Linux
四大件:CPU、内存、磁盘、网络
CPU
就像人的大脑,主要负责相关事情的判断以及实际处理的机制。
CPU的性能主要体现在其运行程序的速度上。影响运行速度的性能指标包括CPU的工作频率、Cache容量、指令系统和逻辑结构等参数。
查询指令:cat /proc/cpuinfo
[root@besttest ~]# cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i5-4200H CPU @ 2.80GHz stepping : 3 cpu MHz : 2793.600 cache size : 3072 KB fdiv_bug : no hlt_bug : no f00f_bug : no coma_bug : no fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss nx pdpe1gb rdtscp lm constant_tsc up arch_perfmon pebs bts xtopology tsc_reliable nonstop_tsc aperfmperf unfair_spinlock pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm ida arat epb pln pts dts fsgsbase smep bogomips : 5587.20 clflush size : 64 cache_alignment : 64 address sizes : 40 bits physical, 48 bits virtual power management:
内存
大脑中的记忆区块,将皮肤、眼睛等所收集到的信息记录起来的地方,以供CPU进行判断。
影响内存的性能主要是内存主频、内容容量。
查询指令:cat /proc/meminfo
[root@besttest ~]# cat /proc/meminfo MemTotal: 1030684 kB MemFree: 582612 kB Buffers: 13980 kB Cached: 203776 kB SwapCached: 0 kB Active: 220116 kB Inactive: 172660 kB Active(anon): 175152 kB Inactive(anon): 828 kB Active(file): 44964 kB Inactive(file): 171832 kB Unevictable: 0 kB Mlocked: 0 kB HighTotal: 141256 kB HighFree: 280 kB LowTotal: 889428 kB LowFree: 582332 kB SwapTotal: 2064376 kB SwapFree: 2064376 kB Dirty: 28 kB Writeback: 0 kB AnonPages: 175044 kB Mapped: 35000 kB Shmem: 956 kB Slab: 38844 kB SReclaimable: 7696 kB SUnreclaim: 31148 kB KernelStack: 2328 kB PageTables: 4460 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 2579716 kB Committed_AS: 1906944 kB VmallocTotal: 122880 kB VmallocUsed: 4744 kB VmallocChunk: 104020 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB DirectMap4k: 10232 kB DirectMap2M: 897024 kB
磁盘
大脑中的记忆区块,将重要的数据记录起来,以便未来再次使用这些数据。
容量、转速、平均访问时间、传输速率、缓存。
查询指令:fdisk -l (需要root权限)
[root@besttest ~]# fdisk -l Disk /dev/sda: 21.5 GB, 21474836480 bytes 255 heads, 63 sectors/track, 2610 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x000b18c2 Device Boot Start End Blocks Id System /dev/sda1 * 1 64 512000 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 64 2611 20458496 8e Linux LVM Disk /dev/mapper/vg_besttest-lv_root: 18.8 GB, 18832424960 bytes 255 heads, 63 sectors/track, 2289 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000 Disk /dev/mapper/vg_besttest-lv_swap: 2113 MB, 2113929216 bytes 255 heads, 63 sectors/track, 257 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000
CPU、内存、磁盘有什么依赖关系么?CPU只在内存里面工作, 内存大,运行的空间越大。CPU内部也有一块缓存,但是特别小,别指望它能有大作为,CPU也可以在缓存内干活,但是大部分是在内存里面干活。内存是临时的,掉电就会被清空。关系型数据库全部存磁盘,非关系型数据库作缓存就存放在内存里面,不做缓存就放硬盘上,像redis是在内存里面,数据从哪来?从mysql里面推过来。
举个例子:我们在加工生产,有工人、车间、仓库。工人类比成CPU,干活;车间类比成车间,工人在车间内工作生产,加工的材料就是仓库里面来的,相当于从磁盘拿数据,加工完成后放进仓库,也就是将数据放入硬盘;仓库类比成硬盘,最终存放产品放在仓库,相当于往磁盘存放数据;
比如说我们数据库的update和insert一下,操作是在内存里面做的,update/insert完成后,再从内存内写入到磁盘内部,后面只是个同步过程。
断电为什么容易丢数据?因为操作是在内存里面,内存断电会被释放,还来不及同步到数据库内,所以数据库内并未做任何更改,就形成了丢数据的现场。
再比方说觉得生产效率不高,想提高效率,要从哪几方面取提升???
