一、SQL性能下降慢的原因:
- 查询语句写的烂
- 索引失效(单值 复合 )
- 关联查询太多join(有些是设计缺陷和不得以的需求)
- 服务器调优和各个参数的设置。
二、SQL JOINS
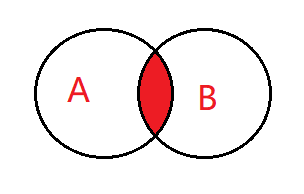
1、内连接:select * from A inner join B on A.key = B.key
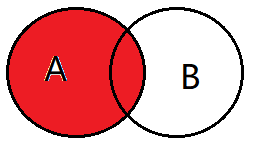
2、左连接:select * from A left join B on A.key = B.key

3、右连接:select * from A right join B on A.key = B.key
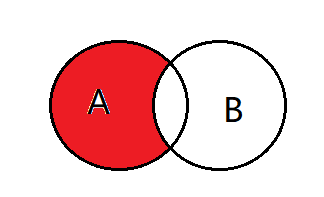
4、select * from A left join B on A.key = B.key where B.key is null;
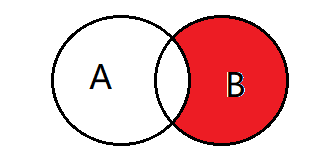
5、select * from A right join B on A.key = B.key where A.key is null;
6、全连接select * from A full outer join B on A.key = B.key ;(MySql不支持)
MySql:select * from A left join B on A.key = B.key union select * from A right join B on A.key = B.key

7、select * from A full outer join B on A.key = B.key where A.key is null or B.key is null;
mysql:
select * from A left join B on A.key = B.key where B.key is null union select * from A right join B on A.key = B.key where A.key is null
三、索引:
1、定义:
sql官方:索引(index)帮助mysql高效获取的数据结构。
-
类似字典,例如查找“mysql” 先查m,再查y 依次..
-
简单的理解:排好序的快速查找数据结构。
-
数据本身之外,数据库还维护着一个满足特定的查找算法的数据结构,这些都是数据结构以某种方式指向数据,这样就可以在数据结构上实现高级查找算法。这种数据结构就是索引。
-
一般来说索引本身很大,不可能全部存储在内存中,因此索引以文件的方式存储在磁盘上。
2、优缺点:
-
优点:(1)提高检索效率,减少io操作成不。(2)降低数据排序的成本,降低cpu消耗。
-
缺点:(1)索引实际上也是一张表,索引列也会占空间 (2)进行insert,update,delete操作时,mysql不仅要保存数据,还要保存每次更新索引列的字段。(3)如果有大量数据表,需要花时间来分析用户最喜欢的查询条件,逐步优化,找到最优建立索引的方式。
3、索引分类:
单值索引:索引只包含单个列,一个表可以有多个单列索引,一个表最好不要不要超过5个(一条查询语句只能使用一个索引)。
唯一索引:索引列的值必须唯一。可为null
复合索引:一个索引包含多个列
创建:create index indexName on tableName(aa,aa)
alter tableName ADD INDEX [indexName] ON (aa,aa)
删除:drop index[indexName] on table;
查看:show index from tableName G
4、那些情况可以建立索引:
- 主键自动建立索引。
- 频繁作为查询条件的字段。
- 查询中与其他表关联的字段,外键关系建立索引。
- 频繁更新不适合,每次更新都会更新表和索引文件。
- where 条件里用不到的字段不创建索引。
- 单键/复合?选择复合
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度。
- 重复且平均分配的字段建索引优化的效果不大(例:男/女)
5、性能分析:
explain:查询执行计划 explain+sql语句
作用:
- 表的读取顺序
执行计划所包含的信息:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | extra |
