1.什么是Lunece
一个全文检索的框架
2.Lunce的索引搜索的原理
分为两部分创建索引和搜索索引
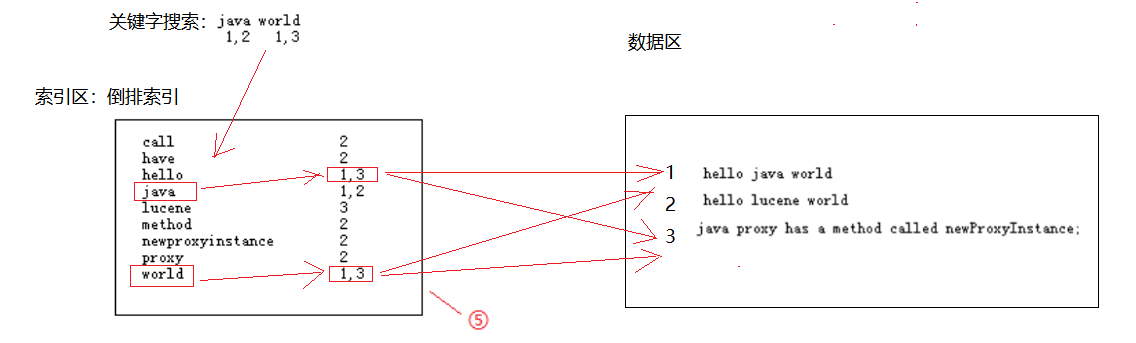
倒排索引:通过一定的算法排序并且通过链表的结构连接如java->1->3这样的链表
通过倒排索引找到数据区
3.简单使用
在Java中导入导包


<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.5.0</version>
</dependency>
通过Java代码操作
创建索引库
//1.准备存放的磁盘 String index=new String("F:/IDEAWorkSpace/lucene_learn/src/index"); //2.准备Docment文档 Document document1 = new Document(); //传入参数为name=type,第二个参数为文档 Field.Store.YES是否保存数据到数据区 IndexableField indexableField=new TextField("context",doc1, Field.Store.YES); document1.add(indexableField); Document document2 = new Document(); IndexableField indexableField1=new TextField("context",doc2, Field.Store.YES); document2.add(indexableField1); Document document3 = new Document(); IndexableField indexableField2=new TextField("context",doc3, Field.Store.YES); document3.add(indexableField2); //准备路径 Path path = Paths.get(index); Directory directory = FSDirectory.open(path); //准备分词器 Analyzer analyzer = new SimpleAnalyzer(); IndexWriterConfig conf = new IndexWriterConfig(analyzer); //3.准备IndexWriter(索引写入器) IndexWriter indexWriter = new IndexWriter(directory, conf); //读入文档 indexWriter.addDocument(document1); indexWriter.addDocument(document2); indexWriter.addDocument(document3); //提交数据 indexWriter.commit(); //关闭indexWriter indexWriter.close();
查询索引库
//1封装查询对象 String keyWord="hello"; //2准备IndexSearcher 类 String index=new String("F:/IDEAWorkSpace/lucene_learn/src/index"); Path path = Paths.get(index); Directory directory = FSDirectory.open(path); //获得DirectoryReader DirectoryReader open = DirectoryReader.open(directory); //获得IndexSearcher对象 IndexSearcher indexSearcher = new IndexSearcher(open); //获得query对象 TermQuery query = new TermQuery(new Term("context", "java")); //3使用IndexSearcher查询对象做查询- TopDocs search = indexSearcher.search(query, 1000); //获得查询分数及 ScoreDoc[] scoreDocs = search.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { //得到文档ID int id = scoreDoc.doc; //通过id获得文档 Document doc = indexSearcher.doc(id); System.out.println(doc); } //封装对象