最快的方法是人多,也就是CPU的颗粒数增多;车间够大,能处理的物料就更多,也就是内存大;仓库大,物料多。
Linux性能监控分析命令:
- vmstat
- sar
- iostat
- top
- free
- uptime
- netstat
- ps
- strace
- lsof
CPU
1、top:看CPU使用率有没有问题(平均负载和cpu的us和sy)


top命令能够实时监控系统的运行状态,并且可以按照CPU、内存和执行时间进行排序,同时top命令还可以通过交互式命令进行设定显示,通过top命令可以查看即时活跃的进行。 命令行启动参数: 用法: top -hv | -bcisSHM -d delay -n iterations [-u user | -U user] -p pid [,pid ...] -b : 批次模式运行。通常用作来将top的输出的结果传送给其他程式或储存成文件 -c : 显示执行任务的命令行 -d : 设定延迟时间 -h : 帮助 -H : 显示线程。当这个设定开启时,将显示所有进程产生的线程 -i : 显示空闲的进程 -n : 执行次数。一般与-b搭配使用 -u : 监控指定用户相关进程 -U : 监控指定用户相关进程 -p : 监控指定的进程。当监控多个进程时,进程ID以逗号分隔。这个选项只能在命令行下使用 -s : 安全模式操作 -S : 累计时间模式 -v : 显示top版本,然后退出。 -M : 自动显示内存单位(k/M/G) 1.全局命令 回车、空格 : 刷新显示信息 ?、h : 帮助 = : 移除所有任务显示的限制 A : 交替显示模式切换 B : 粗体显示切换 d、s : 更改界面刷新时间间隔 G : 选择其它窗口/栏位组 I : Irix或Solaris模式切换 u、U : 监控指定用户相关进程 k : 结束进程 q : 退出top r : 重新设定进程的nice值 W : 存储当前设定 Z : 改变颜色模板 2.摘要区命令 l : 平均负载及系统运行时间显示开关 m : 内存及交换空间使用率显示开关 t : 当前任务及CPU状态显示开关 1 : 汇总显示CPU状态或分开显示每个CPU状态 3.任务区命令 外观样式 b : 黑体/反色显示高亮的行/列。控制x和y交互命令的显示样式 x : 高亮显示排序的列 y : 高亮显示正在运行的任务 z : 彩色/黑白显示。 显示内容 c : 任务执行的命令行或进程名称 f、o : 增加和移除进程信息栏位及调整进程信息栏位显示顺序 H : 显示线程 S : 时间累计模式 u : 监控指定用户相关进程 任务显示的数量 i : 显示空闲的进程 n或# : 设置任务显示最大数量 任务排序(shift+f) M : 按内存使用率排序 N : 按PID排序 P : 按CPU使用率排序 T : 按Time+排序 < : 按当前排序栏位左边相邻栏位排序 > : 按当前排序栏位右边相邻栏位排序 F 或 O : 选择排序栏位 R : 反向排序
以下是top命令内容:
# top top - 15:15:51 up 1:37, 1 user, load average: 0.00, 0.00, 0.00 ##load average指平均负载:1min,5min,15min Tasks: 104 total, 1 running, 103 sleeping, 0 stopped, 0 zombie ##Tasks表示任务数 Cpu(s): 0.0%us, 0.0%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.3%si, 0.0%st ##Cpu(s)显示的是总的Cpu数,按下1,s会消失,会显示出各Cpu使用率 ##Cpu使用率:用户态CPU,系统态CPU,nice,idle空闲,wa,si,st
Mem: 1030684k total, 461216k used, 569468k free, 18056k buffers Swap: 2064376k total, 0k used, 2064376k free, 206420k cached ##每个进程的CPU使用率: PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND #%CPU-每个进程的CPU百分比,如果咱们有2核,这里单个进程的CPU使用率可能会大于200%
##进程号,所属用户,PR,NI,虚拟内存,常驻内存,共享内存,S,CPU使用率,内存使用率,TIME+,COMMAND
1 root 20 0 2904 1420 1212 S 0.0 0.1 0:01.26 init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 4 root 20 0 0 0 0 S 0.0 0.0 0:00.11 ksoftirqd/0 5 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 6 root RT 0 0 0 0 S 0.0 0.0 0:00.03 watchdog/0 7 root 20 0 0 0 0 S 0.0 0.0 0:00.30 events/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cgroup 9 root 20 0 0 0 0 S 0.0 0.0 0:00.00 khelper 10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 netns
平均负载,那么什么是平均负载呢?
