目前CDH支持的spark版本都是1.x, 如果想要使用spark 2x的版本, 只能编译spark源码生成支持CDH的版本。
一、准备工作
找一台Linux主机, 由于spark源码编译会下载很多的第三方类库包, 因此需要主机能够联网。
1、安装Java, 配置环境变量, 版本为JDK1.7或者以上
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html
export JAVA_HOME=/usr/java/default
export JRE_HOME=/usr/java/default/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH2、安装Maven, 版本为3.3.9或者以上
export MAVEN_HOME=/usr/local/apache-maven-3.3.9
export PATH=$MAVEN_HOME/bin:$PATH二、编译Spark的源码包
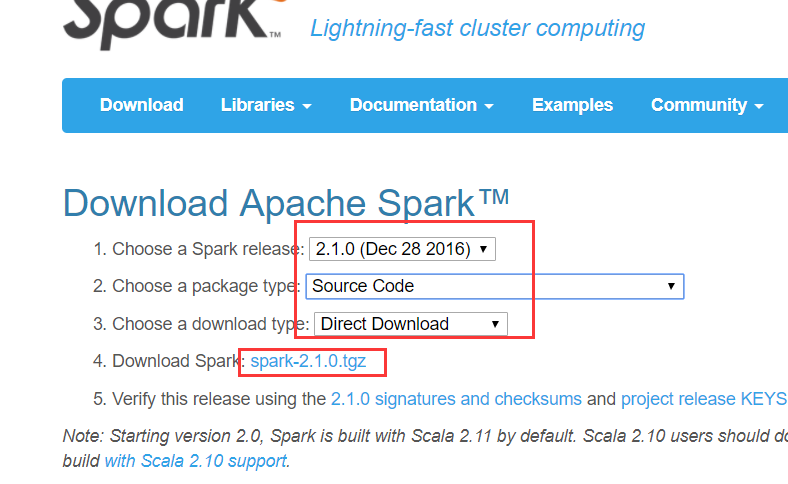
1、下载spark 2.1.0的源码包
2、增加cdh的repository
解压spark的源码包,编辑pom.xml文件, 在repositories节点 加入如下配置:
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>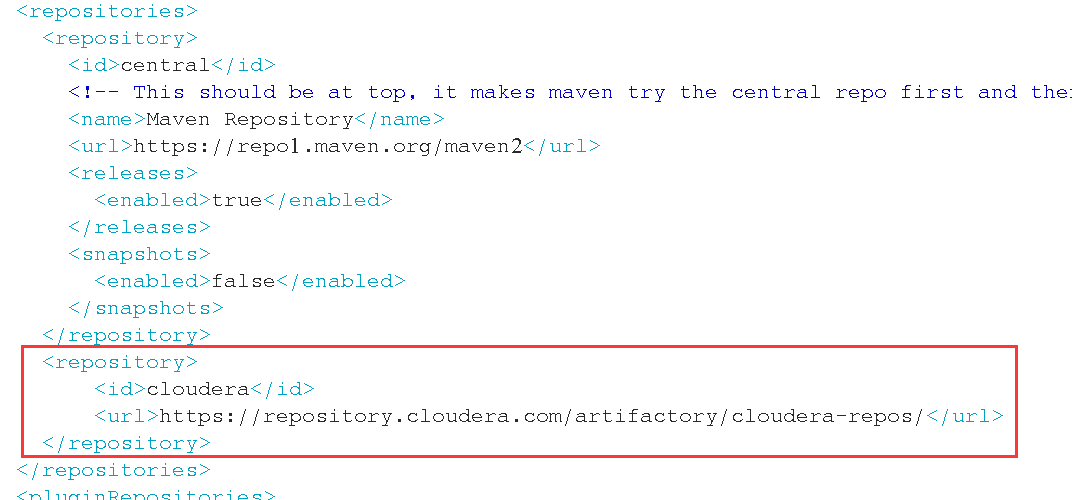