|---|---|---|---|---|---|---|---|---|---|
id
id相同,执行顺序由上至下。
如果是子查询,id号会递增,id值越大优先级越高,越先被执行。
id相同/不同:id相同,认为是一组,执行顺序由上至下。id值越大优先级越高,越先被执行。
select_type
SIMPLE:简单select 不包含子查询 /union
PRIMARY:最后加载的
SUBQUERY:包含子查询
DERIVED:
UNION:
UNION RESULT:
type
显示查询使用了何种类型。
从最好到最差
system>const>eq_ref>ref>range>index>all(全表查询)
system:表只有一行记录等于系统表
const:通过索引一次就可以找到
eq_ref:通过索引查询,表刚好只有一个记录与之匹配。
ref:
range:检索给定范围的行,查询语句中出现了< > between
index:index与all区别,只遍历树。
all :全表扫描。
possible_keys/key
显示可能应用到这张表的索引,一或多个。查询涉及到字段上的索引,则该索引别列出。但不一定实际使用。
key
实际使用的索引,如果为null,则未使用(索引失效)
若查询中使用了覆盖索引,则该索引仅出现在key列表中(理论上不会使用索引,实际上使用了)。所查的字段,正好和索引吻合。
例子 select col1,col2 from tb 而建的索引中也有 crate index idx_Name tb(col1,col2) 刚好吻合。
key_len
索引中使用的字节数,索引字段可能出现的最大长度。并非实际长度,根据定义所得,并不是检索所得。
rows
大致估算出找到所要的记录,需要读取的行数。
6、两表优化:
左连接:给右表建索引
右连接:给左表建索引
7、三表优化
与两表优化类似,左连接 给二、三表加索引。
8、索引失效
1、最佳左前缀法则(查询从索引的最左开始,中间不能断) crate index indexName(name,age,pos) 执行select name,age,pos from是最优的,但是当丢失name(select age,pos from)索引失效 类似:(select pos from)也失效。(select name)不失效。(select name,pos)失效。
2、不要在索引列中做任何操作(计算,函数,类型转换)
例如:select * from staff where left(name,4)='july' ,索引失效
3、范围之后全失效 select name,age,pos from tb where name='haha' and age>25 pos='bb' ,从age开始全失效。
4、按需写(用什么取什么),尽量索引列和查询列一致,少用select *
5、在使用使用不等于!= 或者 <>的时候会导致索引失效。从而全表扫描。但是不代表不用。 该写还得写。
6、is null 和is not null无法使用索引。建议避免空值 最好写入default
7、like以通配符开头(“%abc...”)后面查询索引会失效。%abc%失效 abc不失效。
crate index indexName on tb(name,age) 使用select * from like 导致失效。正确理解覆盖索引:查询的语句不能超过建立索引的大小。例如建立索引为(name,age)而查询的为select name,age,email. 超过索引范围,导致失效。
8、字符串不加单引号索引失效。未加‘’ mysql会进行隐式类型转换。
9、少用or ,用它连接会导致索引失效。
小结:
index(a,b,c)
where a=3 and b="ab%" and c=4 用到abc
where a=3 and b="%ab" and c=4 用到a
where a=3 and b="%ab%" and c=4 用到a
where a=3 and b="a%ab%" and c=4 用到abc 因为左边是定值。
index(c1,c2,c3)
explain select * from test03 c1='a1' and c2='a2' and c5='a5' order by c3 ,c2; 不会出现内排序(using filesort)因为c2已经是定值例如都等于1了,排序没有意义。
explain select * from test03 c1='a1' and c5='a5' order by c3 ,c2; 会出现内排序,影响sql的查询性能。
