Elasticsearch的父子关系在一定场景下非常有利于我们进行关联查询,合理使用能加快我们的索引速度。
父子关系图
对于Elasticsearch的 Parent and Child:
-
家庭关系:
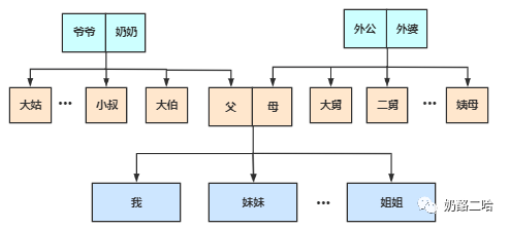
2.学校关系:
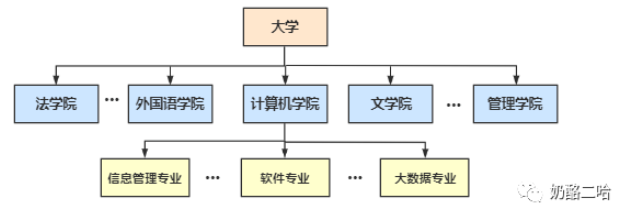
3.等等关系我们都可以用父子关系来表示,这非常有利于我们进行父子关系的查询。
Parent and Child 有如下特点:
-
父子关系
-
每个父母有多个孩子
-
多个层次的亲子关系
这里我们使用汽车关系来进行相关展示:

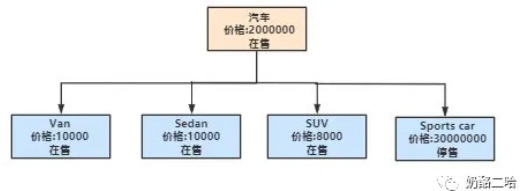
创建相关索引
PUT family_tree{"settings": {"index":{"number_of_shards":1,"number_of_replicas":0}},"mappings": {"properties": {"name":{"type": "text"},"price":{"type": "text"},"isSale":{"type": "boolean"},"relation_type":{"type": "join","eager_global_ordinals": true,"relations":{"parent":"child"}}}}}
注意:父子关系中使用 "eager_global_ordinals" 能加速join.
由于存储的数据已被非规范化。因此联接不能跨索引,子文档和父文档必须位于相同的索引和相同的分片中。父子关系需要在统一分片中:通过固定值来路由(routing)到同一个分片中。
分片规则:shard = hash(routing_value) % number_of_primary_shards
父节点插入数据
PUT family_tree/_doc/1?routing=Car{"name":"Car","price":"2000000","isSale":true,"relation_type":{"name":"parent"}}
子节点插入数据
PUT family_tree/_doc/2?routing=Car{"name":"Van","price":"10000","isSale":true,"relation_type":{"name":"child","parent":1}}PUT family_tree/_doc/3?routing=Car{"name":"Sedan","price":"10000","isSale":true,"relation_type":{"name":"child","parent":1}}PUT family_tree/_doc/4?routing=Car{"name":"SUV","price":"8000","isSale":true,"relation_type":{"name":"child","parent":1}}
注意:子文档和父文档必须位于同一分片上的限制。
查询数据 — 搜索和过滤指定的父节点
获取Car的所有子级:parent_id查询可用于查找属于特定父级的子级文档。
GET /family_tree/_search?pretty=true{"query": {"parent_id":{"type":"child","id":"1"}}}
结果:以查找出属于parent_id为 1 的所有子级文档。
在这之前我们先为 Car 添加一个不再销售的汽车类型:
PUT family_tree/_doc/5?routing=Car{"name":"Sports car","price":"30000000","isSale":false,"relation_type":{"name":"child","parent":1}}
1.用bool与must结合获取所有未售 Car 的孩子:
GET /family_tree/_search{"query": {"bool": {"filter": {"term": {"isSale": "false"}},"must": [{"parent_id":{"type":"child","id":"1"}}]}}}
结果:从查询到的结果中可以看到:只有"Sports car"符合我们查询的条件。
2.我们也可以通过has_child查询拥有子节点未销售状态的父节点信息:
GET /family_tree/_search?pretty{"query": {"has_child": {"type": "child","query": {"bool": {"must": [{"match": {"isSale": "false"}}]}}}}}
3.has_parent关键字可帮助我们获取所有有父母且符合过滤条件的孩子信息。通过has_parent来查询父节点状态为在售的所有子节点信息:
GET /family_tree/_search?pretty{"query": {"has_parent": {"parent_type": "parent","query": {"match": {"isSale": "true"}}}}}
每个关系级别都会在查询时增加内存和计算方面的开销,不建议使用多个级别的关系模型。
本次收获:
-
父子文档必须索引到同一个分片中。
-
每个索引仅允许一个连接字段映射。
-
一个元素可以有多个子级,但只能有一个父级。
-
可以向已存在的联接字段添加新关系。
-
也可以将子元素添加到现有元素中,但前提是该元素已经是父元素。
当索引时间性能比搜索时间性能更重要时,父子join可能是管理关系的一种不错选择,但代价是很高的。必须意识到这种权衡,例如父子文档的物理存储约束和增加的复杂性。另一个预防措施是避免多层父子关系,因为这将消耗更多的内存和计算量。这些都是我们在使用父子关系的时候必须要考虑到的相关内容,避免造成不必要的损失。二哈觉得大家还是要根据实际场景来选择合适自己的,综合考虑自己的需求,没有什么是一套全通的呀!ღゝ◡╹)ノ♡
二哈最近开通了公众号呀,在这里你可以收获最新的资讯呀,千万别错过啦!
欢迎兄弟们关注关注。
