特征选择笔记回顾:
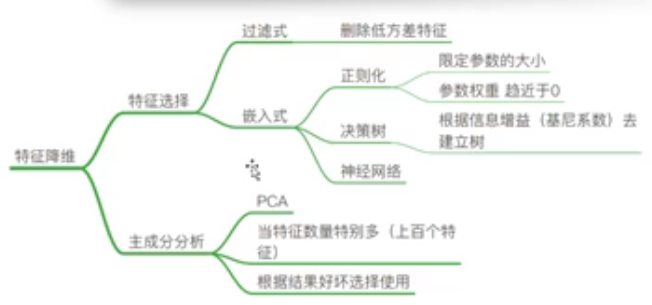
数据降维:
- 特征选择(此处重点--过滤式)
- 主成分分析(PCA)
特征选择原因:
- 冗余:部分特征的相关度高,容易消耗计算性能
- 噪声:部分特征对预测结果有影响
降维:这里的维度(数组的维度)指的是特征的数量
特征选择是什么?
特征选择就是单纯的从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以改变值、也不改变值。但是选择后的特征维数肯定比选择前小。(只选择原始数据里面的一部分特征)
注:上篇博客逻辑回归模型实战中就实现了特征选择的步骤,传送门https://www.cnblogs.com/xiaolan-Lin/p/12788135.html
降维主要方法:
- Filter(过滤式,主要是过滤方差):Variance Threshold
- Embedded(嵌入式):正则化、决策树
- Wrapper(包裹式,用得较少)
sklearn特征选择API
- sklearn.feature_selection.Variance Threshold
Variance Threshold语法
- Variance Threshold(threshold = 0)
- 删除所有低方差特征
- Variance.fit_transform(X)
- X:numpy array格式的数据[n_samples, n_features]
- 返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
Variance Threshold流程(代码演示)
1.初始化 Variance Threshold,指定阈值方差
2.调用fit_transform
用过滤法对以下数据进行特征选择:
[[0,2,0,3],
[0,1,4,3],
[0,1,1,3]]
要求:
1、Variance Threshold(threshold =1.0)
2、将结果截图放上来(没有条件的备注说明原因)注意:每个人的电脑ID是不一样的
1 from sklearn.feature_selection import VarianceThreshold 2 3 4 def var(): 5 """ 6 特征选择--删除低方差的特征 7 """ 8 var = VarianceThreshold(threshold=1.0) # 在这里取方差为1,此处是可以取所有的个位数 0 ~ 9 9 data = var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]]) # 存在方差为1 10 print(data) 11 return None 12 13 14 if __name__ == '__main__': 15 var()
结果如下:
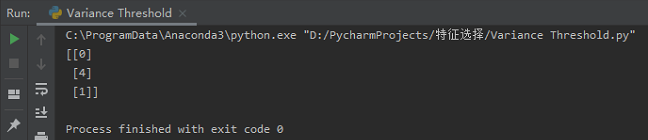
原始数据中存在方差为1的列,即第2列,当方差计算后阈值为1即被筛选出来。。。