1 设计思考
1.1 关于爬取文章存储的思考
- 第一,文章要抓取到本地;
- 第二,查询文件大小,如果文件过大,超出多少M,则新建一个主题文件比如:file="./"+"微信文章_"+key+编号+".html"。我从多个html中提取信息,然后写入到同一个html中。(可以参见精通python网络爬虫的第六章中的爬取微信搜索平台。但是本文远比它复杂)
- 关于mongodb数据库的设计:首先是:文章的url,标题,然后是md5编码(用来避免重复抓取),接着是,文章在本地的存储位置。就的file="./"+"微信文章_"+key+编号+".html"文件,然后是计数count。因为使用微信搜索平台的时候,不同的关键词搜索,返回的结果中可能存在重复的文章,避免重复抓取。
其实,我也想过,以不同的key去微信搜索平台进行搜索,将返回的文章,存入到mongodb数据库不同的collection中。然后,下次以该key去抓取文章的时候,要避免重复抓取,就可以去检索mongodb数据库,该key对应的collection。
但是有一个问题就是,不同的key进行搜索,比如:“如何追漂亮妹子”,”如何追漂亮女生”,这两个搜索的有重复的文章。用上面的方式,相同url下的文章会放入不同的collection中。
虽然,本着朴实的态度,不同的key进行搜索得到的文件应该写入到不同数据库中,以表示这个key的搜索结果。
但是,本着为我负责的态度,(我不想看重复的信息),不同key下的文件,如果文章url存在重复,我也不会爬取。
所以,当一个人问,以一个key进行搜索的时候,查询我的mongodb数据库,很可能是少于直接使用微信搜索平台时的返回结果。比如,他问的是“如何追漂亮妹子”,但是微信搜索平台返回的文章列表呢,有些可能已经在之前key为“如何追漂亮女生”时,我为之建的mango数据库和相应的存储文件中了。所以,爬虫的时候,我就不爬了。
所以,请记住这种情况。我写爬虫纯粹是为了兴趣和为了要到自己的数据,浏览大量的信息,而不是为了什么狗屁严谨。
1.2 关于爬取图片的思考
首先,我设计的终极目标就是爬取生成的本地文件,还能展示原有网页的图片。单纯的urllib获取的网页都是静态数据,一方面,某些图片的src还没有加载,还存放在data-src中。比如,亲测微信搜索平台的某篇文章,在浏览器还没有向下翻的时候,图像的地址是写在data-src。这就是一种预加载机制,避免一开始就加载大量图片导致网页整体加载速度过慢。当浏览器向下滑动的时候,图片的src会被js操作改变,从而开始加载图片。所以src中开始出现图片的真实url地址。这也是我之前开发网站的常用做法。

可以看到,通过浏览器侧边栏滑动的话,已经加载的图片,src属性会等于data-src属性。但是,如果还没有加载的话,图片的src是放在data-src中。这就是一种预加载的技术。滑动的时候,再激活src。
其次,我想做的是,无论预加载与否,还是浏览器是否滑动到图片对应的位置。微信搜索平台网页设计的一个便利之处就是在于,它的图片的真实url是写在data-src中的。这样的话,我们就能够直接读取data-src中的img地址。
- 但是假如:,它的真实url不是写在data-src中,我们就要采取selenium的方式滑动整个浏览器,然后触发出图片的src属性中值的加载。类似的可以见:http://mp.weixin.qq.com/s?__biz=MzA4OTg1NTg4Nw==&mid=2649071453&idx=1&sn=267082797399b9a10508ebe43ea8a2aa&chksm=8805bdbdbf7234aba7f58308973372a2ae67d1222f4e3ae5166deffe05da4be63f30972b9846&mpshare=1&scene=24&srcid=07153kpPFpe4tyDLziaUuVNC#rd(腾讯动漫图片的爬取)
最后,我把data-src对应的网址的图片下载到本地的目录中,然后建立从图片url到本地目录中的图片文件的映射关系。然后在整个html生成以后。直接替换掉全部的src中的数据,从数据库中取出对应的文件目录,然后将本地文件的映射加载进入src中去。这样的话,就可以实现,爬虫下来的数据,也能查看到图片。同之前在网页中浏览的一样。(这特别类似于浏览器的右键另存为网页的时候回生成一个目录,专门放各种图片)。
1.3 手动验证爬取图片放入到爬取网页中的可能性
打开以后,查看源代码:
定位到第一张图片的位置:
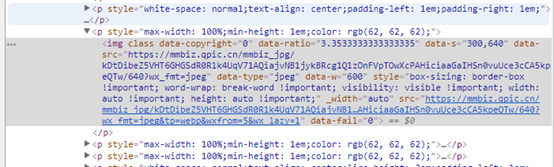
其src是:
我们现在复制网页源代码到sublime中,形成一个新的html。
然后将图片保存为本地的aa.jpeg
接着修改sublime中的本地html中src的为:./aa.jpg
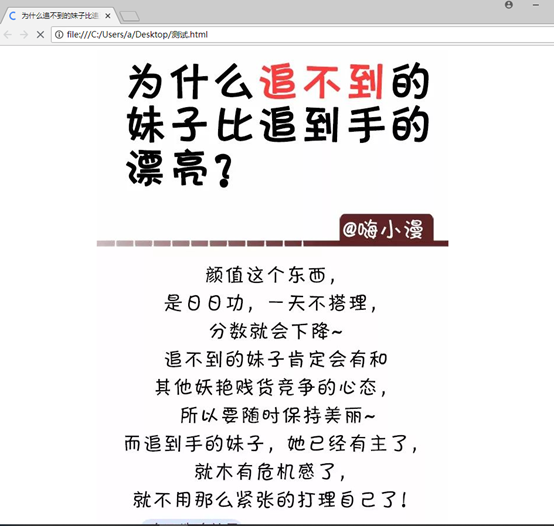
成功了!!!