有内在因素和外在因素两个方面。内在因素:CPU正在调度的进程数,外在因素:正在等待I/O的进程数,正在等待CPU的进程。为什么等待I/O也会产生负载呢?因为等待I/O会发生上下文切换
所以,平均负载=CPU正在调度的进程数+正在等待I/O的进程数+正在等待CPU的进程
那么负载什么情况下就好,什么情况下就差?
一般来讲,平均负载为CPU颗粒数就是发挥最大性能的时候,颗粒数为2,负载为2之内就算合理。如果平均负载值>CPU颗粒数,那么就会发生排队。排队是什么在排?是进程在排队,进程排队等待CPU去处理。
是不是平均负载高,CPU使用率就高;负载低,CPU使用率就一定低呢?
答案当然是 no !因为负载是CPU正在调度进程数+正在等待I/O的进程数+正在等待CPU的进程,而CPU使用率指的是单位时间内 CPU 繁忙情况的统计。
什么情况下CPU使用率高,负载低呢?一个进程占了所有的CPU,那么CPU使用率很高,负载比较低
负载高,CPU使用率低的情况:CPU使用率不高,正在调度的进程不多,但是有大量的进程在等待I/O。这样也会使得负载高,CPU使用率低。
CPU(s) 行的解释:
Cpu(s): 0.3%us, 0.0%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
%us:用户态进程,就是应用程序的进程;%sys就是内核态进程
问一个情况:user列全都是root用户,那么这些pid是属于用户的进程还是系统的进程?当然是用户的,root也是个用户嘛。我们希望用户态进程比例更大,因为这样证明cpu都被自己的应用程序消耗,cpu花时间在了自己的应用程序上

ni是什么?优先级,优先级由谁定?由PR定,默认都是20,数字越小,优先级越高区间在-19~20之间
密集型应用:分为I/O密集型应用和CPU密集型应用,那I/O密集是因为什么呢?是因为频繁操作磁盘,CPU密集是频繁计算。我们正常的接触到的系统是I/O密集型的,频繁操作磁盘的应用。CPU密集的我们遇到的比较少,什么阿法狗这类的。常规来讲,CPU使用率我们不要到80%
面试问:服务器的配置:一般为2的倍数:2CPU,4G内存;4CPU,4G
那么负载高怎么看CPU正在调度的队列???
看 vmstat 里面的 r列,running,cpu正在运行的进程;b列,cpu正在等待的进程
进程:
Tasks: 81 total, 1 running, 80 sleeping, 0 stopped, 0 zombie
进程的状态
running
中断
- 中断不可恢复(过程不可控制)
- 中断可恢复
理解一下:假设有1个CPU,下面有三个线程A、B、C都是假的running状态,都是刚启动,现在还没有时间片,一个时间片下只能运行一个线程。此时负载为0
假设现在A拿到了时间片,A就真正是running状态,在运行了,此时B和C依旧是假running,等待cpu时间片轮询。然后A需要等待一个I/O要从磁盘内拿一个数据,那么A就会被中断,这个叫中断不可恢复,不可恢复指的是不能打断。此时负载为1,因为只有A是真running
接下来时间片给B,B就成了真riunning,C依旧为假running;B如果此时等待外部设备,比如说等到键盘输入东西,也就要中断,这个中断是中断可恢复状态,因为这个中断是不可预知的,你不知道啥时候键盘能输入东西。此时负载为2,A在等待I/O的进程,B是在CPU内运行的进程
此时时间片给C,C就成了真running。此时负载为2,C是在调度CPU的进程,A是在等待I/O的进程,B是在等待外设,并不是在等待I/O。那么此时A的结果返回了,时间片到了A也就会变成running,C会变成假running,此时负载为1, 只有A在running
停止
休眠
僵尸:失去控制的状态,怎么也调不动也退不出
用vmstat
vmstat vmstat [-a] [-n] [-S unit] [delay [ count]] -a:显示活跃和非活跃内存 -m:显示slabinfo -n:只在开始时显示一次各字段名称。 -s:显示内存相关统计信息及多种系统活动数量。 delay:刷新时间间隔。如果不指定,只显示一条结果。 count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。 -d:显示各个磁盘相关统计信息。 -S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes) -V:显示vmstat版本信息。 -p:显示指定磁盘分区统计信息 -D:显示磁盘总体信息
