OO Unit One总结
Written by: 18373541-xiaohan209
代码概况
第一次作业
-
整体思路
先上一张UML图。
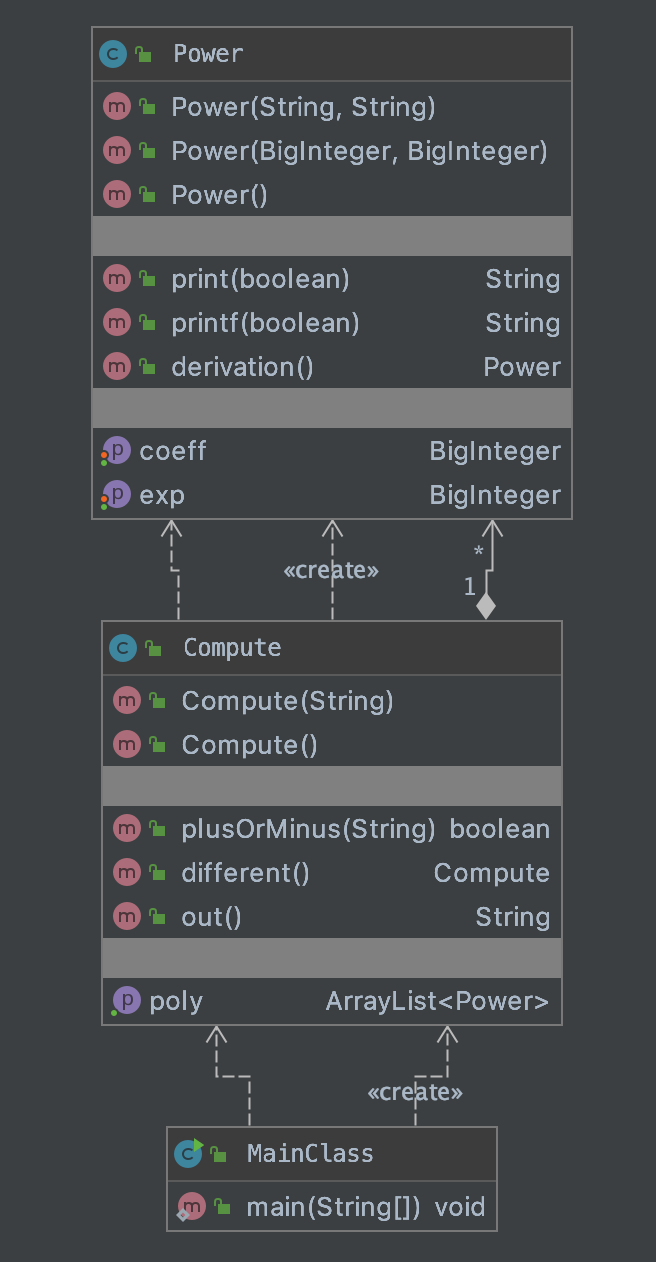
整体思路大致如下。
-
主类中第一步是扫描第一行字符然后传输给
Compute类进行构造。 -
Compute类在构造的时候先正则匹配扫描,并将扫描结果一部分一部分交给Power类来构造新的事例,并最终生成一个内部成员是Power的Arraylist变量,来表示多项式。至此Compute构造完成,返回主类。 -
主类调用
Compute的求导方法生成新的Compute类。 -
Compute求导的具体操作是让每一个内部的Power类都执行求导,并最后整合进新Computer的Arraylist中。 -
最终将求导后的新的
Computer类实例输出,Compute类的输出方法调用Power类的输出方法,最终把几个输出结果整合给最终的result并返回主类。 -
主类判断
result是否为空,空则输出0,非空则原样输出。

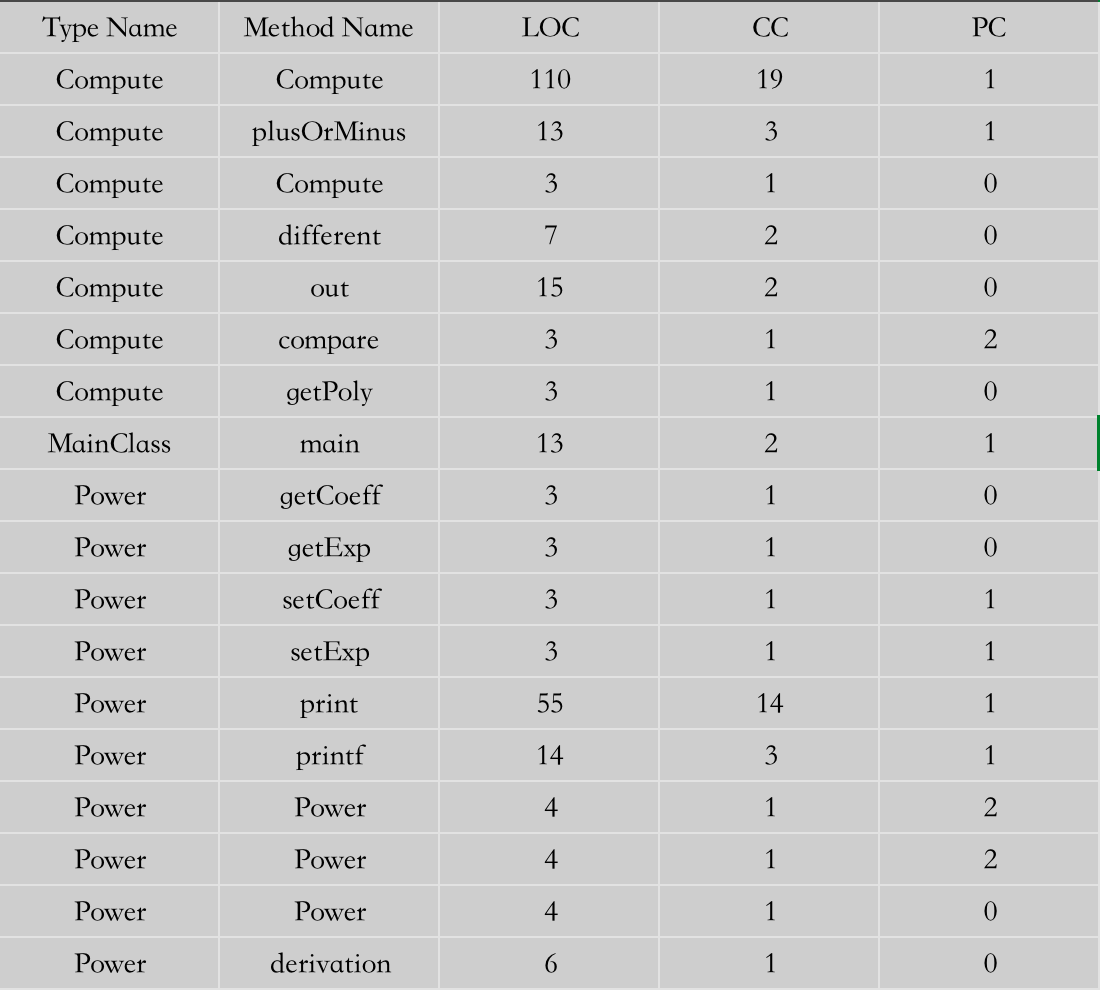
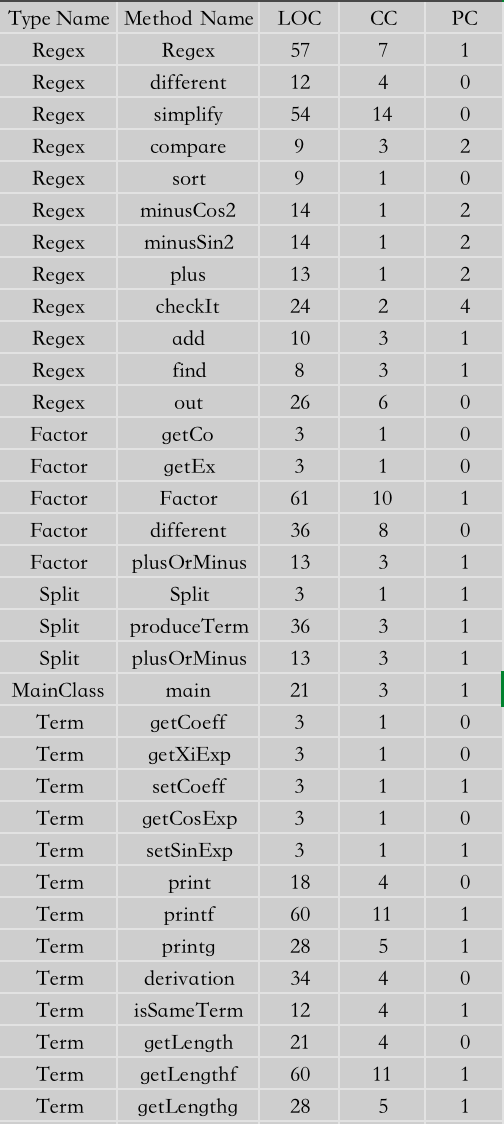