但是有一个问题:
我直接在浏览器中查看网页源代码的时候,复制出来的:怎么找都找不到src这个属性。我刚刚是手动添加的src属性。
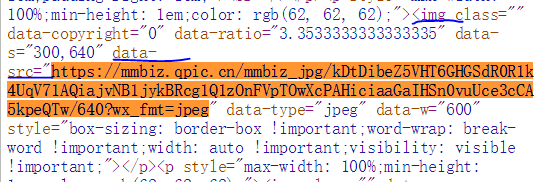
这是因为,浏览器中直接查看源码的方式,显示的是网页最初传回的源码。那个时候,还没有触发js操作,所以只有data-src属性。所以没有。但是你在浏览器中用右键检查定位的时候,页面已经刷新了。这是浏览器的问题。

我们可以观察用urllib获取的网页数据。看看src属性的情况。
实验验证:真正urllib爬取的也是没有src的,也是data-src。这就是静态网页的弊端。不过,这是微信搜索平台的独有特点。先加载的都是src。
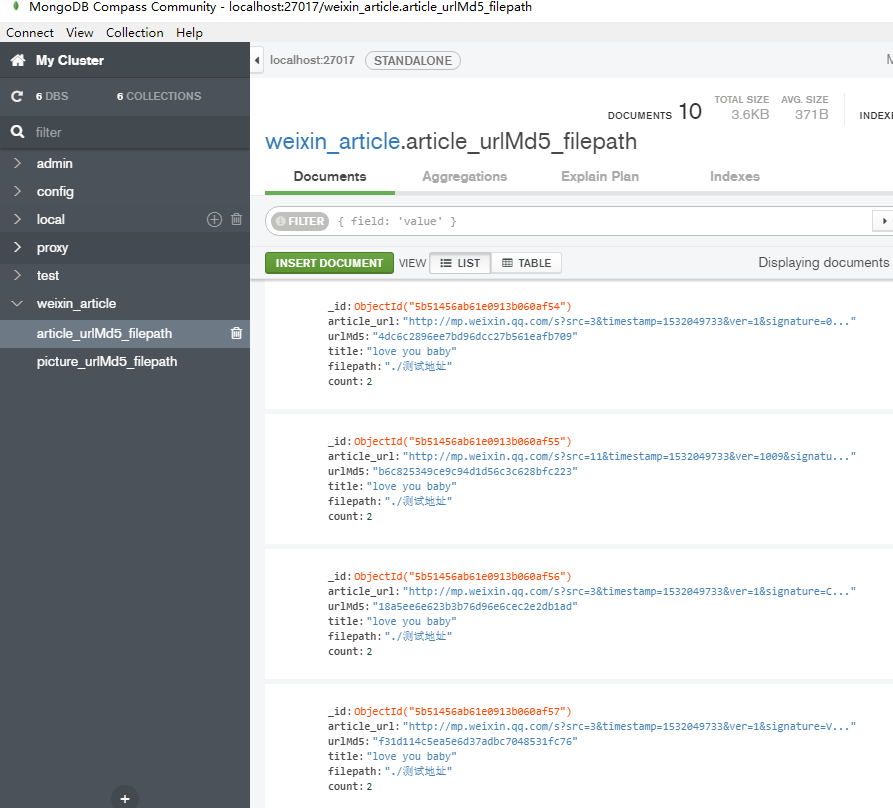
2 数据库的设计
weixin_article数据库
n 第一个collection:用于保存爬取网页中要加载的图片。
picture_urlMd5_filepath
包括
{
picture_url:
urlMd5:
filepath:
Count:
}
Count主要是为了记录该图片网址被爬取的次数。避免重复爬取。
其中urlMd5可以设置为唯一索引。但是我不打算显示设置唯一索引。而是在执行插入操作的时候,进行判断。如果已经有了,则不执行插入操作,count计数加1。如果没有,再执行插入操作。
n 第二个collection:用于保存爬取的网页数据
article_urlMd5_filepath
{
article_url:
title:
urlMd5:
filepath:
count:
}
同样,不显示设置urlMd5.但是又要保证urlMd5的唯一性。
3 数据库完整代码和测试代码
数据库接口类
# coding: utf-8 from pymongo import MongoClient class MongodbClient_weixin_article(object): def __init__(self, name, host, port): self.name = name #初始化数据表名,也就是collection的名称 self.client = MongoClient(host, port) self.db = self.client.weixin_article#使用weixin_article数据库 def changeTable(self, name): self.name = name def get(self, urlMd5): data = self.db[self.name].find_one({"urlMd5":urlMd5}) return data if data != None else None def put_picture(self,picture_url,urlMd5,filepath): #urlMd5是一个主键,我不显示设置。 condition={"urlMd5":urlMd5} document=self.db[self.name].find_one(condition) if document: #更新count计数 countNum=document['count']+1 document['count']=countNum result=self.db[self.name].update_one(condition,{'$set':document}) print("文档已经存在!!!准备插入urlMd5:{}的文档".format(urlMd5)) return None else: document={ "picture_url":picture_url, "urlMd5":urlMd5, "filepath":filepath, "count":1 } result=self.db[self.name].insert(document) print("插入urlMd5:{}的文档,操作的结果是:{}".format(urlMd5,result)) return result def put_article(self,article_url,urlMd5,title,filepath): #urlMd5是一个主键,我不显示设置。 condition={"urlMd5":urlMd5} document=self.db[self.name].find_one(condition) if document: #更新count计数 countNum=document['count']+1 document['count']=countNum result=self.db[self.name].update_one(condition,{'$set':document}) print("文档已经存在!!!