MySQL使用Limit关键字限制查询结果的数量
1、Limit关键字的使用
查询数据时,可能会查询出很多的记录。而用户需要的记录可能只是很少的一部分。这样就需要来限制查询结果的数量。Limit是MySQL中的一个特殊关键字。Limit子句可以对查询结果的记录条数进行限定,控制它输出的行数。
在MySQL数据库中创建用户信息表(tb_user),并添加数据用于测试使用。
-- 判断数据表是否存在,存在则删除
DROP TABLE IF EXISTS tb_user;
-- 创建“用户信息”数据表
CREATE TABLE IF NOT EXISTS tb_user
(
user_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '用户编号',
user_name VARCHAR(50) NOT NULL COMMENT '用户姓名',
province VARCHAR(50) NOT NULL COMMENT '省份'
) COMMENT = '用户信息表';
-- 添加数据
INSERT INTO tb_user(user_name,province) VALUES
('pan_junbiao的博客_01','广东省'),('pan_junbiao的博客_02','黑龙江省'),('pan_junbiao的博客_03','山东省'),('pan_junbiao的博客_04','安徽省'),('pan_junbiao的博客_05','黑龙江省'),
('pan_junbiao的博客_06','江苏省'),('pan_junbiao的博客_07','黑龙江省'),('pan_junbiao的博客_08','广东省'),('pan_junbiao的博客_09','陕西省'),('pan_junbiao的博客_10','广东省'),
('pan_junbiao的博客_11','广东省'),('pan_junbiao的博客_12','江苏省'),('pan_junbiao的博客_13','陕西省'),('pan_junbiao的博客_14','安徽省'),('pan_junbiao的博客_15','山东省'),
('pan_junbiao的博客_16','陕西省'),('pan_junbiao的博客_17','安徽省'),('pan_junbiao的博客_18','江苏省'),('pan_junbiao的博客_19','黑龙江省'),('pan_junbiao的博客_20','安徽省'),
('pan_junbiao的博客_21','江苏省'),('pan_junbiao的博客_22','广东省'),('pan_junbiao的博客_23','安徽省'),('pan_junbiao的博客_24','陕西省'),('pan_junbiao的博客_25','广东省'),
('pan_junbiao的博客_26','广东省'),('pan_junbiao的博客_27','安徽省'),('pan_junbiao的博客_28','山东省'),('pan_junbiao的博客_29','山东省'),('pan_junbiao的博客_30','黑龙江省'),
('pan_junbiao的博客_31','广东省'),('pan_junbiao的博客_32','江苏省'),('pan_junbiao的博客_33','陕西省'),('pan_junbiao的博客_34','安徽省'),('pan_junbiao的博客_35','山东省');
1.1 语法格式1
LIMIT m;
m:表示查询多少条记录。
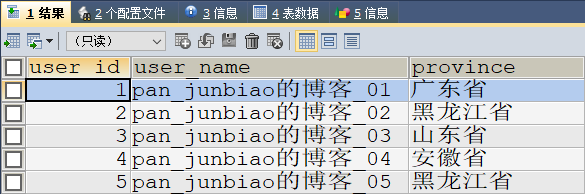
【示例】查询用户信息表(tb_user),按照 user_id 编号进行升序排列,显示前5条记录。
SELECT * FROM tb_user
ORDER BY user_id
LIMIT 5
执行结果:
1.2 语法格式2
LIMIT m , n;
m:表示开始查询的第一条记录的编号(注意:在查询结果中,第一个结果的记录编号是0,而不是1)。
n:表示查询多少条记录。
【示例】查询用户信息表(tb_user),按照 user_id 编号进行升序排列,从编号10开始,查询后面5条记录。
SELECT * FROM tb_user
ORDER BY user_id
LIMIT 10,5
执行结果:

2、使用Limit分页查询的性能优化
【示例】在存储过程中使用Limit的优化查询。
2.1 使用一般分页查询(不推荐)
DELIMITER $$
-- 方式一:使用一般分页查询(不推荐)
DROP PROCEDURE IF EXISTS proc_user_page$$
CREATE PROCEDURE proc_user_page(IN page_index INT,IN page_size INT)
BEGIN
DECLARE begin_no INT;
SET begin_no = (page_index-1)*page_size;
