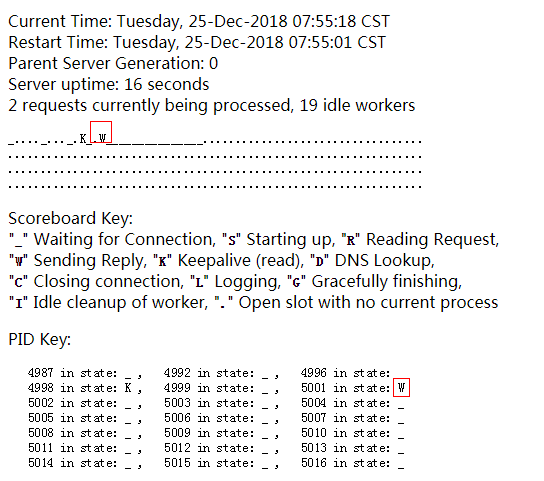
我们的keep-alive是没开启的,接下来,我们开启下keepalive看看:W的进程在一段时间内是不会变化的,因为我们设置了长链接时间
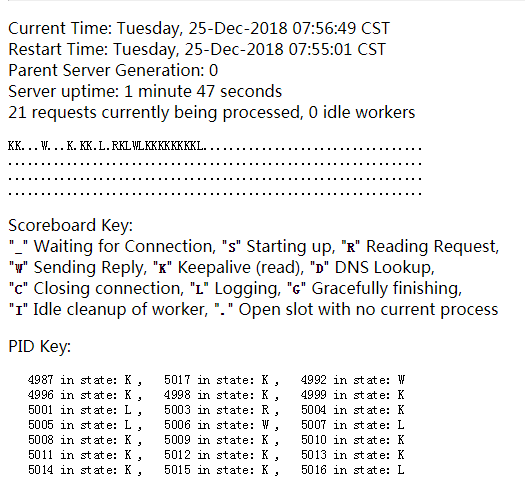
接下来,我们开10个并发:发现很多KKK,这就是keepalive,进程的连接通道的alive
想看到每个进程的详细信息,可以将 http.conf 内的 ExtendedStatus On 注释取消掉,可以看到每个进程的消耗CPU等

总结:有没有排队:看idle数是否小于我们设置的最小空闲数,我们的例子里面就是5;R和W最好一半一半,如果哪个多,说明哪个就有问题,多就意味着在排队
WORKER
Worker模式是多进程多线程模式,使用多个子进程,每个子进程有多个线程。每个线程在某个确定的时间只能维持一个连接。通常来说,在一个高流量的HTTP服务器上Worker MPM是个比较好的选择,因为WorkerMPM的内存使用比Prefork MPM要低得多。但worker MPM也由不完善的地方,假如一个线程崩溃,整个进程就会连同其任何线程一起"死掉".由于线程共享内存空间,所以一个程式在运行时必须被系统识别为"每 个线程都是安全的"。
多进程多线程
怎么换worker模式???
将/user/sbin下的httpd先换成其他名字,比如:httpd.prefork,在把httpd.worker变成httpd
mv httpd httpd.prefork
mv httpd.worker httpd
改成work模式后,重启apache可能会报错,如下图:

解决方案:安装php-zts
yum -y install php-zts
则成功:

看一下工作模式:
# httpd -l Compiled in modules: core.c worker.c http_core.c mod_so.c
说明模式切换完成
那么假设不是yum的,怎么安装成worker呢?
如果在编译时候不指定,系统默认的是prefork模式。如果需要换成worker模式,需要在编译的时候带上编译参数:--with-mpm=worker
查看apache用的是那种工作模式:在apache安装目录的bin目录下运行:apachectl -l或者httpd -l,如下图:
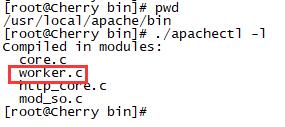
从图中可以看出apache是work模式
配置文件的内容:
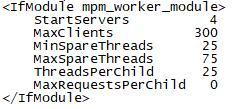
1 # worker MPM 2 # StartServers: initial number of server processes to start 3 # MaxClients: maximum number of simultaneous client connections 4 # MinSpareThreads: minimum number of worker threads which are kept spare 5 # MaxSpareThreads: maximum number of worker threads which are kept spare 6 # ThreadsPerChild: constant number of worker threads in each server process 7 # MaxRequestsPerChild: maximum number of requests a server process serves 8 <IfModule worker.c> 9 StartServers 4 ##初始化起几个进程 10 MaxClients 300 ##允许排队的最大链接数,超过300丢弃 11 MinSpareThreads 25 ##最小线程数 12 MaxSpareThreads 75 ##最大线程数 13 ThreadsPerChild 25 ##每个进程下多少个线程 14 MaxRequestsPerChild 0 ##每个进程处理多少个请求就杀死,0代表永远不杀。线程模式杀进程?可能这进程下的其他线程在工作,杀了其他的线程不就完蛋了,所以这里设定为0 15 </IfModule>
ServerLimit 50
//服务器允许配置的进程数上限。值必须大于等于MaxClients/ThreadsPerChild。这个指令和ThreadLimit结合使用配置了MaxClients最大允许配置的数值。任何在重启期间对这个指令的改变都将被忽略,但对MaxClients的修改却会生效。
ThreadLimit 200
//每个子进程可配置的线程数上限。这个指令配置了每个子进程可配置的线程数ThreadsPerChild上限。该值应该跟ThreadsPerChild可能达到的最大值保持一
