书目参考:精通Python网络爬虫和Python3网络爬虫实战。
这里只给出正确的代码。
首先,代理服务器ip的网址是:http://www.xicidaili.com/。这里面有大量的失效IP地址。
其次, http://httpbin.org/get或者https开通的网址可以对是否设置成功进行验证。
实际代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 11 15:54:09 2018
@author: a
"""
#设置正确的代理服务器
from urllib.error import URLError
def use_proxy(proxy_addr,url):
import urllib.request
#proxy=urllib.request.ProxyHandler({"http":"http://"+proxy_addr,"https":"https://"+proxy_addr})
proxy=urllib.request.ProxyHandler({"http":"http://"+proxy_addr})
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400")
opener=urllib.request.build_opener(proxy)
opener.addheaders=[headers]
#print (opener.open(url).getheaders())
#print (opener.open(url).info())
try:
response=opener.open(url)
data=response.read().decode('utf-8')
print(data)
except URLError as e:
print("出现异常")
print(e.reason)
return data
#获取本机ip地址
import socket
hostname = socket.gethostname()
ip = socket.gethostbyname(hostname)
print ("本机电脑名:",hostname)
print ("本机Ip:",ip)
proxy_addr="101.236.35.98:8866"
data=use_proxy(proxy_addr,"http://httpbin.org/get")
#print (data)
print (len(data))
#也可以opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
#也可以注册opener。
urllib.request.install_opener(opener)
response=urllib.request.urlopen(url)
为了确定是否使用的是代理服务器的ip地址,可以将目标url设为: http://httpbin.org/get因为该服务器的response会专门返回客户端使用的ip地址。可以看到:
runfile('G:/精通python网络爬虫/6 代理服务器设置_2.py', wdir='G:/精通python网络爬虫')
本机电脑名: DESKTOP-090FKDS
本机Ip: 192.168.8.100
{"args":{},"headers":{"Accept-Encoding":"identity","Cache-Control":"max-age=259200","Connection":"close","Host":"httpbin.org","User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400"},"origin":"101.236.35.98","url":"http://httpbin.org/get"}
352
几个错误
第一个错误
Python3网络爬虫实战书中的错误是:设置Proxyhandler的时候使用的是:
#proxy=urllib.request.ProxyHandler({"http":"http://"+proxy_addr,"https":"https://"+proxy_addr})
即将http和https都设置了。但是这样总是会出现各种问题。
其中,http://www.xicidaili.com/对于各种类型的代理IP是有严格分类的。如果访问http的网址,就用国内http代理IP即可。
第二个错误
写代码的时候没有注意,反复open(url)就会导致报错。
print (opener.open(url).getheaders())
print (opener.open(url).info())
data=opener.open(url).read().decode('utf-8')
print(data)
return data
第三个错误
如果设置的代理是http类型的,访问的是https的网址。这个时候,代理是不起任何作用的。比如,有效的http代理服务器ip是:102.236.35.98:8866。这个时候,你随便改动IP,使用下面的代码,都能正常跑通。
def use_proxy(proxy_addr,url):
import urllib.request
proxy=urllib.request.ProxyHandler({"http":"http://"+proxy_addr})
print (proxy_addr)
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400")
opener=urllib.request.build_opener(proxy)
opener.addheaders=[headers]
data=opener.open(url).read().decode('utf-8')
print (data)
return data
#获取本机ip地址
import socket
hostname = socket.gethostname()
ip = socket.gethostbyname(hostname)
print ("本机电脑名:",hostname)
print ("本机Ip:",ip)
#proxy_addr="101.236.35.98:8866"
proxy_addr="104.236.35.98:8866"#随便改动ip地址。
data=use_proxy(proxy_addr,"https://www.baidu.com")
#print (data)
print (len(data))
为了验证一下ip地址没有起到任何作用。我们修改url为:https://httpbin.org/get
因为这个url的response是客户端的ip地址,可以看到结果如下:
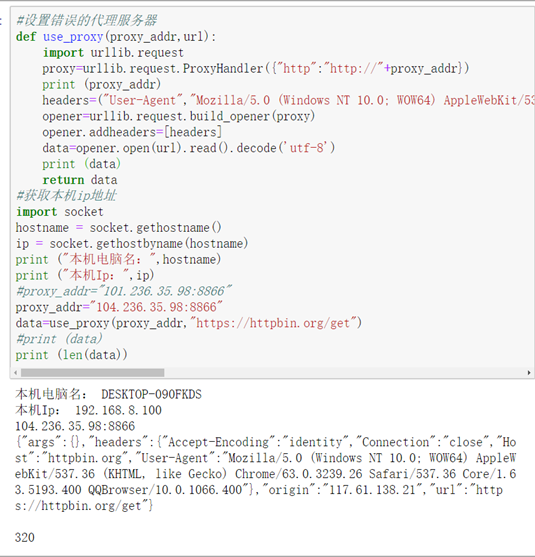
可以看到本机的ip是192.168.8.100,设置的代理服务器的ip是
104.236.35.98:8866,而服务器端记录的客户端的ip地址是:117.61.138.21.
你继续改动代理服务器的ip地址:可以看到,服务器端记录的客户端ip地址仍然是:117.61.138.21
为什么117.61.138.21和我的本机ip不一样呢。
这是因为我的电脑连接的是wifi热点。所以服务器实际记录的客户端ip地址就不是我的电脑显示的。