最终经过metrics reloaded分析,如下图所示其中图片未显示的有:每个类都报出存在不必要的抽象,并且每个类都有方法过长,或者方法过于复杂的问题。这个主要的原因是我在
Compute构建过程中,将正则匹配出结果、提取数字作为指数系数、调用Power构建和添加进Arraylist中都是在一个方法完成的。并且在Power的输出过程中由于需要考虑性能,对作为首项、普通项、系数指数省略都放到了一个方法中,导致出现了较为复杂的方法调用。正确的过程应该是Compute承担读取匹配的任务,然后新建一个多项式类承担整合每一项的任务。并且每一项的输出的一部分应该交由多项式类来完成,这样会更加清晰。这就是图中CC、LOC、NOM和NOPM比较高的原因。在第二次作业中会有解决方案。
-
自己的BUG:
本地测试修复:
第一点就是自己测试出来了对于读取两个负号会出现问题的bug,另外测出来了自己在输出求导后结果中,原本一个负号,会变成两个负号,是因为我在外层判断负号后内层未输出绝对值的原因,除此之外没有发现自己的bug。最终强测为满分,被hack数为0。
互测:
这一轮的数据我主要试过三种,第一种是比较长的式子,测试会不会有爆栈的风险。第二种是对于比较大的指数和系数,考验程序的鲁棒性。第三种是测试前导0以及各种正负号的组合。总共hack成功4次。其中大多都是长式子,总体数据极端的只有一个数字0、1或者一个x这样的组合,但是房间的大家都没有问题。
第二次作业
-
整体思路