致,ThreadLimit >= ThreadsPerChild。任何在重启期间对这个指令的改变都将被忽略,但对ThreadsPerChild的修改却会生效。
StartServers 5
//服务器启动时建立的子进程数。
MinSpareThreads 25
//最小空闲线程数, 这个MPM将基于整个服务器监控空闲线程数。假如服务器中总的空闲线程数太少,子进程将产生新的空闲线程。
MaxSpareThreads 500
//配置最大空闲线程数。默认值是"250"。这个MPM将基于整个服务器监控空闲线程数。假如服 务器中总的空闲线程数太多,子进程将杀死多余的空闲线程MaxSpareThreads的取值范围是有限制的。Apache将按照如下限制自动修正您配置
MaxClients 5000
//允许同时伺服的最大接入请求数量(最大线程数量)。任何超过MaxClients限制的请求都将进入等候 队列。因此要增加MaxClients的时候,您必须同时增加 ServerLimit的值。计算公式:MaxClients<=ServerLimit *ThreadsPerChild,将初始值设为(以Mb为单位的最大物理内存/2),然后根据负载情况进行动态调整。比如一台4G内存的机器,那么初始值就是4000/2=2000
ThreadsPerChild 100
//每个子进程建立的常驻的执行线程数,子进程在启动时建立这些线程后就不再建立新的线程了。
MaxRequestsPerChild 0
//配置每个子进程在其生存期内允许伺服的最大请求数量。到达MaxRequestsPerChild的限制后,子进程将会结束。假如MaxRequestsPerChild为"0",子进程将永远不会结束。
将MaxRequestsPerChild配置成非零值有两个好处:
1.能够防止(偶然的)内存泄漏无限进行,从而耗尽内存。
2.给进程一个有限寿命,从而有助于当服务器负载减轻的时候减少活动进程的数量。
注意:对于KeepAlive链接,只有第一个请求会被计数。
工作方式:
每个进程能够拥有的线程数量是固定的。服务器会根据负载情况增加或减少进程数量。一个单独的控制进程(父进程)负责子进程的建 立。每个子进程能够建立
ThreadsPerChild数量的服务线程和一个监听线程,该监听线程监听接入请求并将其传递给服务线程处理和应答。Apache总是试图维持一个备 用(spare)或是空闲的服务线程池。这样,客户端无须等待新线程或新进程的建立即可得到处理。在Unix中,为了能够绑定80端口,父进程一般都是以 root身份启动,随后,Apache以较低权限的用户建立子进程和线程。User和Group指令用于配置Apache子进程的权限。虽然子进程必须对 其提供的内容拥有读权限,但应该尽可能给予他较少的特权。另外,除非使用了suexec ,否则,这些指令配置的权限将被CGI脚本所继承。
公式:
ThreadLimit >= ThreadsPerChild
MaxClients = MinSpareThreads+ThreadsPerChild
硬限制:
ServerLimi和ThreadLimit这两个指令决定了活动子进程数量和每个子进程中线程数量的硬限制。要想改变这个硬限制必须完全停止服务器然后再启动服务器(直接重启是不行的)。
Apache在编译ServerLimit时内部有一个硬性的限制,您不能超越这个限制。
prefork MPM最大为"ServerLimit 200000"
其他MPM(包括work MPM)最大为"ServerLimit 20000
Apache在编译ThreadLimit时内部有一个硬性的限制,您不能超越这个限制。
mpm_winnt是"ThreadLimit 15000"
其他MPM(包括work prefork)为"ThreadLimit 20000
注意:
使用ServerLimit和ThreadLimit时要特别当心。假如将ServerLimit和ThreadLimit配置成一个高出实际需要许多的值,将会有过多的共享内存被分配。当配置成超过系统的处理能力,Apache可能无法启动,或系统将变得不稳定。
所以,我们不难理解,初始化是多少个线程?4*25=100个线程,这里面有1个busy,99个idle,那么99>75,所以会杀线程,杀线程不是说杀24个线程,是以进程为单位杀的,杀1个进程,减去25个线程,所以99-25=74,25<74<75.所以会变成1个busy,74个左右的idle.稳定下来应该是1+74
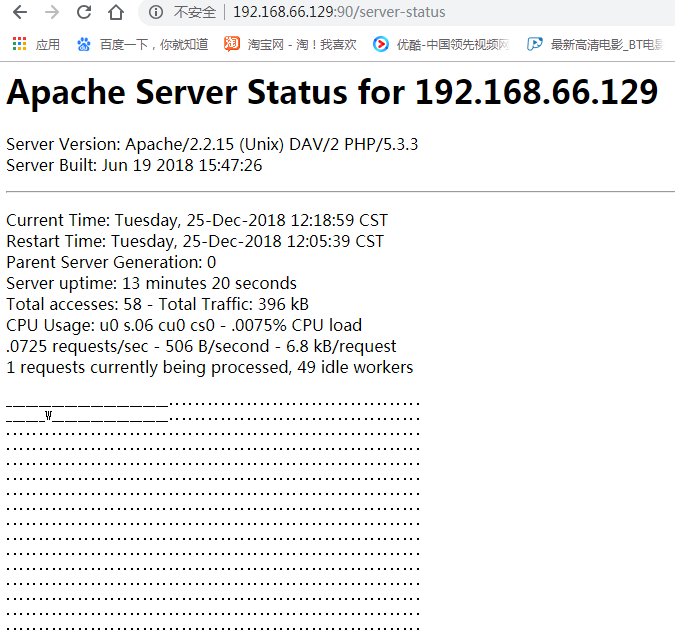
这里应该是误杀了一个线程,25<49<75,也是符合规则的,这个应该可以理解为最小原则?还是说有其他的原因?这个得研究一哈
我们可以试着想一下,如果我将:StartServers 1,初始化进程设为1,那么busy为几?idle为几?