vmstat可以对操作系统的内存信息、进程状态、CPU活动、磁盘等信息进行监控,不足之处是无法对某个进程进行深入分析。
# vmstat 2 3 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 568360 19264 206524 0 0 26 2 55 150 0 0 99 0 0 0 0 0 568352 19264 206524 0 0 0 0 47 143 0 0 100 0 0 0 0 0 568352 19264 206524 0 0 0 0 45 138 0 0 100 0 0
各项指标说明以及分析如下:
procs
- r列表示运行和等待CPU时间片的进程数,这个值如果长期大于系统CPU个数,说明CPU不足,需要增加CPU。
- b列表示在等待资源的进程数,比如正在等待I/O或者内存交换等。
memory
- swpd列表示切换到内存交换区的内存大小(单位KB),通俗讲就是虚拟内存的大小。如果swap值不为0或者比较大,只要si、so的值长期为0.这种情况一般属于正常情况。
- free列表示当前空闲的物理内存(单位KB)。
- buff列表示baffers cached内存大小,也就是缓冲大小,一般对块设备的读写才需要缓冲。
- cache列表示page cached的内存大小,也就是缓存大小,一般作为文件系统进行缓冲,频繁访问的文件都会被缓存,如果cache值非常大说明缓存文件比较多,如果此时io中的bi比较小,说明文件系统效率比较好。
swap
- si列表示由磁盘调入内存,也就是内存进入内存交换区的内存大小。
- so列表示由内存进入磁盘,也就是有内存交换区进入内存的内存大小。
- 一般情况下,si、so的值都为0,如果si、so的值长期不为0,则说明系统内存不足,需要增加系统内存。
io
- bi列表示由块设备读入数据的总量,即读磁盘,单位kb/s。
- bo列表示写到块设备数据的总量,即写磁盘,单位kb/s。
- 如果bi+bo值过大,且wa值较大,则表示系统磁盘IO瓶颈。
system
- in列表示某一时间间隔内观测到的每秒设备中断数。
- cs列表示每秒产生的上下文切换次数。
- 这2个值越大,则由内核消耗的CPU就越多。
cpu
- us列表示用户进程消耗的CPU时间百分比,us值越高,说明用户进程消耗cpu时间越多,如果长期大于50%,则需要考虑优化程序或者算法。
- sy列表示系统内核进程消耗的CPU时间百分比,一般来说us+sy应该小于80%,如果大于80%,说明可能出现CPU瓶颈。
- id列表示CPU处在空闲状态的时间百分比。
- wa列表示等待所占的CPU时间百分比,wa值越高,说明I/O等待越严重,根据经验wa的参考值为20%,如果超过20%,说明I/O等待严重,引起I/O等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者此监控器的带宽瓶颈(主要是块操作)造成的。
综上所述,如果评估CPU,需要重点关注procs项的r列值和CPU项的us、sy、wa列的值。
内存
1、top命令
Mem: 2054212k total, 200880k used, 1853332k free, 17788k buffers
Swap: 0k total, 0k used, 0k free, 106024k cached
Mem:物理内存
Swap:虚拟内存(以前虚拟内存一般为物理内存2-8倍,也可以设置为0)
问题:虚拟内存是怎么虚拟出来的?(这里还得自己再深入理解一下)
虚拟内存不一定是在磁盘上。有的说法虚拟内存是从磁盘上虚拟出来的一块地址当做内存来使用,其实不然,虚拟内存是磁盘和内存两者一起虚拟出来的,其中有一小部分是在内存上,大部分是在磁盘上。什么时候要用虚拟内存?肯定是物理内存不够用,才会开始用虚拟内存。就像你邮箱不够用,就得烧机油一个道理
解释下指标:
total:总内存
used:已经使用的内存
free:剩余内存(free永远大于0)
buffers:缓冲区。先写到缓冲内再同步到磁盘内
cached:缓存区。频繁从磁盘读取的那部分内容存在缓存,供内存使用
top内的RES列:进程占的物理内存
问题:什么情况下,内存不够???
