文件操作
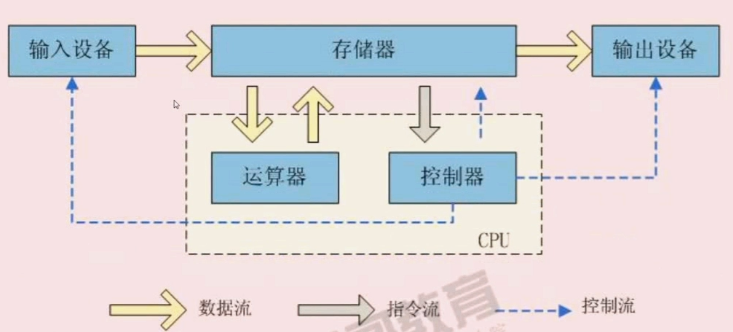

体存储单元,包括随机存储器(RAM),只读存储器(ROM),以及高速缓存(CACHE)。只不过因为RAM是其中最重要的存储器。
通常所说的内存即指电脑系统中的RAM。RAM要求每时每刻都不断地供电,否则数据会丢失。
如果在关闭电源以后RAM中的数据也不丢失就好了,这样就可以在每一次开机时都保证电脑处于上一次关机的状态,而不必每次都重新启动电脑,重新打开应用程序了。
但是RAM要求不断的电源供应,那有没有办法解决这个问题呢?随着技术的进步,人们想到了一个办法,即给RAM供应少量的电源保持RAM的数据不丢失,这就是电脑的
休眠功能,特别在Win2000里这个功能得到了很好的应用,休眠时电源处于连接状态,但是耗费少量的电能。
文件IO常用操作


打开操作


open的参数
file

mode***
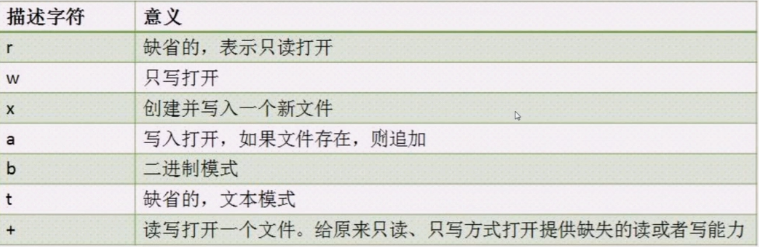


a



字符流:<_io.TextIOWrapper name='test1' mode='r+' encoding='cp936'> 字节流:<_io.BufferedRandom name='test1'>

注意在windows(cp936:双字节编码)下面以二进制读取文件和在linux(utf-8::三字节编码)下面以二进制读取文件时因为编码格式不同,其读取出来的数据也会不同。

上述原因与文件指针有关!
文件指针***
文件指针,指向当前字节位置



seek无论是在二进制模式下还是在文本模式下,seek指的都是偏移字节!

buffering:缓冲区
-1表示使用缺省大小的buffering,如果是二进制模式,使用io.DEFAULT_BUFFER_SIZE,默认是4096。 缓冲是一个可选的整数,用于设置缓冲策略。传递0以关闭缓冲(仅在二进制模式下允许),1选择行缓冲(仅在文本模式下可用),以及整数>1以字节表示固定大小块缓冲区的大小。 二进制文件以固定大小的块缓冲;在许多系统上,缓冲区通常是4096或8192字节长。 一般来说,默认缓冲区大小是个比较好的选择,除非明确知道,否则不调整它。 一般编程中,明确知道需要写磁盘了,都会手动调用一次flush,而不是等到自动flish或者close的时候。
encoding:编码,仅文本模式下使用

其他参数

read


#文本模式 f = open('tttt','r+') f.write("magedu") f.write("妈个教育") f.seek(0) print(f.tell())# 0 print(f.read(7))# magedu妈 print(f.tell())# 9 f.close() #二进制 f = open('tttt','rb+') f.write(b"magedu") f.read(7) print(f.tell())# 13 f.read(1) print(f.tell())# 14 f.close()
行读取

write

close

其他

上下文管理
在Linux中,执行




上下文管理

另一种写法


练习1

#下面是最简单的一种拷贝,但是只是拷贝了原文件的内容! with open('test.txt',encoding='utf-8') as f1: with open('test2.txt','w',encoding='utf-8') as f2: s = f1.read() f2.write(s)
练习2




#初步思想:常规统计方法 def wordcount2(file='test2.txt'): chars='''~!@#$%^&*()_+{}[]|\/"';:=.,<>''' charset = set(chars) with open(file,encoding='utf-8') as f: wordcount={} for line in f: words = line.split() # for k,v in zip(words,(1,)*len(words)):同下 for k,v in map(lambda x:(x,1),words): k = k.strip(chars) if len(k)<1: continue k = k.lower() #处理一些特殊的分隔符,如 c:foo ==> c,foo; 3.5.3 ==> 3,5,3; a///b ==> a,b start = 0 for i,value in enumerate(k):#i=1 start=0 if value in charset: if start == i: start += 1 continue key = k[start:i] wordcount[key] = wordcount.get(k, 0) + 1 start = i+1 else: key = k[start:] wordcount[key] = wordcount.get(k, 0) + 1 #按照TOP N 排序得到前十的单词 lst = sorted(wordcount.items(),key=lambda x:x[1],reverse=True) for i in range(10): print(str(lst[i]))#.strip("'()").replace("'","")) return lst