XML概念
就是w3c指定的规范
约束
dtd约束
约束了父节点下面的元素能有多少,子节点的数据值
<!ELEMENT contacts (linkman+)>
<!ELEMENT linkman (name,email,address,group)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT email (#PCDATA)>
<!ELEMENT address (#PCDATA)>
<!ELEMENT group (#PCDATA)>
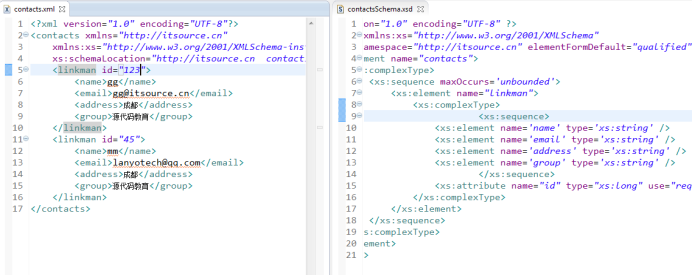
Schema约束
Dtd约束的加强版,但是结构更复杂,也是一个xml文件
DOM解析
什么是dom:文档对象Document 这样的对象
通过得到该对象得到根节点,通过根节点获得子节点的一个树结构,这样我们就能找到元素数据
实现增删改查
思想得到dom对象,找到根节点
增:找到父节点,在父节点下面创建一个标签,添加数据,但是数据是在磁盘上操作,所以我们需要刷新操作
刷新操作:找到磁盘,通过方法把dom写入磁盘
删:通过子节点找到父节点,然后删除自己
改:找到标签,添加数据
查:找到子节点获得数据
注意
Xpath的写法为/class/student[]/name[]/..这样的写法,需要关闭流,Xpath中的路径[]部位索引
源dom


package cn.jiedada.parse; import static org.junit.Assert.*; import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.junit.After; import org.junit.Before; import org.junit.Test; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class ParseTest { Document dom=null; Element root=null; @Before public void test() throws Exception { //dom解析通过DocumentBuilderFactory的newInstance方法获得factory DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //通过newDocumentBuilder获得DocumentBuilder DocumentBuilder builder = factory.newDocumentBuilder(); //解析路径parse dom = builder.parse(new File("resources/NewFile.xml")); //得到子节点 root = dom.getDocumentElement(); } //查询元素 @Test public void select(){ //通过方法获得想知道的元素得到数组通过item(索引)找到 NodeList list = root.getElementsByTagName("name"); //循环遍历获得的list for (int i = 0; i < list.getLength(); i++) { String content = list.item(i).getTextContent(); System.out.println(content); } } //添加元素 @Test public void add(){ //首先获得想要添加的父路径然后通过appendChild(Element参数)添加 Element element = (Element) root.getElementsByTagName("student").item(0); //获得想要添加Element的名字和文本 Element createElement = dom.createElement("sex"); createElement.setTextContent("男"); Node appendChild = element.appendChild(createElement); } @Test public void update(){ //获得想要跟新的 NodeList list = root.getElementsByTagName("sex"); Element item = (Element) list.item(0); item.setTextContent("女"); } @Test public void del(){ Element son = (Element) root.getElementsByTagName("sex").item(0); Element parentNode = (Element) son.getParentNode(); Element removeChild = (Element) parentNode.removeChild(son); } /** * 刷新想通过该方法把内存中的数据存入磁盘所以需要dom的路径和磁盘的路径 * @throws Exception */ @After public void flash() throws Exception{ //刷新操作获得TransformerFactory的newInstance获得factory TransformerFactory factory = TransformerFactory.newInstance(); //通过newTransformer获得Transformer Transformer transformer = factory.newTransformer(); //dom路径 DOMSource source = new DOMSource(dom); //想写入的路径 StreamResult result = new StreamResult(new File("resources/NewFile.xml")); //通过该方法把dom中的刷新到磁盘 transformer.transform(source, result); System.out.println("刷新成功"); } }
dom4j
package cn.itsource.dom4j; import static org.junit.Assert.*; import java.io.File; import java.io.FileWriter; import java.io.IOException; import java.util.List; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.OutputFormat; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; import org.junit.After; import org.junit.Before; import org.junit.Test; public class Dom4jTest { Document dom; Element root; File file=new File("resources/student.xml"); //File file=new File("resources/contacts.xml"); /* * dom4j 是第三方的拓展 因此 使用之前一定记得导包 * */ @Before public void getDom() throws Exception { //获取Saxreader对象 SAXReader reader = new SAXReader(); //将文件转换为dom对象 dom= reader.read(file); root= dom.getRootElement(); } @Test public void xpathTest(){ //第一个student下面的name标签的文本值 Node node = dom.selectSingleNode("/class/student[1]/name"); System.out.println(node.getText()); } @Test public void delete(){ Element stu2 =(Element) root.elements("student").get(1); stu2.getParent().remove(stu2); } @Test