free不会为0,当虚拟内存的used开始增加时,就说明物理内存不够用了(前提是虚拟内存开启了)
如果应用程序为c或者为php的,一般会设置内存的预警,used=80%*total,但是比例不绝对
如果应用为java应用,情况会比较特殊,java应用在程序没使用的时候,就会先申请一块内存。有可能一开始我就申请个8g,那如果我设置的预警小于8g,那就会有问题了。关于java应用,一般不看这里的内存,会专门看java应用的内存
磁盘
1、iostat -x
# iostat -x Linux 2.6.32-696.16.1.el6.x86_64 (xiaowenshu) 12/23/2018 _x86_64_ (1 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.14 0.00 0.09 0.03 0.00 99.74 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await r_await w_await svctm %util vda 0.03 0.07 0.09 0.13 5.07 1.56 30.94 0.00 2.76 3.97 1.94 1.82 0.04
2、sar -d 2 3
# sar -d 2 3
Linux 2.6.32-696.16.1.el6.x86_64 (xiaowenshu) 12/23/2018 _x86_64_ (1 CPU)
10:23:21 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
10:23:23 PM dev252-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:23:23 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
10:23:25 PM dev252-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:23:25 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
10:23:27 PM dev252-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev252-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
DEV:挂载的磁盘
tps:I/O的次数(什么叫一次I/O?)
磁盘I/O和读写要理解好:读写是在内存里面找不到数据,就去访问磁盘,这叫读和写。那么磁盘I/O叫什么?I/O是一个merge(合并)操作,在一个时间段内,将所有的磁盘读写划分为一次IO
rd_sec/s:每秒读扇区的大小
wr_sec/s:每秒写扇区的大小
avgrq-sz:每次操作I/O的大小
avgqu-sz:磁盘队列的长度,队列越大说明排队越多,反映出磁盘的繁忙程度
await:排队时间+处理时间
svctm:servicetime每次磁盘I/O真正处理的时间(机械硬盘时间不超过0.5ms)
那么怎么看磁盘好坏?以及瓶颈?
好坏:看avgqu-sz别太长,await和svctm别太长
进程快线程快?当然是进程快。java,jmeter是进程模式,进程下跑多个线程而已。
java项目都是单进程多线程模式。一个进程下有多个线程快还是有一个线程快?当然是只有一个从线程快
apache是多进程模式,可以用 ps -ef|grep httpd ,可以看到很多个httpd,说明是多进程模式
1 # ps -ef | grep java 2 root 2231 1 2 11:28 ? 00:00:02 /usr/local/jdk1.8.0_131/bin/java -Djava.util.logging.config.file=/usr/local/tomcat1/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize=2048 -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Dorg.apache.catalina.security.SecurityListener.UMASK=0027 -Dignore.endorsed.dirs= -classpath /usr/local/tomcat1/bin/bootstrap.jar:/usr/local/tomcat1/bin/tomcat-juli.jar -Dcatalina.base=/usr/local/tomcat1 -Dcatalina.home=/usr/local/tomcat1 -Djava.io.tmpdir=/usr/local/tomcat1/temp org.apache.catalina.startup.Bootstrap start start 3 root 2246 1 2 11:28 ? 00:00:02 /usr/local/jdk1.8.0_131/bin/java -Djava.util.logging.config.file=/usr/local/tomcat2/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize=2048 -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Dorg.apache.catalina.security.SecurityListener.UMASK=0027 -Dignore.endorsed.dirs= -classpath /usr/local/tomcat2/bin/bootstrap.jar:/usr/local/tomcat2/bin/tomcat-juli.jar -Dcatalina.base=/usr/local/tomcat2 -Dcatalina.home=/usr/local/tomcat2 -Djava.io.tmpdir=/usr/local/tomcat2/temp org.apache.catalina.startup.Bootstrap start start