9、查询分析
- 观察 ,至少跑一天,看看慢sql情况
- 开启慢查询日志,超过5秒就是慢sql
- explain+加慢sql分析
- show profile
- DBA 参数调优
优化原则:小表驱动大表
order by
mysql支持两种排序方式,filesort和index ,index效率高,它指mysql扫描索引本身完成排序。filesort方式效率较低。
order by满足两种情况使用index :
提高order by的速度:少用select * ,写需要query的字段。
group by
与order by类似 order by是先排序 group by是先分组
Max()
通过索引的方式优化
查询最后支付的时间:explain select max(payment_date) from payment
优化:对payment_date建立索引
create index idx_paydate on payment(payment_date);
索引顺序排列,不用直接去查询表的信息,直接获取顺序排列后的最后一个值。查询的时间是恒定的。
Count()
在一条sql中,同时查询2006和2007年的数量
select count(release_year ='2006' or null) as '2006年电影数量', count(release_year='2007' or null) as '2007年电影数量' from film;
解释:count函数中,不会记录空值。使用count(*)会将空值记录进去。造成结果不一致。
子查询优化
通常情况下,需要把子查询优化成join的方式查询,但是在优化时,注意一对多的关系,使用distinct 关键词去重。
原sql:select * from t where t.id in (select t1.tid from t1);
优化:select distinct t.id from t join t1 on t.id=t1.tid;
limit
limit常用于分页处理,时常伴随着order by从句使用。
原sql :select film_id,description from sakila.film order by title limit 50,5
优化:select film_id,description from sakila.film order by film_id limit50,5
解释:使用主键film_id排序,使用了索引。随着翻页的次数增多,查询的行数变多。
再次优化:记录上一次访问主键的id,再次操作时,经过主键过滤。
select film_id,description from sakila.film where film_id>55 and film<=60 order by film_id limit50,5
注意:此次改写,需要主键连续,中间不能有间隔,通过主键过滤,不在扫描之前的。效率比较固定。
四、对mysql日志进行分析
官方自带分析工具:mysqldump
mysqldumpslow -h:查看每个参数含义
分析工具pt-query-digest
查看mysql是否开启慢查询日志:show VARIABLES like 'slow_query_log'
查看超过多少时间的查询写入日志:(默认10s)show VARIABLES LIKE 'long_query_time'
设置记录时间为0s,方面查看:SET GLOBAL long_query_time = 0
开启慢查询日志:set GLOBAL slow_query_log=ON
设置慢查询日志存放位置:set global slow_query_log_file='/home/mysql/sql_log/mysql-slow.log'
设置是否将没有使用索引的sql语句记录在日志中:set GLOBAL log_queries_not_using_indexes=ON
设置超过一秒的时查询,就把它记录在慢查询日志中:set global long_query_time=1
Show profile
用于SQL的调优测量。查看sql执行的完整生命周期。
MySQL锁
分类:
-
对于数据操作类型:读/写
-
对于数据操作的粒度:表锁/行锁
读锁(共享锁):针对同一数据,多个读操作互不影响
写锁(排它锁):当前写操作未完成前,会阻断其他写锁和读锁。
1、表锁
(偏读):开销小,加锁快。