准备插入urlMd5:{}的文档".format(urlMd5)) return None else: document={ "article_url":article_url, "urlMd5":urlMd5, "title":title, "filepath":filepath, "count":1 } result=self.db[self.name].insert(document) print("插入urlMd5:{}的文档,操作的结果是:{}".format(urlMd5,result)) return result def delete(self, urlMd5): result=self.db[self.name].remove({"urlMd5": urlMd5}) print("删除urlMd5:{}的文档,操作结果是:{}".format(urlMd5,result)) return result def exists(self, urlMd5): return True if self.db[self.name].find_one({"urlMd5":urlMd5}) != None else False def getNumber(self): return self.db[self.name].count()
测试代码
# -*- coding: utf-8 -*- """ Created on Fri Jul 20 08:23:55 2018 @author: a """ import MongodbClient_weixin_article import hashlib article_urls=['http://mp.weixin.qq.com/s?src=3×tamp=1532049733&ver=1&signature=0q2qr46UEAp9lSI*yPIN5WoBijEOPhSwZpjbQjQpEiJQyZgy2-5C-L0O3emN-hX0jh79aT3URKtB5s2Se4rL6FuWyfbYPLWnCdDqKNHmRe*TeI4kts0amlyrHgKiK0ixrAP--AHNEt2t-n-9Z7OaxyRTQknx86DkCwPXiKwVY2M=', 'http://mp.weixin.qq.com/s?src=11×tamp=1532049733&ver=1009&signature=egTLXKVBalu7VMZP*77RccSBwkRPNGpWUJqfRs0kBuDfZ8TwbjFoeGuKBQQ4A9bgOpkf4xqhEC2hgRHBYJCyqXwOfyshabHq*F2JjteYIiOyLSLj3eUdK-2WXNqzZHoO&new=1', 'http://mp.weixin.qq.com/s?src=3×tamp=1532049733&ver=1&signature=CsL2-HvpsfVTOhEZM27-LQk5se5W34dAjYuTKkKqNZfBacO55kTVqn*LOBhk6onEQxPMVZ94hWG7WHQ*diKBnEvvzo-0ZN042ly2ORTfEz7T2JLQ3n3L2xe2F3MoEyhpzV0BcVRyMJRGpx3auh8ExL1wkkMj*LTFU5BtpGO6S-0=', 'http://mp.weixin.qq.com/s?src=3×tamp=1532049733&ver=1&signature=VNtNZKptsswWABF3clr725M-y2pg45SZRgqasg8L0wi6r3yzpr43GoAjfpAcIS4LvplqaSRoOqZuMaFBl4z6ILZZpwtj--Bd4V3JBcyiSJ5W9AfsPDRkWGn9G5r148qKxqKW9feJIQ8DDe77rL05xD0QittWApKDOPMiUB8TpkQ=', 'http://mp.weixin.qq.com/s?src=11×tamp=1532049733&ver=1009&signature=O-T3B1RdiF5UUVlreIOsDXInOIb4xRa*W2fo6TH1Bj2NwFZM3ZTe0s6JiR8CCytqCjBbd3OgX7pXGEvh-6ErfIIGiYPMwaIvU*QN3Fjaq0UCehePhKJb67Cohd0rh-U0&new=1', 'http://mp.weixin.qq.com/s?src=3×tamp=1532049733&ver=1&signature=Xt9s5upxnYga-ipwcmVcERz5YqKxwyCSHPCzaicjjqNVwyZ3cO-nPVcDThmlBUlBj9PEU-t9Cm*KwrbYn-2A2719INbLAnViyxGJLTSxXmH1agQOteUr5PYUOi-xjSXDXQvTjySjfnw398n6VE-TqA==', 