tomcat是java项目,是多线程模式
top命令输入H,可以显示线程。

或者,输入:可以查看到java项目下各个线程所占用的资源
1 #2231是上面的java项目的pid号 2 # top -H -p 2231 3 top - 11:31:04 up 2 min, 1 user, load average: 0.17, 0.30, 0.13 4 Tasks: 41 total, 0 running, 41 sleeping, 0 stopped, 0 zombie 5 Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st 6 Mem: 1030684k total, 430812k used, 599872k free, 14020k buffers 7 Swap: 2064376k total, 0k used, 2064376k free, 202636k cached 8 9 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 10 2231 root 20 0 339m 52m 7996 S 0.0 5.2 0:00.01 java 11 2273 root 20 0 339m 52m 7996 S 0.0 5.2 0:01.43 java 12 2276 root 20 0 339m 52m 7996 S 0.0 5.2 0:00.13 java 13 2277 root 20 0 339m 52m 7996 S 0.0 5.2 0:00.00 java 14 2280 root 20 0 339m 52m 7996 S 0.0 5.2 0:00.00 java 15 2281 root 20 0 339m 52m 7996 S 0.0 5.2 0:00.00 java 16 2283 root 20 0 339m 52m 7996 S 0.0 5.2 0:00.30 java 17 2286 root 20 0 339m 52m 7996 S 0.0 5.2 0:00.00 java 18 2288 root 20 0 339m 52m 7996 S 0.0 5.2 0:00.04 java
再按下H,就会缩变成一个进程
# top -H -p 2231 top - 11:34:32 up 6 min, 1 user, load average: 0.00, 0.14, 0.09 Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 1030684k total, 431044k used, 599640k free, 14120k buffers Swap: 2064376k total, 0k used, 2064376k free, 202636k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2231 root 20 0 339m 52m 7996 S 0.0 5.2 0:02.37 java
这个有啥用呢?
怎么查看CPU使用率高的原因:某个进程造成==>该进程的某个线程造成的==>找出该线程正在调用的方法
找到这个方法就ok咯!
那用top命令,我怎么知道哪个进程,线程消耗的CPU高?用哪个可以排序呢?
按下f,可设置显示的列,想要在外面显示哪一列,按下字母就ok,或者光标移到字母上,按下空格键。选择好了后,按下enter键
1 Current Sort Field: K for window 1:Def 2 Select sort field via field letter, type any other key to return 3 4 a: PID = Process Id within viewable range is chosen. 5 b: PPID = Parent Process Pid 6 c: RUSER = Real user name Note2: 7 d: UID = User Id Field sorting uses internal values, 8 e: USER = User Name not those in column display. Thus, 9 f: GROUP = Group Name the TTY & WCHAN fields will violate 10 g: TTY = Controlling Tty strict ASCII collating sequence. 