3、开始编译
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0在编译过程中, 可能会出现各种莫名其妙的原因导致中断, 只需要重新执行上面的编译命令即可, 第一编译可能需要几个小时,第一次编译成功后, 后面再编译就很快了。
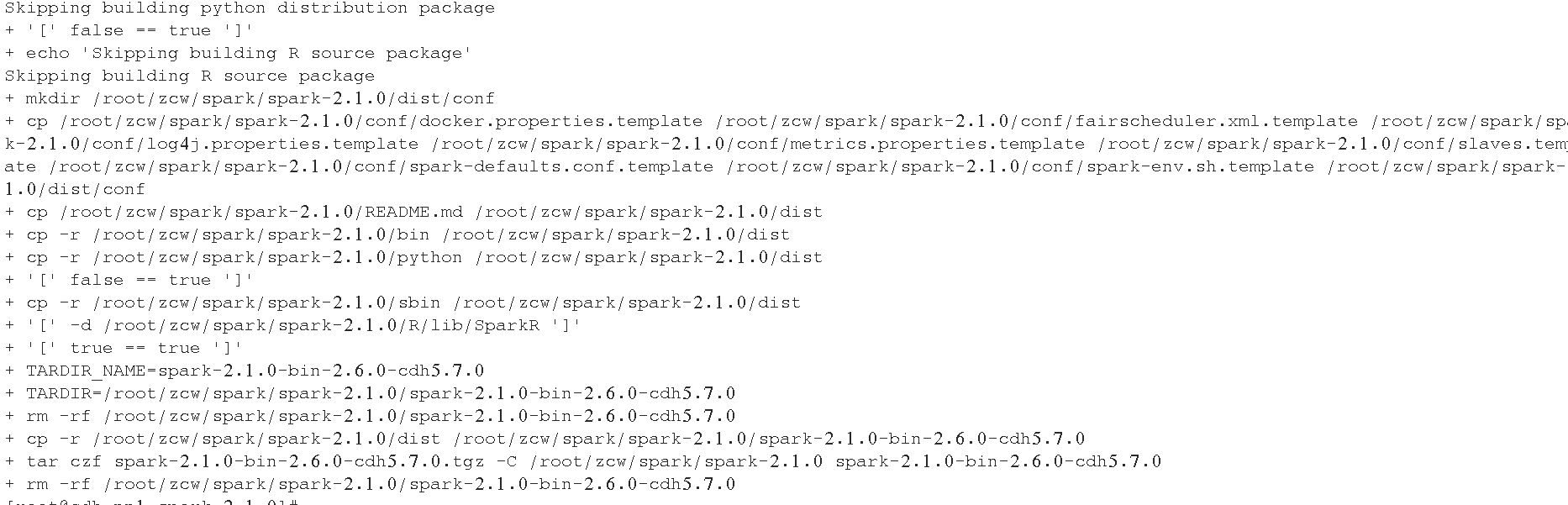
编译成功后, 可以看到如下:
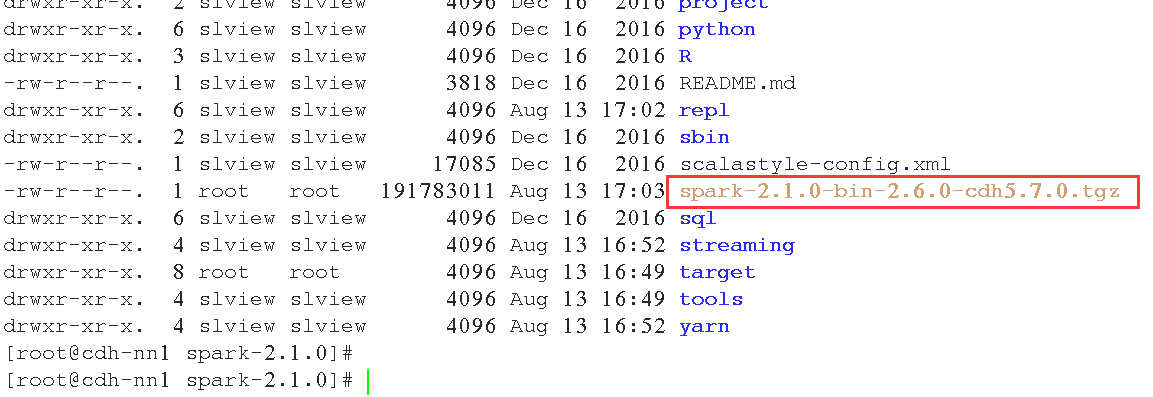
编译成功后, 可以看到生成了tar包:
三、测试
1、提交到yarn上面

需要配置HADOOP_CONF_DIR或者YARN_CONF_DIR环境变量:
# export HADOOP_CONF_DIR=/etc/hadoop/conf
val file=spark.sparkContext.textFile("/tmp/appveyor.yml")
val wc = file.flatMap(line => line.split(",")).map(word=>(word,1)).reduceByKey(_ + _)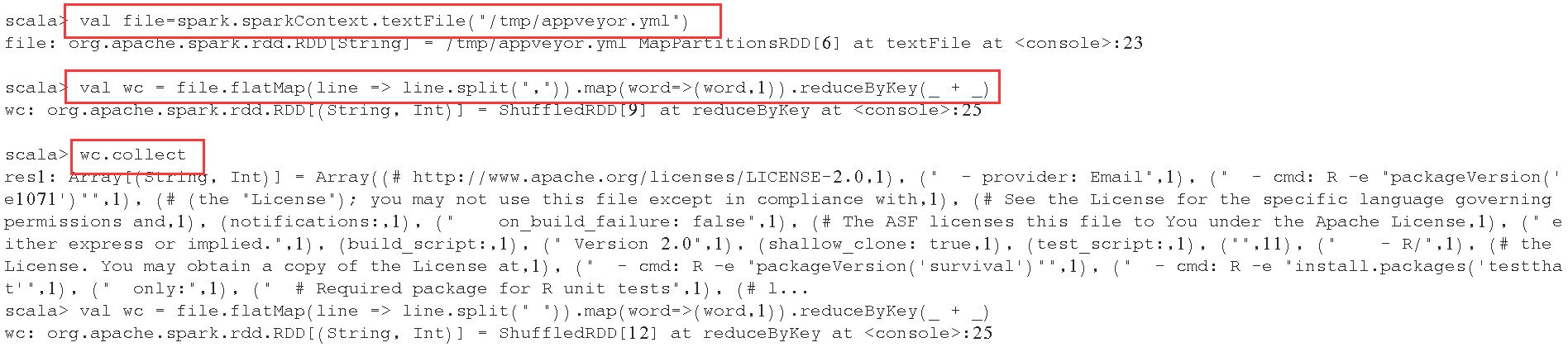
2、访问hive的表
需要将hive的hive-site.xml复制到spark的conf目录下面。
scala> spark.sql("select * from iot.tp").collect().foreach(println)