先说一说重构的体会吧。当我拿到这次作业的时候,发现需要各种类型的因子,等于将原有
Power类扩充,同时要在多项式和因子之间建立一个项类,为了支持乘法运算。但是这次还是没有给因子建立指定的接口,以及没有给项和因子一个固定的逻辑,导致项和因子间有一些重复,之后会有详解。本次作业我意识到了第一次作业构造Compute类的弊端,于是将Compute类分解为Split类和Regex类(后来想想这个名字起得不太好,应该叫Poly类)。整体在作业一的MainClass基础上变化不大,只是在求导和输出中间加入了调用优化方法的操作。UML图如下所示
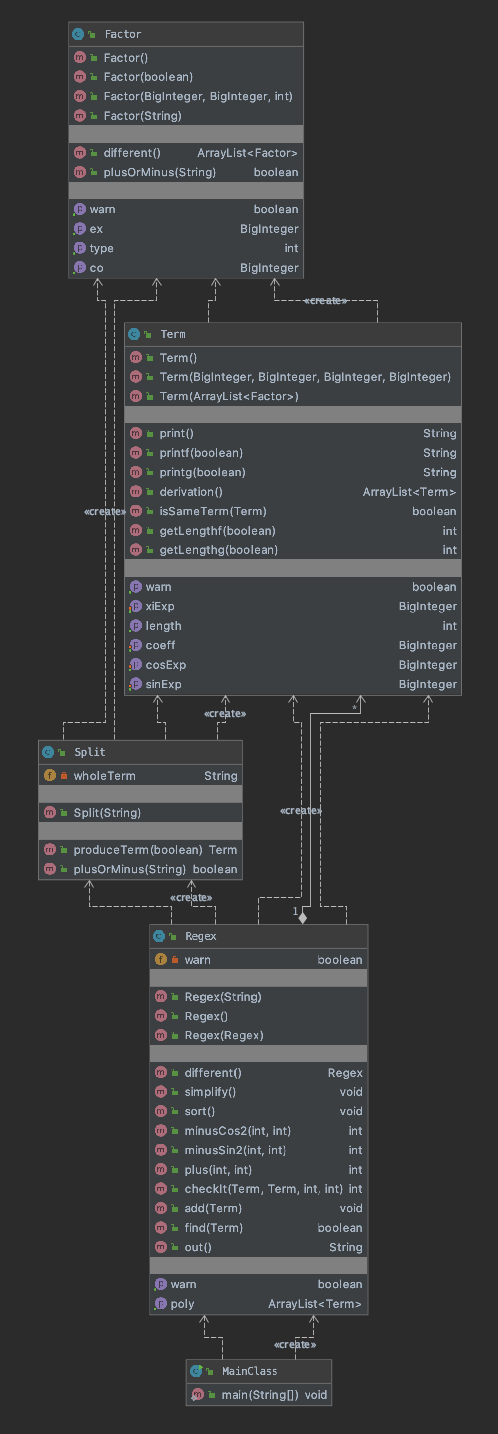
本次的主要涉及思路就是
1.先由MainClass读入字符串,并传入Regex的构造方法
2.Regex的构造方法匹配出一项,交给Split类来处理乘法分隔的各个因子,并通过Factor的构造方法构造出因子,然后将因子化简合并成一个Term类实例。
3.Term类实例返回给Regex类,Regex调用自己的方法将Term化简合并,并存到数组元素是Term类型的Arraylist中,并生成一个Regex类,至此多项式建立完成。
4.对Regex进行WF的检测,并对Regex类调用求导方法,使得对Regex的Arraylist存储的每个Term类元素都求导,分别得出Regex类变量,最终将下层的求导结果合并成新的Regex变量。