11 h: PR = Priority (shame on you if WCHAN is chosen) 12 i: NI = Nice value 13 j: P = Last used cpu (SMP) 14 * K: %CPU = CPU usage 15 l: TIME = CPU Time 16 m: TIME+ = CPU Time, hundredths 17 n: %MEM = Memory usage (RES) 18 o: VIRT = Virtual Image (kb) 19 p: SWAP = Swapped size (kb) 20 q: RES = Resident size (kb) 21 r: CODE = Code size (kb) 22 s: DATA = Data+Stack size (kb) 23 t: SHR = Shared Mem size (kb) 24 u: nFLT = Page Fault count 25 v: nDRT = Dirty Pages count 26 w: S = Process Status 27 x: COMMAND = Command name/line 28 y: WCHAN = Sleeping in Function 29 z: Flags = Task Flags <sched.h> 30 31 Note1: 32 If a selected sort field can't be 33 shown due to screen width or your 34 field order, the '<' and '>' keys 35 will be unavailable until a field
按CPU排序:P(大写的P)
或者shift+p
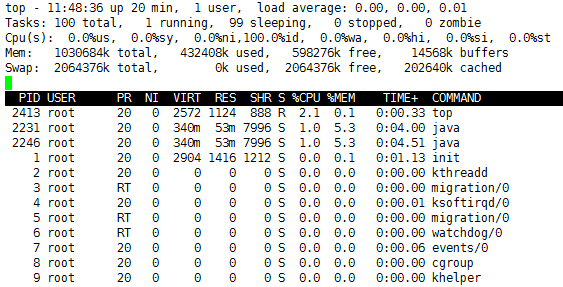
按内存排序:M(大写的M)
或者shift+m
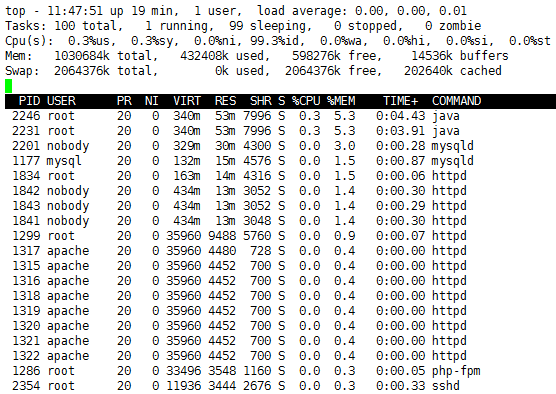
按时间排序:T(或者shift+t)
vmstat 内:
# vmstat 2 2 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 587332 17216 204992 0 0 87 5 63 162 0 0 98 1 0 0 0 0 587324 17216 204992 0 0 0 0 46 136 0 0 100 0 0
其他几项讲了,这里看下,system内的:in和cs
in:中断
cs:上下文切换
iostat:
iostat -c看cpu
iostat -d看磁盘
iostat -x看磁盘
sar:
sar -d看磁盘
sar -q看队列
sar -u看cpu
sar -r看内存
strace:终极命令,跟踪系统内核的调用情况
但是能玩好的不多。。。
网络
netstat -i
1 # netstat -i 2 Kernel Interface table 3 Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg 4 eth1 1500 0 1028 0 0 0 1409 0 0 0 BMRU 5 lo 16436 0 0 0 0 0 0 0 0 0 LRU
R:接收,T:发送
案例:
./nmon_x86_rhel52
现象如下:
单个字母表示对应监控点的快捷键,只要输入相应的字母,即可显示相应的资源耗用情况,输入c、m、d、n后显示效果如下(显示了cpu、内存、磁盘、网络的使用情况):

输出文件
上面介绍的只是在服务器监控,我们真正需要的是如何收集这些数据并处理分析它们。nmon提供了一个nmon_analyser的分析工具,可以利用Excel进行统计结果分析。在测试的时候,可以使用下列命令进行数据的输出:
#./nmon_x86_rhel52 -fT -s 5 -c 5
命令的含义是,-f输出文件,-T输出最耗自愿的进程,-s收集数据的时间间隔,-c收集次数。比如,测试场景需要执行20分钟,那么需要每隔10秒监控Linux系统资源就可以写成:
#./nmon_x86_rhel52 -fT -s 10 -c 120
完成后会在当前目录生成一个.nmon的文件,如下:
besttest_181223_1326.nmon
nmon输出文件的命名方式是服务器名_日期时间.nmon,我们在测试结束后,可以到当前目录下提取这些文件。
如果想在后台运行nmon,则可用:
#nohup ./nmon_x86_rhel52 -fT -s 10 -c 120
命令在后台启动相关的进程运行nmon工具。
如果想结束该进程,可使用:
#ps -eaf|grep *nmon*
命令查出该进程ID,然后使用:
#kill -9 进程ID
命令杀掉进程即可。
错误:提示没有这个文件或目录
/usr/bin/lsb_release: 没有那个文件或目录

解决方案:
yum install redhat-lsb
或者
yum install redhat-lsb-core
分析数据
为了保证数据不丢失,可以设定定时任务去启动,比如说每个小时的第一秒去启动,但是监控的时间为3604秒利用nmon工具收集到系统资源的相关数据后,就可以使用nmon工具的配套软件nmon analyser v33g.xls(工具可能因版本不同而不同)进行数据分析了。这个工具使用非常简单,分析时只需要打开相应的.nmon文件即可。
打开nmon analysis v33g.xls,如图:
如果报安全级别过高错误,则需要修改宏的安全级别设置。
单击Analyse nmon data按钮,选择需要分析的nmon文件(过程中需要保存Execl文件,输入一个容易分辨的文件名即可)。