'http://mp.weixin.qq.com/s?src=3×tamp=1532049733&ver=1&signature=vSyrKJ46Wba0820nEylGfBMVL8Zif6Lj2hiOS49q-46Ik3AihVS1aghAUP4EPf9vmdsD2MJiutX1w7iBavF6TrXLrv6cIwDAK-zpssizzEGmnb6qkJHbFiPLQ87ehmMJzMWDS3Rlkbaze2HbX80W0g==', 'http://mp.weixin.qq.com/s?src=11×tamp=1532049733&ver=1009&signature=5*fJWC70b49HJpfvLnE0vGjQvGjtitjna9ObOpL6i2QAzR9wZdRoaWY0d7DxSEbxmo1LEDYF7Zz0MZyh8jd1Zzh4jIDj7XgFFdPRaERg4mR9yaoCWak1lHPAZu3q3bCs&new=1', 'http://mp.weixin.qq.com/s?src=3×tamp=1532049733&ver=1&signature=n5Yd0nWrycz23WZAj-I3tCi0LmoRs4PLgtcoLoK1bmMgZJcxF*f*rIOt9z3UobXHhvjVpIbbXD1ljjMFCvW*V-XA0eL74LgM4Xdox-9cd58m0qmUObfvlB6Yp7J6hIZMtoY-9Ay3aFerB7-iBDi-fQ==', 'http://mp.weixin.qq.com/s?src=11×tamp=1532049733&ver=1009&signature=wv02IRQ65jrVpoaBW9HHvpWsHXOf61ageled59cpyOzTdJ1w4tjY8aQ-JvgYqfYRlF7YlKiyIrXLbBEqc-9YKkxe8weaG8zOGgfykYEam9BoKWWqI65SMAIoRGj-JNNh&new=1'] db=MongodbClient_weixin_article.MongodbClient_weixin_article("article_urlMd5_filepath","localhost",27017) #db.changeTable("picture_urlMd5_filepath") for i in range(len(article_urls)): m = hashlib.md5() url=article_urls[i].encode() m.update(url) urlMd5=m.hexdigest() title="love you baby" filepath="./测试地址" db.put_article(article_urls[i],urlMd5,title,filepath) print (db.exists("b6c825349ce9c94d1d56c3c628bfc223")) print (db.get("b6c825349ce9c94d1d56c3c628bfc223")) print (db.getNumber()) for i in range(len(article_urls)): m = hashlib.md5() url=article_urls[i].encode() m.update(url) urlMd5=m.hexdigest() title="love you baby" filepath="./测试地址" db.put_article(article_urls[i],urlMd5,title,filepath) for i in range(len(article_urls)): m = hashlib.md5() url=article_urls[i].encode() m.update(url) urlMd5=m.hexdigest() filepath="./测试地址" db.delete(urlMd5)
runfile('G:/精通python网络爬虫/针对目标网站的爬虫/测试url和md5映射的mongodb数据库.py', wdir='G:/精通python网络爬虫/针对目标网站的爬虫') 插入urlMd5:4dc6c2896ee7bd96dcc27b561eafb709的文档,操作的结果是:5b514560b61e0913b060af49 插入urlMd5:b6c825349ce9c94d1d56c3c628bfc223的文档,操作的结果是:5b514560b61e0913b060af4a 插入urlMd5:18a5ee6e623b3b76d96e6cec2e2db1ad的文档,操作的结果是:5b514560b61e0913b060af4b 插入urlMd5:f31d114c5ea5e6d37adbc7048531fc76的文档,操作的结果是:5b514560b61e0913b060af4c 