SELECT * FROM tb_user
ORDER BY user_id ASC
LIMIT begin_no,page_size;
END$$
DELIMITER ;
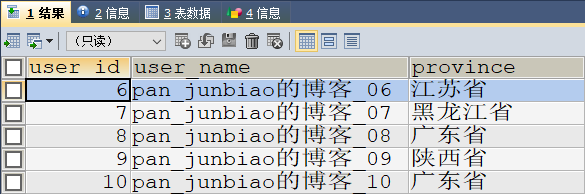
调用存储过程:查询第2页,每页5条记录。
-- 调用存储过程:查询第2页,每页5条记录
CALL proc_user_page(2,5);
执行结果:
弊端:方式一虽然实现了分页功能,但随着查询偏移的增大,尤其查询偏移大于10万以后,查询时间将急剧增加。这种分页查询方式会从数据库第一条记录开始扫描,所以越往后,查询速度越慢,而且查询的数据越多,也会拖慢总查询速度。
2.2 使用子句优化查询(推荐)
DELIMITER $$
-- 方式二:使用子句优化查询(推荐)
DROP PROCEDURE IF EXISTS proc_optimize$$
CREATE PROCEDURE proc_optimize(IN page_index INT,IN page_size INT)
BEGIN
DECLARE begin_no INT;
SET begin_no = (page_index-1)*page_size;
SELECT * FROM tb_user
WHERE user_id >= (
SELECT user_id FROM tb_user
ORDER BY user_id ASC
LIMIT begin_no,1
)
ORDER BY user_id ASC
LIMIT page_size;
END$$
DELIMITER ;
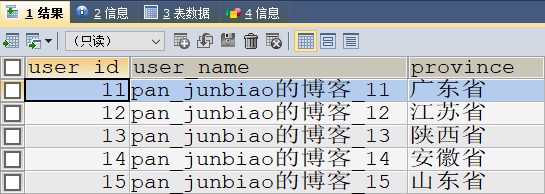
调用存储过程:查询第3页,每页5条记录。
-- 调用存储过程:查询第3页,每页5条记录
CALL proc_optimize(3,5);
执行结果:
优点:方式二适合数据表的id是连续递增的,则可以根据查询的页数和查询的记录数可以算出查询的id的范围。这种查询方式能够极大地优化查询速度,基本能够在几十毫秒之内完成。限制是只能使用于明确知道id的情况,不过一般建立表的时候,都会添加基本的自增的主键id字段,这为分页查询带来很多便利。
3、Limit的效率问题
以下内容转载至:https://www.cnblogs.com/acm-bingzi/p/msqlLimit.html
3.1 Limit的效率高?
常说的Limit的执行效率高,是对于一种特定条件下来说的:即数据库的数量很大,但是只需要查询一部分数据的情况。
高效率的原理是:避免全表扫描,提高查询效率。
比如:每个用户的email是唯一的,如果用户使用email作为用户名登陆的话,就需要查询出email对应的一条记录。
SELECT * FROM t_user WHERE email=?;
上面的语句实现了查询email对应的一条用户信息,但是由于email这一列没有加索引,会导致全表扫描,效率会很低。
SELECT * FROM t_user WHERE email=? LIMIT 1;
加上LIMIT 1,只要找到了对应的一条记录,就不会继续向下扫描了,效率会大大提高。
3.2 Limit的效率低?
在一种情况下,使用limit效率低,那就是:只使用limit来查询语句,并且偏移量特别大的情况
做以下实验:
语句1:
select * from table limit 150000,1000;
语句2:
select * from table while id>=150000 limit 1000;
语句1为0.2077秒;语句2为0.0063秒
两条语句的时间比是:语句1/语句2=32.968
比较以上的数据时,我们可以发现采用where...limit....性能基本稳定,受偏移量和行数的影响不大,而单纯采用limit的话,受偏移量的影响很大,当偏移量大到一定后性能开始大幅下降。不过在数据量不大的情况下,两者的区别不大。
所以应当先使用where等查询语句,配合limit使用,效率才高
ps:在sql语句中,limt关键字是最后才用到的。以下条件的出现顺序一般是:where->group by->having-order by->limit
附录:OFFSET
为了与 PostgreSQL 兼容,MySQL 也支持句法: LIMIT # OFFSET #。
经常用到在数据库中查询中间几条数据的需求
比如下面的sql语句:
selete * from testtable limit 2,1;
selete * from testtable limit 2 offset 1;
注意:
1.数据库数据计算是从0开始的
2.offset X是跳过X个数据,limit Y是选取Y个数据
3.limit X,Y 中X表示跳过X个数据,读取Y个数据
这两个都是能完成需要,但是他们之间是有区别的:
(1)是从数据库中第三条开始查询,取一条数据,即第三条数据读取,一二条跳过
(2)是从数据库中的第二条数据开始查询两条数据,即第二条和第三条。