手动加表锁 lock table 表名 read(write) ,表2名字 read(write),其他;
show open tables; //查看那些表加锁
unlock tables; //释放锁
加读锁
| session-1 | session-2 |
|---|---|
| mylock表加读锁 | |
| 当前session可查看该表 | 其他session可查看该表 |
| 当前session不可查其他未锁定的表 | 其他session可查看其他未锁定表 |
| 当前session不可更新当前锁定的表 | 其他session更新该表,会阻塞等待 |
| 释放锁 | 获得锁,插入操作完成 |
加写锁
| session-1 | session-2 |
|---|---|
| mylock表加写锁 | |
| 当前session可查询更新表 | 其他session对它查询阻塞,需要等待释放 |
| 释放锁 | 获得锁,可查询 |
总结:读锁会阻塞写,不阻塞读。写锁,会阻塞读和写。
2、行锁
innoDB,开销大,加锁慢,会出现死锁,锁定粒度小,发生锁冲突低,并发度最高。
复习:事务的ACID原则
事务具有四个特征,分别足原子性(Atomicity )、一致性(Consistency )、隔离性(Isolation) 和持久性(Durability)
-
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 -
2、一致性(Consistency )
事务前后数据的完整性必须保持一致。如果数据库系统在运行过程中发生故障, 有些事务尚未完成就被迫中断,这些未完成的事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是不一致的状态。 -
3、隔离性(Isolation)
事务的隔离性是指在并发环境中,并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。 -
4、持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
理解:https://blog.csdn.net/dengjili/article/details/82468576
并发事务带来的问题
更新丢失:
多个事务,对同一数据进行操作,由于不知道彼此的存在,最先修改的数据,被后来的事务修改。
脏读:
事务A读取到事务B已修改尚未提交的数据。事务B可能发生回滚,导致数据失效。
不可重复读:
一个事务在读取数据后的某个时间,再次读取以前读过的数据,发现不一致。
事务A读取到事务B已经提交的数据。不符合隔离性。
例子:事务A开启事务-->查出银行卡余额为1000元,此时切换到事务B事务B开启事务-->事务B取走100元-->提交,数据库里面余额变为900元,此时切换回事务A,事务A再查一次查出账户余额为900元,这样对事务A而言,在同一个事务内两次读取账户余额数据不一致,这就是不可重复读。
幻读:
一个事务按查询条件读取以前检索过的数据,发现其他事务也插入了满足查询条件的新数据。
例子:比如学生信息,事务A开启事务-->修改所有学生当天签到状况为false,此时切换到事务B,事务B开启事务-->事务B插入了一条学生数据,此时切换回事务A,事务A提交的时候发现了一条自己没有修改过的数据,这就是幻读,就好像发生了幻觉一样。幻读出现的前提是并发的事务中有事务发生了插入、删除操作。
一句话:事务A读取到了事务B提交的新增数据。
脏读是事务B里面修改了数据。
幻读是事务B里面新增了数据。
事务的隔离级别
解决上面几种问题而诞生的,事务隔离级别越高,在并发下会产生的问题就越少,但同时付出的性能消耗也将越大,因此很多时候必须在并发性和性能之间做一个权衡。

无索引行锁变表锁
间隙锁
session1
session2
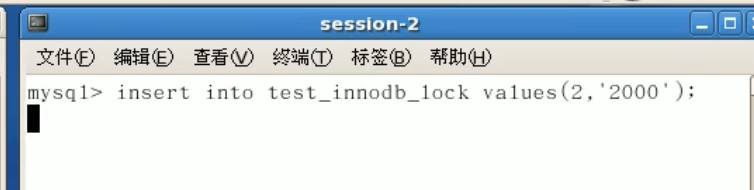
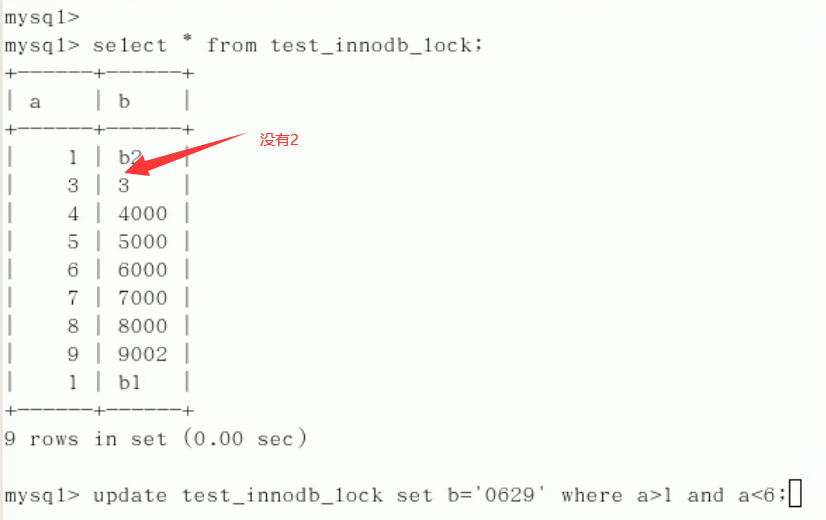
session1操作的数据没有2,但是session2,对2行无法进行操作。原因:会锁定范围之内的所有数据不管中间是否为空。只能等session1提交后才能执行。
什么是间隙锁:
当我们用范围条件而不是相等条件检索数据,并请求共享或排它锁时,innodb会给符合条件的加锁。对于在条件内并不存在的记录,叫做间隙。
锁定某一行
select * from test where a =8 for update; 锁定后,对该行的其他操作会阻塞。直到commit