一开始应该是1个busy,24个idle,但是24个idle< 25,那么会再起一个线程,所以会变成1个busy,49个idle

那么我们举一个比较极端的例子:
<IfModule worker.c> StartServers 1 MaxClients 300 MinSpareThreads 25 MaxSpareThreads 25 ThreadsPerChild 25 MaxRequestsPerChild 0 </IfModule>
为啥说它极端呢?一开始起1个进程,里面有25个线程,那么会变成1个busy,24个idle,那么就会再起一个进程,变成1个busy,49个idle;49>25,那么会杀一个进程变成24,变成1个busy,24个idle;如此循环往复杀进程起进程?但实际情况真的如此么?实际上
稳定下来会变成:1个busy,49个dile
为啥呢?因为这时候 MaxSpareThreads 25 这个会失效,默认进程数会+1,所以会变成1个busy,49个idle

总结:worker是多进程多线程模式的,杀跟起都是以进程为单位,空闲线程要在范围内,排队也是一个标准,idle为0或者小于空闲的最小值
Worker模式监控
(1)第一种情况
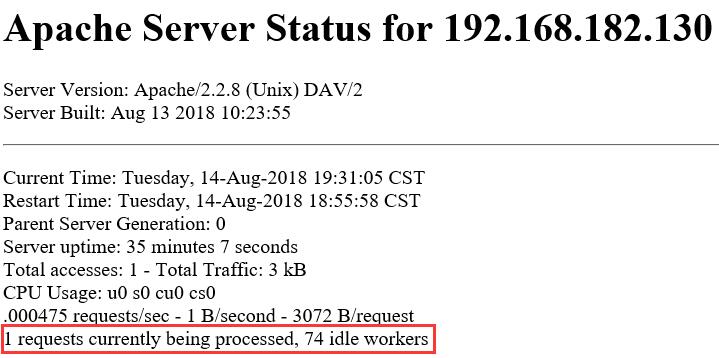
初始化4*25=100大于MaxSpareThreads的75,所以要杀掉一个进程,即25个线程,所以最后剩100-25=75,再减掉一个监听线程,最后剩74个空闲线程
(2)第二种情况
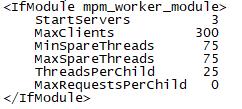
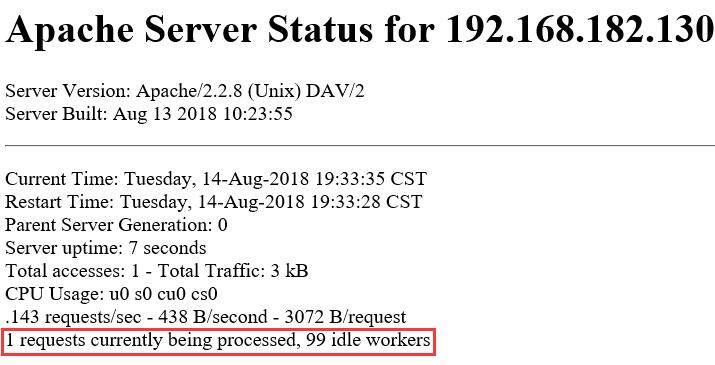
初始化3*25=75,即1个守护线程,74个空闲线程,由于小于MinSpareThreads的75,需要再启动一个进程即25个线程,所以最后是1个守护线程,99个空闲线程。有人会问99大于MaxSpareThreads的75,这项不符合。这是因为当实际线程数再校验MinSpareThreads和MaxSpareThreads冲突时,MaxSpareThreads这项配置就失效了,以MinSpareThreads为准
(3)第三种情况
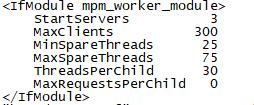
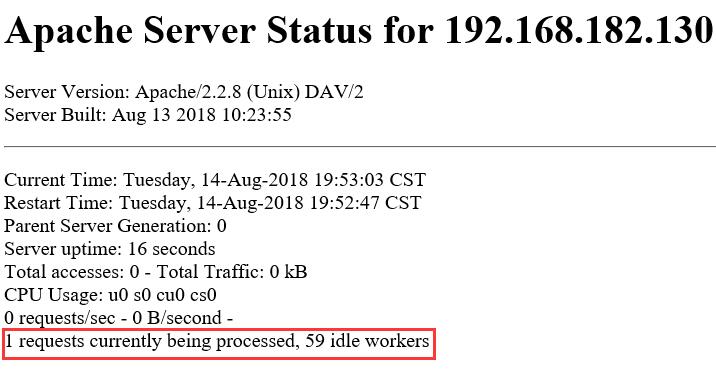
初始化3*30=90,1个守护,89空闲,大于MaxSpareThreads的75,所以要杀掉1个进程即30个线程,最后剩余1个守护,59空闲
(4)第四种情况
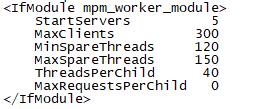
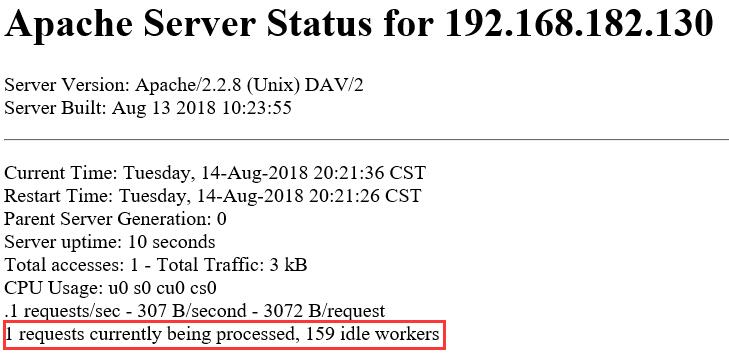
初始化5*40=200,1个守护,199个空闲,大于MaxSpareThreads的150,杀掉一个进程即40个线程,空闲还有159,还是大于MaxSpareThreads的150,再杀一个进程,空闲变为119,这时却比MinSpareThreads的值还小,再启动一个进程变为空闲变为159又大于MaxSpareThreads,这时就冲突了,MaxSpareThreads就失效了,所以最终是1个守护,159个空闲
总结:
如何合理配置apache
1、空闲进程/空闲线程
要根据实际情况来配置,是要保证并发数,还是要减少内存消耗。如果说系统在大部分时间对并发量要求不高,初始化的的进程/线程数就可以设置的比较少。如果大部分时间系统对并发量要求很高,初始化进程/线程数就可以多配置一点,以免进程/线程频繁的启动和被杀掉,这样更容易消耗系统资源。
2、长连接及其超时时间
如果用户操作比较频繁,长连接及其超时时间就配大一点,这样就不会频繁的去占用线程和释放线程。如果用户操作不频繁,这时就需要把长连接及其超时时间调小。
3、压测过程的调试
如果压测过程种发现busy进程/线程数多,空闲进程/线程数少,说明进程/线程都处于比较繁忙状态,通过与初始化的值比较,看看是否需要增大初始化的进程/线程数,以避免频繁的启动和杀进程/线程。反之,如果busy进程/线程数少,空闲进程/线程数多,则需要调小初始化的值,因为空闲进程/线程数多的话会浪费内存。
响应时间慢,就要考虑中间件线程池是否有排队情况,线程池是否有频繁的创建销毁情况。
4、是否开启gzip压缩(压缩文件图片等)
5、一个进程下面的子线程不宜配置过多,进程下面的一个线程出错可能导致整个进程报错从而导致该进程下的所有线程都不可用。一般一个进程下配置的线程数不要超过250,基本配置从25~250
Tomcat
一、配置文件
路径是在tomcat下的 /conf 文件夹内

二、进行监听:
tomcat分版本,toncat7比较简单,我这里用的是toncat9,会有些问题,但是可以百度解决。首先进入tomcat页面,点击 “Server Status”,会出现一个登录页面

这里,我们并不知道用户名字和密码是啥,点击“取消”,弹出一个页面,这个页面是配置用户名密码的一个简单说明,这里就比较坑爹了,因为各版本不一样
假设,我们要配置manager-gui的规则,用户名为:tomcat,密码为:secret,要在 conf/tomcat-user.xml 内添加啊这两行:
<role rolename="manager-gui"/> <user username="tomcat" password="secret" roles="manager-gui"/>
那我们去加加看:这里要注意,不要把这两行加到注释里面去了(xml的注释是:<!--内容-->)

然后重启 tomcat ,会发现 点击“Server Status”,会直接跳到 403
解决办法:把 tomcat 下的 /webapps/manager/META-INF/context.xml 内的这一块注释掉
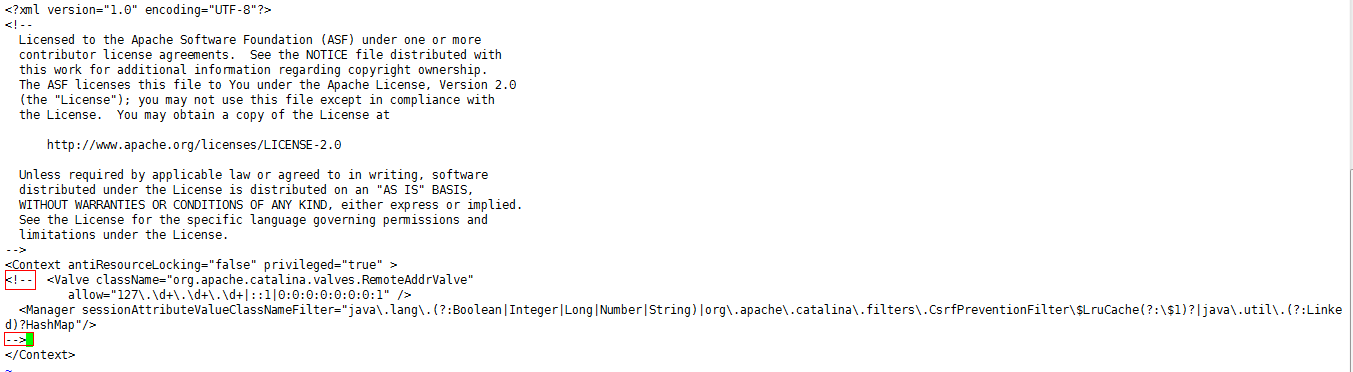
再重启 tomcat ,就ok,用刚刚配置的 Manager App 按照我们刚刚设定的账号密码,登陆进去:
页面显示如下:
这里我们选择:Complete Server Status 但是这里的数据很少,按道理讲tomcat 7不会这样,“ajp-nio-8099”数据为空
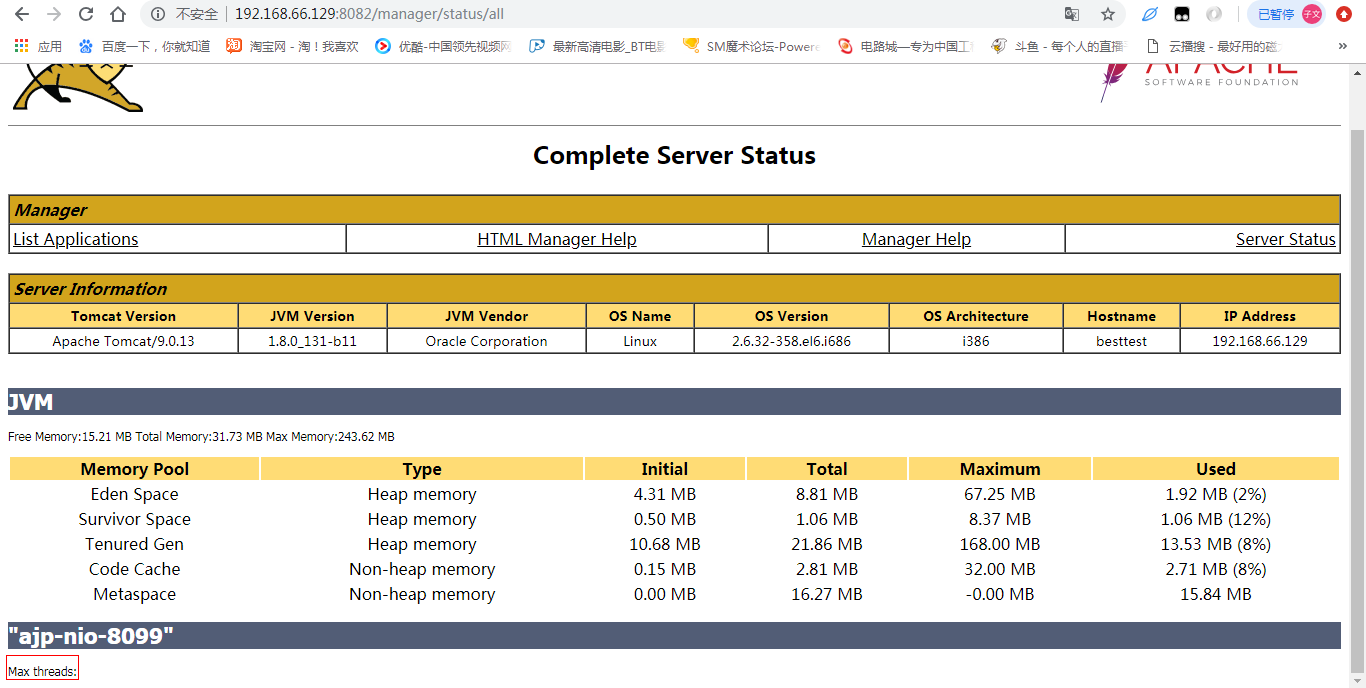
解决方案:暂无
bio和nio和APR
是tomcat的两个工作模式,tomcat7默认是bio模式,tomcat8以及以上默认是nio的模式。 bio 是最低效率的模式,最少换成 nio 的工作模式
bio:同步模式,阻塞模式,一个线程处理一个请求