插入urlMd5:d1a8faad9d00bbf2966dc3db75d6f128的文档,操作的结果是:5b514560b61e0913b060af4d 插入urlMd5:731b7e7074c969ffd36685300abe7b0e的文档,操作的结果是:5b514560b61e0913b060af4e 插入urlMd5:011821ee4b366a7a396ccc6958a091d3的文档,操作的结果是:5b514560b61e0913b060af4f 插入urlMd5:ea185627b10b0b4b66fe2da7bcec3974的文档,操作的结果是:5b514560b61e0913b060af50 插入urlMd5:b0edcbdb3d4171aea30f1c28e2db10ea的文档,操作的结果是:5b514560b61e0913b060af51 插入urlMd5:d4759df2c6c3c4973db3d4ddcd37bed2的文档,操作的结果是:5b514560b61e0913b060af52 True {'_id': ObjectId('5b514560b61e0913b060af4a'), 'article_url': 'http://mp.weixin.qq.com/s?src=11×tamp=1532049733&ver=1009&signature=egTLXKVBalu7VMZP*77RccSBwkRPNGpWUJqfRs0kBuDfZ8TwbjFoeGuKBQQ4A9bgOpkf4xqhEC2hgRHBYJCyqXwOfyshabHq*F2JjteYIiOyLSLj3eUdK-2WXNqzZHoO&new=1', 'urlMd5': 'b6c825349ce9c94d1d56c3c628bfc223', 'title': 'love you baby', 'filepath': './测试地址', 'count': 1} 10 文档已经存在!!!准备插入urlMd5:4dc6c2896ee7bd96dcc27b561eafb709的文档 文档已经存在!!!准备插入urlMd5:b6c825349ce9c94d1d56c3c628bfc223的文档 文档已经存在!!!准备插入urlMd5:18a5ee6e623b3b76d96e6cec2e2db1ad的文档 文档已经存在!!!准备插入urlMd5:f31d114c5ea5e6d37adbc7048531fc76的文档 文档已经存在!!!准备插入urlMd5:d1a8faad9d00bbf2966dc3db75d6f128的文档 文档已经存在!!!准备插入urlMd5:731b7e7074c969ffd36685300abe7b0e的文档 文档已经存在!!!准备插入urlMd5:011821ee4b366a7a396ccc6958a091d3的文档 文档已经存在!!!准备插入urlMd5:ea185627b10b0b4b66fe2da7bcec3974的文档 文档已经存在!!!准备插入urlMd5:b0edcbdb3d4171aea30f1c28e2db10ea的文档 文档已经存在!!!准备插入urlMd5:d4759df2c6c3c4973db3d4ddcd37bed2的文档 删除urlMd5:4dc6c2896ee7bd96dcc27b561eafb709的文档,操作结果是:{'n': 1, 'ok': 1.0} 删除urlMd5:b6c825349ce9c94d1d56c3c628bfc223的文档,操作结果是:{'n': 1, 'ok': 1.0} 删除urlMd5:18a5ee6e623b3b76d96e6cec2e2db1ad的文档,操作结果是:{'n': 1, 'ok': 1.0} 删除urlMd5:f31d114c5ea5e6d37adbc7048531fc76的文档,操作结果是:{'n': 1, 'ok': 1.0} 删除urlMd5:d1a8faad9d00bbf2966dc3db75d6f128的文档,操作结果是:{'n': 1, 'ok': 1.0} 删除urlMd5:731b7e7074c969ffd36685300abe7b0e的文档,操作结果是:{'n': 1, 'ok': 1.0} 删除urlMd5:011821ee4b366a7a396ccc6958a091d3的文档,操作结果是:{'n': 1, 'ok': 1.0} 删除urlMd5:ea185627b10b0b4b66fe2da7bcec3974的文档,操作结果是:{'n': 1, 'ok': 1.0} 删除urlMd5:b0edcbdb3d4171aea30f1c28e2db10ea的文档,操作结果是:{'n': 1, 'ok': 1.0} 删除urlMd5:d4759df2c6c3c4973db3d4ddcd37bed2的文档,操作结果是:{'n': 1, 'ok': 1.0}
断点下在删除操作前: