1.本节重点知识点用自己的话总结出来,可以配上图片,以及说明该知识点的重要性
回归和分类的区别:输出变量的类型(预测的目标函数是否连续)
- 定量输出称为回归,或者说是连续变量预测;
- 定性输出称为分类,或者说是离散变量预测。
总结:回归和分类的根本区别在于输出空间是否能为一个度量的空间。
对于回归问题:
输出的空间是一个可度量的空间。假如我买的早餐包是3块钱一个,同学猜是4块钱一个,那么这中间的误差值为1。当另一个同学猜是2块钱,误差值也是1,当同学猜包子是5块钱,那误差值就变为2。本质就是预测值与真实值之间的误差值度量。
对于分类问题:
输出的空间是一个不可度量的空间。在分类场景中,只有“正确”与“错误”之分,至于是将Class1分类为Class2还是Class3,这并没有区别,都是在error counter上+1。
线性回归常见的例子:
- 房价预测
- 销售额预测
矩阵:
- 矩阵必须是二维
- 矩阵满足了特殊的运算要求
- 加法运算
- 乘法运算
- 单位矩阵
梯度下降:
在前面的博客已经写过其原理,此处不再赘述。
传送门:https://www.cnblogs.com/xiaolan-Lin/p/12681985.html#autoid-3-0-0
损失函数(误差的大小):
经过反复迭代,越来越接近真实的值。
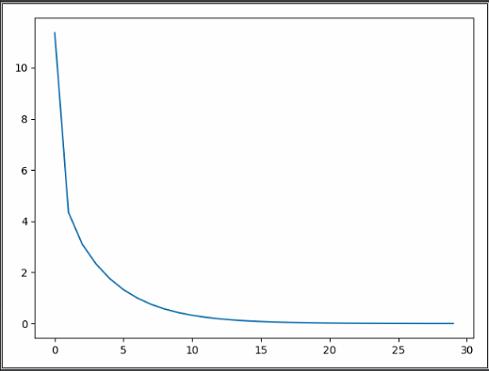
1 import matplotlib.pyplot as plt 2 import random 3 4 _xs = [0.1 * x for x in range(0, 10)] 5 _ys = [12 * i + 4 for i in _xs] 6 print(_xs) 7 print(_ys) 8 9 w = random.random() 10 b = random.random() 11 a1 = [] 12 b1 = [] 13 14 for i in range(100): 15 for x, y in zip(_xs, _ys): 16 o = w * x + b # 预测值 17 e = o - y 18 loss = e ** 2 19 dw = 2 * e * x 20 db = 2 * e * 1 21 w = w - 0.1 * dw 22 b = b - 0.1 * db 23 print("loss={0}, w={1}, b={2}".format(loss, w, b)) 24 a1.append(i) 25 b1.append(loss) 26 plt.plot(a1, b1) 27 plt.pause(0.1) 28 29 plt.show()
当迭代次数为1时,结果如下:

当迭代次数为10时,结果如下:

当迭代次数为100时,结果如下:

利用matplotlib画图,观察动态图形展示出的损失函数与迭代次数之间的关系:
2.思考线性回归算法可以用来做什么?(大家尽量不要写重复)
- 鲍鱼年龄预测
鲍鱼的优劣与其年龄有关,通常利用鲍鱼的生长纹确定它的年龄。人为数鲍鱼纹是一件很麻烦且耗时间的事,因此在现实生活中可以利用鲍鱼纹预测其年龄。
- 音乐流行趋势预测
音乐平台对流行音乐的趋势预测是基于平台用户对音乐者发行的歌曲的试听量的历史数据,挖掘出即将成为潮流的歌曲。
- 搜索引擎的搜索量和股价波动
上市公司在互联网中搜索量的变化,会显著影响公司股价的波动和趋势,即所谓的投资者注意力理论。该理论认为,公司在搜索引擎中的搜索量,代表了该股票被投资者关注的程度。因此,当一只股票的搜索频数增加时,说明投资者对该股票的关注度提升,从而使得该股票更容易被个人投资者购买,进一步地导致股票价格上升,带来正向的股票收益。
3.自主编写线性回归算法 ,数据可以自己造,或者从网上获取。(加分题)
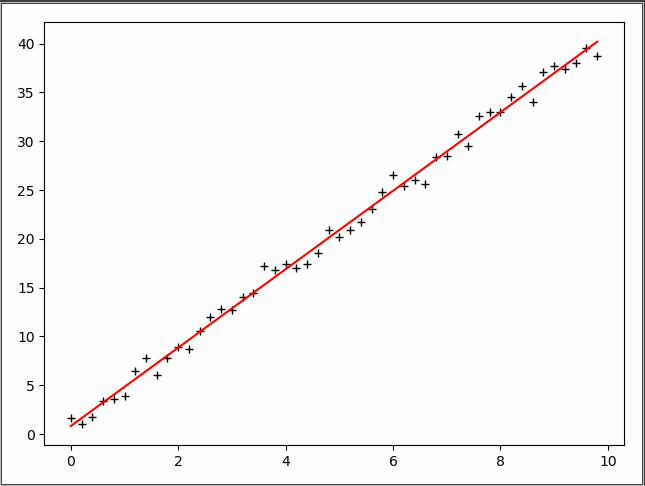
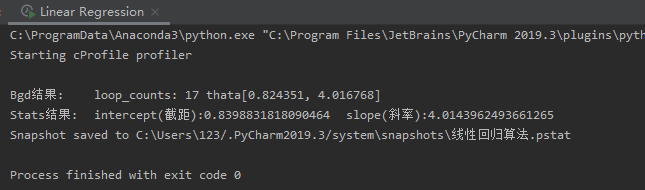
1 import numpy as np 2 from scipy import stats 3 import matplotlib.pyplot as plt 4 5 '''构造训练数据 h(x) = thata0 * x0 + thata1 * x''' 6 x = np.arange(0., 10., 0.2) 7 m = len(x) 8 x0 = np.full(m, 1.0) 9 train_data = np.vstack([x0, x]).T # 通过矩阵变化得到测试集 [x0 x1] 10 y = 4 * x + 1 + np.random.randn(m) # 通过随机增减一定值构造'标准'答案 h(x)=4*x+1 11 12 13 def Bgd(alpha, loops, epsilon): 14 ''' 15 [批量梯度下降] 16 alpha:步长, 17 loops:循环次数, 18 epsilon:收敛精度 19 ''' 20 count = 0 # loop的次数 21 thata = np.random.randn(2) # 随机thata向量初始的值,也就是随机起点位置 22 err = np.zeros(2) # 上次thata的值,初始为0向量 23 finish = 0 # 完成标志位 24 25 while count < loops: 26 count += 1 27 # 所有训练数据的期望更新一次thata 28 sum = np.zeros(2) # 初始化thata更新总和 29 for i in range(m): 30 cost = (np.dot(thata, train_data[i]) - y[i]) * train_data[i] 31 sum += cost 32 thata = thata - alpha * sum 33 if np.linalg.norm(thata - err) < epsilon: # 判断是否收敛 34 finish = 1 35 break 36 else: 37 err = thata # 没有则将当前thata向量赋值给err,作为下次判断收敛的参数之一 38 print(u'Bgd结果: loop_counts: %d thata[%f, %f]' % (count, thata[0], thata[1])) 39 40 return thata 41 42 43 def Sgd(alpha, loops, epsilon): 44 ''' 45 [增量梯度下降] 46 alpha:步长, 47 loops:循环次数, 48 epsilon:收敛精度 49 ''' 50 count = 0 # loop的次数 51 thata = np.random.randn(2) # 随机thata向量初始的值,也就是随机起点位置 52 err = np.zeros(2) # 上次thata的值,初始为0向量 53 finish = 0 # 完成标志位 54 55 while count < loops: 56 count += 1 57 # 每组训练数据都会更新thata 58 for i in range(m): 59 cost = (np.dot(thata, train_data[i]) - y[i]) * train_data[i] 60 thata = thata - alpha * cost 61 if np.linalg.norm(thata - err) < epsilon: # 判断是否收敛 62 finish = 1 63 break 64 else: 65 err = thata # 没有则将当前thata向量赋值给err,作为下次判断收敛的参数之一 66 print(u'Sgd结果: loop_counts: %d thata[%f, %f]' % (count, thata[0], thata[1])) 67 return thata 68 69 70 if __name__ == '__main__': 71 # thata = Sgd(alpha=0.001, loops=10000, epsilon=1e-4) 72 thata = Bgd(alpha=0.0005, loops=10000, epsilon=1e-4) 73 74 # 将训练数据导入stats的线性回归算法,以作验证 75 slope, intercept, r_value, p_value, slope_std_error = stats.linregress(x, y) 76 print(u'Stats结果: intercept(截距):%s slope(斜率):%s' % (intercept, slope)) 77 78 plt.plot(x, y, 'k+') 79 plt.plot(x, thata[1] * x + thata[0], 'r') 80 plt.show()