nio:利用java的异步io模式,可以通过少量线程处理大量的请求,可减少线程处理请求的等待,tomcat 7要修改 server.xml 文件
<Connector port="8082"protocol="org.apache.coyote.http11.Http11NioProtocol" connectionTimeout="20000" redirectPort="8443" />
apr:Linux需要安装apr和native,这个是利用操作系统的异步io模式去解决io的阻塞问题
Max threads:最大线程数。
Current thread count:最近运行的线程数。 Max processing time:最大CPU时间。 Processing time:CPU消耗总时间。 Request count:请求总数。
Error count:错误的请求数。
Bytes received:接收字节数。
Bytes sent:发送字节数。
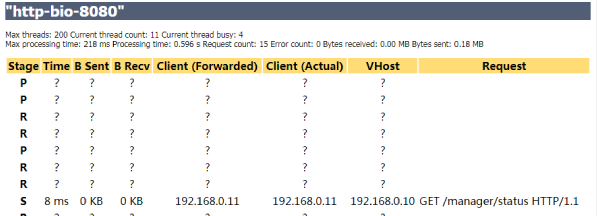
Max thread:默认200
Current thread count :当前8个线程,busy繁忙 1 个,keep alive 长链接的socket 为1个
Max processing time:最长的处理时间:63ms。有空去了解下这几个配置之间的区别
。
不难看出,busy的线程接近于Max threads 的情况下,就会有瓶颈
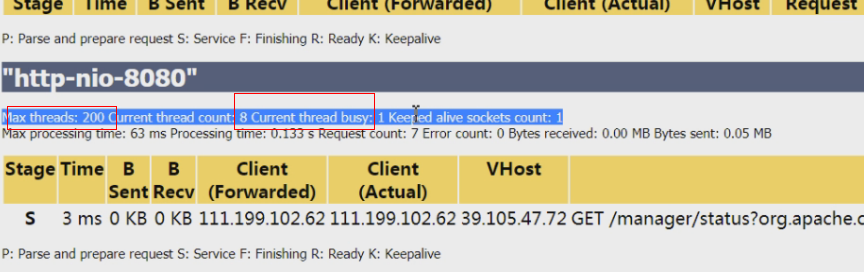
K:长链接,R:Ready(线程刚刚初始化),F:刚刚处理完请求,S:还在服务中,P:准备接收请求(已经接收到请求,准备解析请求)
三、tomcat目录结构
不管是apache还是tomcat都是web的容器,容器干吗用的?运行程序用的,也就是代码的工程包扔到其工程路径内。apache运行的是php的程序,tomcat运行的是java的程序,nginx运行的是C和php的程序都行。
那tomcat的工程路径是哪?在webapps下面,yum安装的apache的工程路径则是在 /var/www/ 内。
tomcat的 start.sh 其实启动的就是 catalina.sh ,是个shell文件,看不懂就算了。。。
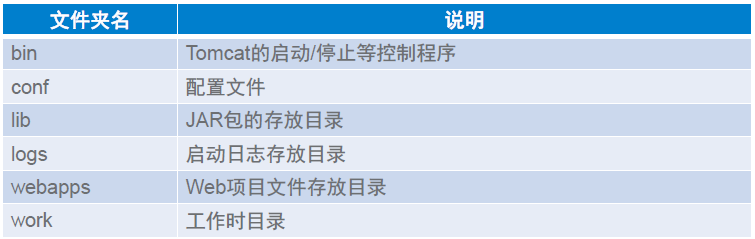
lib内的jar包,logs内是日志,webapps内是工程文件,conf内是配置文件
- /bin:存放windows或Linux平台上启动和关闭Tomcat的脚本文件
- /conf:存放Tomcat服务器的各种全局配置文件,其中最重要的是server.xml和web.xml
- /doc:存放Tomcat文档
- /server:包含三个子目录:classes、lib和webapps
- /server/lib:存放Tomcat服务器所需的各种JAR文件
- /server/webapps:存放Tomcat自带的两个WEB应用admin应用和 manager应用
- /common/lib:存放Tomcat服务器以及所有web应用都可以访问的jar文件
- /shared/lib:存放所有web应用都可以访问的jar文件(但是不能被Tomcat服务器访问)
- /logs:存放Tomcat执行时的日志文件
- /src:存放Tomcat的源代码
- /webapps:Tomcat的主要Web发布目录,默认情况下把Web应用文件放于此目录
- /work:存放JSP编译后产生的class文件
tomcat的配置文件一般都在conf目录下,主要有server.xml,context.xml,tomcat_user.xml,web.xml四个常用配置文件。
(1)server.xml主要是服务器设置的,例如端口设置,路径设置
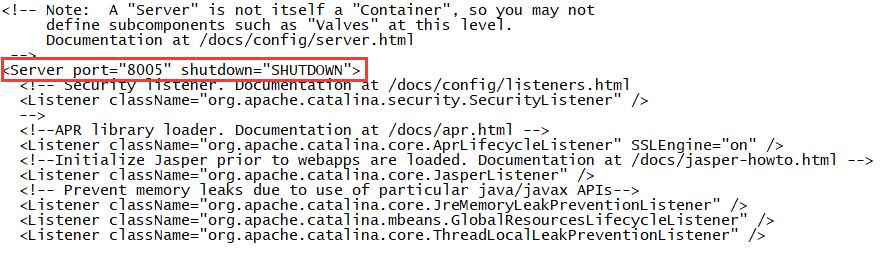
tomcat的停止命令的端口号,通过这个端口号可以关闭tomcat。若设置为-1,则禁止通过端口关闭tomcat,同时shutdown.bat和shutdown.sh就不能使用了。

启用tomcat线程池,和下面的Connector对应
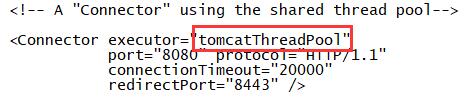
tomcat工程路径,项目放在这个目录下

这里我们主要是看一下server.xml内的东西
|
元素名 |
属性 |
解释 |
|
server |
port |
指定一个端口,这个端口负责监听关闭tomcat的请求 |
|
shutdown |
指定向端口发送的命令字符串 |
|
|
service |
name |
指定service的名字 |
|
Connector(表示客户端和service之间的连接) |
port |
指定服务器端要创建的端口号,并在这个断口监听来自客户端的请求 |
|
minProcessors |
服务器启动时创建的处理请求的线程数 |
|
|
maxProcessors |
最大可以创建的处理请求的线程数 |
|
|
enableLookups |
如果为true,则可以通过调用request.getRemoteHost()进行DNS查询来得到远程客户端的实际主机名,若为false则不进行DNS查询,而是返回其ip地址 |
|
|
redirectPort |
指定服务器正在处理http请求时收到了一个SSL传输请求后重定向的端口号 |
|
|
acceptCount |
指定当所有可以使用的处理请求的线程数都被使用时,可以放到处理队列中的请求数,超过这个数的请求将不予处理 |
|
|
connectionTimeout |
指定超时的时间数(以毫秒为单位) |
|
|
Engine(表示指定service中的请求处理机,接收和处理来自Connector的请求) |
defaultHost |
指定缺省的处理请求的主机名,它至少与其中的一个host元素的name属性值是一样的 |
|
Context(表示一个web应用程序,通常为WAR文件,关于WAR的具体信息见servlet规范) |
docBase |
应用程序的路径或者是WAR文件存放的路径 |
|
path |
表示此web应用程序的url的前缀,这样请求的url为http://localhost:8080/path/**** |
|
|
reloadable |
这个属性非常重要,如果为true,则tomcat会自动检测应用程序的/WEB-INF/lib 和/WEB-INF/classes目录的变化,自动装载新的应用程序,我们可以在不重起tomcat的情况下改变应用程序 |
|
|
host(表示一个虚拟主机) |
name |
指定主机名 |
|
appBase |
应用程序基本目录,即存放应用程序的目录 |
|
|
unpackWARs |
如果为true,则tomcat会自动将WAR文件解压,否则不解压,直接从WAR文件中运行应用程序 |
|
|
Logger(表示日志,调试和错误信息) |
className |
指定logger使用的类名,此类必须实现org.apache.catalina.Logger 接口 |
|
prefix |
指定log文件的前缀 |
|
|
suffix |
指定log文件的后缀 |
|
|
timestamp |
如果为true,则log文件名中要加入时间,如下例:localhost_log.001-10-04.txt |
|
|
Realm(表示存放用户名,密码及role的数据库) |
className |
指定Realm使用的类名,此类必须实现org.apache.catalina.Realm接口 |
|
Valve(功能与Logger差不多,其prefix和suffix属性解释和Logger 中的一样) |
className |
指定Valve使用的类名,如用org.apache.catalina.valves.AccessLogValve类可以记录应用程序的访问信息 |
|
directory |
指定log文件存放的位置 |
|
|
pattern |
有两个值,common方式记录远程主机名或ip地址,用户名,日期,第一行请求的字符串,HTTP响应代码,发送的字节数。combined方式比common方式记录的值更多 |
maxThreads:Tomcat线程池最多能起的线程数;
maxConnections:Tomcat瞬间最多能并发处理的请求(连接);
acceptCount:Tomcat维护最大的队列数(当所有可以使用的处理请求的线程数都被使用时,可以放到处理队列中的请求数,超过这个数的请求将不予处理);
minSpareThreads:Tomcat初始化的线程池大小或者说Tomcat线程池最少会有这么多线程
比较容易弄混的是maxThreads和maxConnections这两个参数:
比如maxThreads=1000,maxConnections=800,假设某一瞬间的并发时1000,那么最终Tomcat的线程数将会是800,即同时处理800个请求,剩余200进入队列“排队”,如果acceptCount=100,那么有100个请求会被拒掉。
注意:根据前面所说,只是并发那一瞬间Tomcat会起800个线程处理请求,但是稳定后,某一瞬间可能只有很少的线程处于RUNNABLE状态,大部分线程是TIMED_WAITING,如果你的应用处理时间够快的话。所以真正决定Tomcat最大可能达到的线程数是maxConnections这个参数和并发数,当并发数超过这个参数则请求会排队,这时响应的快慢就看你的程序性能了。
并发的概念:不管什么并发肯定是有一个时间单位的(一般是1s),准确的来讲应该是当时Tomcat处理一个请求的时间内并发数,比如当时Tomcat处理某一个请求花费了1s,那么如果这1s过来的请求数达到了3000,那么Tomcat的线程数就会为3000,maxConnections只是Tomcat做的一个限制。
Nginx
两个配置文件
uer nginx nginx ;#Nginx用户及组:用户 组。window下不指定 worker_processes 8;#工作进程:数目。根据硬件调整,通常等于CPU数量。 #error_log logs/error.log notice; error_log logs/error.log info; pid logs/nginx.pid; worker_rlimit_nofile 204800;#指定进程可以打开的最大描述符:数目。 -n)与nginx进程数相除,但是nginx分配请求并不是那么均匀,所以最好与ulimit -n 的值保持一致。现在在Linux 2.6内核下开启文件打开数为65535,worker_rlimit_nofile就相应应该填写65535。这是因为nginx调度时分配请求到进程并不是那么的均衡,所以假如填写10240,总并发量达到3-4万时就有进程可能超过10240了,这时会返回502错误。 events { use epoll;#使用epoll的I/O 模型。linux建议epoll,FreeBSD建议采用kqueue,window下不指定。 补充说明: 与apache相类,nginx针对不同的操作系统,有不同的事件模型 A)标准事件模型 Select、poll属于标准事件模型,如果当前系统不存在更有效的方法,nginx会选择select或poll B)高效事件模型 Kqueue:使用于FreeBSD 4.1+, OpenBSD 2.9+, NetBSD 2.0 和 MacOS X.使用双处理器的MacOS X系统使用kqueue可能会造成内核崩溃。 Epoll:使用于Linux内核2.6版本及以后的系统。 Eventport:使用于Solaris 10。 为了防止出现内核崩溃的问题, 有必要安装安全补丁。 worker_connections 204800;#没个工作进程的最大连接数量。根据硬件调整,和前面工作进程配合起来用,尽量大,但是别把cpu跑到100%就行。每个进程允许的最多连接数,理论上每台nginx服务器的最大连接数为。worker_processes*worker_connections keepalive_timeout 60;#keepalive超时时间。 client_header_buffer_size 4k;#客户端请求头部的缓冲区大小。这个可以根据你的系统分页大小来设置,一般一个请求头的大小不会超过1k,不过由于一般系统分页都要大于1k,所以这里设置为分页大小。分页大小可以用命令getconf PAGESIZE 取得。但也有client_header_buffer_size超过4k的情况,但是client_header_buffer_size该值必须设置为“系统分页大小”的整倍数。 open_file_cache max=65535 inactive=60s;#这个将为打开文件指定缓存,默认是没有启用的,max指定缓存数量,建议和打开文件数一致,inactive是指经过多长时间文件没被请求后删除缓存。 open_file_cache_valid 80s;#这个是指多长时间检查一次缓存的有效信息。 open_file_cache_min_uses 1;#open_file_cache指令中的inactive参数时间内文件的最少使用次数,如果超过这个数字,文件描述符一直是在缓存中打开的,如上例,如果有一个文件在inactive时间内一次没被使用,它将被移除。 } ##负载均衡配置 upstream bakend { server 127.0.0.1:8027; server 127.0.0.1:8028; server 127.0.0.1:8029; hash $request_uri; } nginx的upstream目前支持5种方式的分配 1、轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。 2、weight 指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。 例如: upstream bakend { server 192.168.0.14 weight=80; server 192.168.0.15 weight=10; } 3、ip_hash 每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。 例如: upstream bakend { ip_hash; server 192.168.0.14:88; server 192.168.0.15:80; } 4、fair(第三方) 按后端服务器的响应时间来分配请求,响应时间短的优先分配。 upstream backend { server server1; server server2; fair; } 5、url_hash(第三方) 按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。 例:在upstream中加入hash语句,server语句中不能写入weight等其他的参数,hash_method是使用的hash算法 upstream backend { server squid1:3128; server squid2:3128; hash $request_url; hash_method crc32; } upstream bakend{#定义负载均衡设备的Ip及设备状态}{ ip_hash; server 127.0.0.1:9090 down; server 127.0.0.1:8080 weight=2; server 127.0.0.1:6060;max_fails:10 fail_timeout:10 server 127.0.0.1:7070 backup; } 在需要使用负载均衡的server中增加 proxy_pass http://bakend/; 每个设备的状态设置为: 1.down表示单前的server暂时不参与负载 2.weight为weight越大,负载的权重就越大。 3.max_fails:允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream模块定义的错误 4.fail_timeout:max_fails次失败后,暂停的时间。 5.backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。 nginx支持同时设置多组的负载均衡,用来给不用的server来使用。 client_body_in_file_only设置为On 可以讲client post过来的数据记录到文件中用来做debug client_body_temp_path设置记录文件的目录 可以设置最多3层目录 location对URL进行匹配.可以进行重定向或者进行新的代理 负载均衡 ##设定http服务器,利用它的反向代理功能提供负载均衡支持 http { server_tokens off; #并不会让nginx执行的速度更快,但它可以关闭在错误页面中的nginx版本数字,这样对于安全性是有好处的。 sendfile on; #可以让sendfile()发挥作用。sendfile()可以在磁盘和TCP socket之间互相拷贝数据(或任意两个文件描述符)。Pre-sendfile是传送数据之前在用户空间申请数据缓冲区。之后用read()将数据从 文件拷贝到这个缓冲区,write()将缓冲区数据写入网络。sendfile()是立即将数据从磁盘读到OS缓存。因为这种拷贝是在内核完成 的,sendfile()要比组合read()和write()以及打开关闭丢弃缓冲更加有效(更多有关于sendfile)。 tcp_nopush on; # 告诉nginx在一个数据包里发送所有头文件,而不一个接一个的发送。 tcp_nodelay on; # 告诉nginx不要缓存数据,而是一段一段的发送--当需要及时发送数据时,就应该给应用设置这个属性,这样发送一小块数据信息时就不能立即得到返回值。 keepalive_timeout 10; #给客户端分配keep-alive链接超时时间。服务器将在这个超时时间过后关闭链接。我们将它设置低些可以让ngnix持续工作的时间更长。 client_header_timeout 10;# 设置请求头和请求体(各自)的超时时间。我们也可以把这个设置低些。 client_body_timeout 10; # reset_timedout_connection on; #告诉nginx关闭不响应的客户端连接。这将会释放那个客户端所占有的内存空间 send_timeout 10; #指定客户端的响应超时时间。这个设置不会用于整个转发器,而是在两次客户端读取操作之间。如果在这段时间内,客户端没有读取任何数据,nginx就会关闭连接。 gzip on; #是告诉nginx采用gzip压缩的形式发送数据。这将会减少我们发送的数据量。 gzip_disable "msie6"; #为指定的客户端禁用gzip功能。我们设置成IE6或者更低版本以使我们的方案能够广泛兼容 # gzip_static on; # 告诉nginx在压缩资源之前,先查找是否有预先gzip处理过的资源。这要求你预先压缩你的文件,从而允许你使用最高压缩比,这样nginx就不用再压缩这些文件了。 gzip_proxied any; #允许或者禁止压缩基于请求和响应的响应流。我们设置为any,意味着将会压缩所有的请求。 gzip_min_length 1000; #设置对数据启用压缩的最少字节数。如果一个请求小于1000字节,我们最好不要压缩它,因为压缩这些小的数据会降低处理此请求的所有进程的速度。 gzip_comp_level 4; #设置数据的压缩等级。这个等级可以是1-9之间的任意数值,9是最慢但是压缩比最大的。我们设置为4,这是一个比较折中的设置。 gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript; #设置需要压缩的数据格式 include mime.types; #设定mime类型,类型由mime.type文件定义 default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; log_format log404 '$status [$time_local] $remote_addr $host$request_uri $sent_http_location'; #日志格式设置。 $remote_addr与$http_x_forwarded_for用以记录客户端的ip地址; $remote_user:用来记录客户端用户名称; $time_local: 用来记录访问时间与时区; $request: 用来记录请求的url与http协议; $status: 用来记录请求状态;成功是200, $body_bytes_sent :记录发送给客户端文件主体内容大小; $http_referer:用来记录从那个页面链接访问过来的; $http_user_agent:记录客户浏览器的相关信息; 通常web服务器放在反向代理的后面,这样就不能获取到客户的IP地址了,通过$remote_add拿到的IP地址是反向代理服务器的iP地址。反向代理服务器在转发请求的http头信息中,可以增加x_forwarded_for信息,用以记录原有客户端的IP地址和原来客户端的请求的服务器地址。 access_log logs/host.access.log main; access_log logs/host.access.404.log log404;#用了log_format指令设置了日志格式之后,需要用access_log指令指定日志文件的存放路径; server_names_hash_bucket_size 128;#保存服务器名字的hash表是由指令server_names_hash_max_size 和server_names_hash_bucket_size所控制的。参数hash bucket size总是等于hash表的大小,并且是一路处理器缓存大小的倍数。在减少了在内存中的存取次数后,使在处理器中加速查找hash表键值成为可能。如果hash bucket size等于一路处理器缓存的大小,那么在查找键的时候,最坏的情况下在内存中查找的次数为2。第一次是确定存储单元的地址,第二次是在存储单元中查找键 值。因此,如果Nginx给出需要增大hash max size 或 hash bucket size的提示,那么首要的是增大前一个参数的大小. client_header_buffer_size 4k;#客户端请求头部的缓冲区大小。这个可以根据你的系统分页大小来设置,一般一个请求的头部大小不会超过1k,不过由于一般系统分页都要大于1k,所以这里设置为分页大小。分页大小可以用命令getconf PAGESIZE取得。 large_client_header_buffers 8 128k;#客户请求头缓冲大小。nginx默认会用client_header_buffer_size这个buffer来读取header值,如果header过大,它会使用large_client_header_buffers来读取。 open_file_cache max=102400 inactive=20s;#这个指令指定缓存是否启用。 client_max_body_size 300m;#设定通过nginx上传文件的大小 sendfile on;#sendfile指令指定 nginx 是否调用sendfile 函数(zero copy 方式)来输出文件,对于普通应用,必须设为on。如果用来进行下载等应用磁盘IO重负载应用,可设置为off,以平衡磁盘与网络IO处理速度,降低系统uptime。 tcp_nopush on;#此选项允许或禁止使用socke的TCP_CORK的选项,此选项仅在使用sendfile的时候使用 proxy_connect_timeout 90; #后端服务器连接的超时时间_发起握手等候响应超时时间 proxy_read_timeout 180;#连接成功后_等候后端服务器响应时间_其实已经进入后端的排队之中等候处理(也可以说是后端服务器处理请求的时间) proxy_send_timeout 180;#后端服务器数据回传时间_就是在规定时间之内后端服务器必须传完所有的数据 proxy_buffer_size 256k;#设置从被代理服务器读取的第一部分应答的缓冲区大小,通常情况下这部分应答中包含一个小的应答头,默认情况下这个值的大小为指令proxy_buffers中指定的一个缓冲区的大小,不过可以将其设置为更小 proxy_buffers 4 256k;#设置用于读取应答(来自被代理服务器)的缓冲区数目和大小,默认情况也为分页大小,根据操作系统的不同可能是4k或者8k proxy_busy_buffers_size 256k; proxy_temp_file_write_size 256k;#设置在写入proxy_temp_path时数据的大小,预防一个工作进程在传递文件时阻塞太长 proxy_temp_path /data0/proxy_temp_dir;#proxy_temp_path和proxy_cache_path指定的路径必须在同一分区 proxy_cache_path /data0/proxy_cache_dir levels=1:2 keys_zone=cache_one:200m inactive=1d max_size=30g;#设置内存缓存空间大小为200MB,1天没有被访问的内容自动清除,硬盘缓存空间大小为30GB。 keepalive_timeout 120;keepalive超时时间。 tcp_nodelay on; client_body_buffer_size 512k;#如果把它设置为比较大的数值,例如256k,那么,无论使用firefox还是IE浏览器,来提交任意小于256k的图片,都很正常。如果注释该指令,使用默认的client_body_buffer_size设置,也就是操作系统页面大小的两倍,8k或者16k,问题就出现了。 无论使用firefox4.0还是IE8.0,提交一个比较大,200k左右的图片,都返回500 Internal Server Error错误 proxy_intercept_errors on;#表示使nginx阻止HTTP应答代码为400或者更高的应答。 ##配置虚拟机 server { listen 80;#配置监听端口 server_name image.***.com;#配置访问域名 location ~* .(mp3|exe)$ {对以“mp3或exe”结尾的地址进行负载均衡 proxy_pass http://img_relay$request_uri;#设置被代理服务器的端口或套接字,以及URL proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;#以上三行,目的是将代理服务器收到的用户的信息传到真实服务器上 } location /face { if ($http_user_agent ~* "xnp") { rewrite ^(.