public void update(){ Element stu2 =(Element) root.elements("student").get(1); Element sex = stu2.element("sex"); sex.setText("妖"); } @Test public void add(){ Element stu2 =(Element) root.elements("student").get(1); //使用dom创建一个新的标签元素 stu2.addElement("sex").setText("男"); } @After public void flush() throws IOException{ OutputFormat format = OutputFormat.createPrettyPrint(); XMLWriter writer = new XMLWriter(new FileWriter(file),format); writer.write(dom); //关闭 writer.close(); } @Test public void select(){ /* * 需要先获取到父节点 再去找父节点下的子节点 * */ //获取student节点 List list = root.elements("student"); for (Object object : list) { //先强转 Element ele =(Element)object; //再获取student节点上面的name节点 Element element = ele.element("name"); System.out.println(element.getText()); } } }
Xpath
package cn.jiedada.parse; import static org.junit.Assert.*; import java.io.File; import java.io.FileWriter; import java.io.IOException; import java.util.concurrent.Delayed; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.OutputFormat; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; import org.junit.After; import org.junit.Before; import org.junit.Test; import org.xml.sax.XMLFilter; public class Dom4j { /**使用dom4j操作XML支持XPath, * 首先通过路径方法找到DOM文件类型的变量; * 然后找到根,通过根遍历子节点找到元素 * @throws Exception * */ Document dom; Element root; File file=new File("resources/NewFile.xml"); @Before public void test() throws Exception { SAXReader reader = new SAXReader(); dom = reader.read(file); root = dom.getRootElement(); } /*查询元素 * 得到XML中的名字然后找到数据相对于原生dom * dom4j寻找子节点非常繁琐这里我们需要使用Xpath解决这个问题需要导入 * dom4j下lib文件夹下的jaxen-1.1-beta-6. * jar包才能使用Xpath这样问题就简单多了 * 但是需要 * */ @Test public void select(){ //这里面的node都需要转化为element这样才有方法可以使用 Element element = (Element) root.selectSingleNode("/class/student[1]/name"); System.out.println(element.getText()); } /*增加的数据为内存数据需要存入磁盘所以需要自己写入一个刷新方法 * 找到父节点,然后添加子节点 * */ @Test public void add(){ Element ele = (Element) root.selectSingleNode("/class/student[2]"); ele.addElement("sex").setText("男"); } /*修改数据,找到节点,set数据 * */ @Test public void update(){ Element ele = (Element) dom.selectSingleNode("/class/student[2]/name"); ele.setText("小花"); } /*删除元素 * 不能自己删除自己只能通过父节点才能删除 * 先找到父节点 * */ @Test public void del(){ Element ele = (Element) dom.selectSingleNode("/class/student[2]/name"); ele.getParent().remove(ele); } /*需要写入的文件和读入的文件调用writer方法 * */ @After public void reflush() throws Exception{ //漂亮格式 OutputFormat format = OutputFormat.createPrettyPrint(); //磁盘位置 XMLWriter writer = new XMLWriter(new FileWriter(file),format); //读取什么文件 writer.write(dom); writer.close(); } }
及xml文件为
<?xml version="1.0" encoding="UTF-8" standalone="no"?><class> <student> <name>小黄</name> <age>20</age> </student> <student> <name>小瑞</name> <age>18</age> <name/> </student> <student> <name>小花</name> <age>18</age> </student> </class>
dtd解析
public void test() throws Exception { SAXReader reader = new SAXReader(); Document dom = reader.read(new File("resources/contacts.xml")); HashMap<String, String> map = new HashMap<>(); map.put("t", "http://itsource.cn"); reader.getDocumentFactory().setXPathNamespaceURIs(map); Node selectSingleNode = dom.selectSingleNode("t:contacts/t:linkman[1]/t:name"); }
<!ELEMENT contacts (linkman+)> <!ELEMENT linkman (name,email,address,group)> <!ELEMENT name (#PCDATA)> <!ELEMENT email (#PCDATA)> <!ELEMENT address (#PCDATA)> <!ELEMENT group (#PCDATA)>
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE contacts SYSTEM "contacts.dtd">
<contacts>
<linkman>
<name>gg</name>
<email>tech@qq.com</email>
<address>成都</address>
<group>教育</group>
</linkman>
<linkman>
<name>mm</name>
<email>lanyotech@qq.com</email>
<address>成都</address>
<group>教育</group>
</linkman>
</contacts>