*)$ http://211.151.188.190:8080/face.jpg redirect; } proxy_pass http://img_relay$request_uri; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; error_page 404 502 = @fetch; } location @fetch { access_log /data/logs/face.log log404; rewrite ^(.*)$ http://211.151.188.190:8080/face.jpg redirect; } location /image { if ($http_user_agent ~* "xnp") { rewrite ^(.*)$ http://211.151.188.190:8080/face.jpg redirect; } proxy_pass http://img_relay$request_uri; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; error_page 404 502 = @fetch; } location @fetch { access_log /data/logs/image.log log404; rewrite ^(.*)$ http://211.151.188.190:8080/face.jpg redirect; } } #设定Nginx状态访问地址 location /NginxStatus { stub_status on; access_log on; auth_basic "NginxStatus"; #auth_basic_user_file conf/htpasswd; } }
net.ipv4.tcp_max_tw_buckets = 6000 #timewait的数量,默认是180000。 net.ipv4.ip_local_port_range = 1024 65000 #允许系统打开的端口范围。 net.ipv4.tcp_tw_recycle = 1 #启用timewait快速回收。 net.ipv4.tcp_tw_reuse = 1 #开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接。 net.ipv4.tcp_syncookies = 1 #开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies来处理。 net.core.somaxconn = 262144 #web应用中listen函数的backlog默认会给我们内核参数的net.core.somaxconn限制到128,而Nginx内核参数定义的NGX_LISTEN_BACKLOG默认为511,所以有必要调整这个值。 net.core.netdev_max_backlog = 262144 #每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。 net.ipv4.tcp_max_orphans = 262144 #系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤儿连接将即刻被复位并打印出警告信息。这个限制仅仅是为了防止简单的DoS攻击,不能过分依靠它或者人为地减小这个值,更应该增加这个值(如果增加了内存之后)。 net.ipv4.tcp_max_syn_backlog = 262144 #记录的那些尚未收到客户端确认信息的连接请求的最大值。对于有128M内存的系统而言,缺省值是1024,小内存的系统则是128。 net.ipv4.tcp_timestamps = 0 #时间戳可以避免序列号的卷绕。一个1Gbps的链路肯定会遇到以前用过的序列号。时间戳能够让内核接受这种“异常”的数据包。这里需要将其关掉。 net.ipv4.tcp_synack_retries = 1 #为了打开对端的连接,内核需要发送一个SYN并附带一个回应前面一个SYN的ACK。也就是所谓三次握手中的第二次握手。这个设置决定了内核放弃连接之前发送SYN+ACK包的数量。 net.ipv4.tcp_syn_retries = 1 #在内核放弃建立连接之前发送SYN包的数量。 net.ipv4.tcp_synack_retries = 1#为了打开对端的连接,内核需要发送一个SYN 并附带一个回应前面一个SYN的ACK。也就是所谓三次握手中的第二次握手。这个设置决定了内核放弃连接之前发送SYN+ACK 包的数量。 net.ipv4.tcp_fin_timeout = 1 #如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。对端可以出错并永远不关闭连接,甚至意外当机。缺省值是60秒。2.2 内核的通常值是180秒,你可以按这个设置,但要记住的是,即使你的机器是一个轻载的WEB服务器,也有因为大量的死套接字而内存溢出的风险,FIN- WAIT-2的危险性比FIN-WAIT-1要小,因为它最多只能吃掉1.5K内存,但是它们的生存期长些。 net.ipv4.tcp_keepalive_time = 30 #当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时。 net.core.somaxconn = 262144#web 应用中listen 函数的backlog 默认会给我们内核参数的net.core.somaxconn限制到128,而nginx 定义的NGX_LISTEN_BACKLOG 默认为511,所以有必要调整这个值。 net.core.netdev_max_backlog = 262144#每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。 net.ipv4.tcp_max_orphans = 262144#系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤儿连接将即刻被复位并打印出警告信息。这个限制仅仅是为了防止简单的DoS攻击,不能过分依靠它或者人为地减小这个值,更应该增加这个值(如果增加了内存之后)。 net.ipv4.tcp_max_syn_backlog = 262144#记录的那些尚未收到客户端确认信息的连接请求的最大值。对于有128M内存的系统而言,缺省值是1024,小内存的系统则是128。