5.每个Term中都判别系数和x、sin、cos的指数并分别求导,得出一个Regex项返回。
6.进行优化,优化的方法后文中提到
7.对Regex排序并输出
8.Regex将每一个Term输出,并判断符号将其相连。
其中我的Term类并不是由Factor类构成Arraylist数组,而是直接设定系数,x的指数,sin的指数,cos的指数。做完第三次作业来看,此处没有给后面的拓展空间留有余地,导致后面对于Term类重构了。
优化方法就是按照x指数,sin指数,cos指数的优先级进行排序,然后从前往后开始寻找sin和cos指数分别为(p,q)(p-2,q+2)或者(p,q)(p-2,q)或者(p,q)(p,q-2)的两项,并对原来的式子进行两次克隆,并对其中一个克隆副本实现将两个项部分合并或者完全合并的操作,对比两个克隆副本最终输出长度。如果删改的长度变小了,那么证明优化成功,对原来的式子进行替换。这实际采用了贪心的思想。但是优化也是有问题的,那就是在找到一个可以优化的就进行优化,那么可能会导致优化结果不是最优的问题。所以如果要增强性能可以考虑分叉优化的思想,也就是不按照上述的排序顺序,从中间开始寻找可以优化的两项,或者优化后进行还原,并找出最优解。但是由于时间关系就没有做下去。
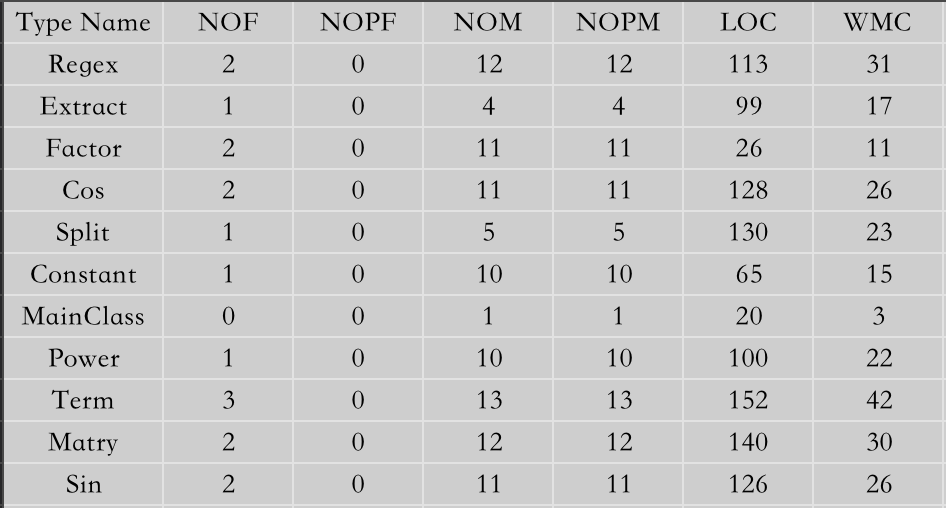
接下来是复杂度的分析图:

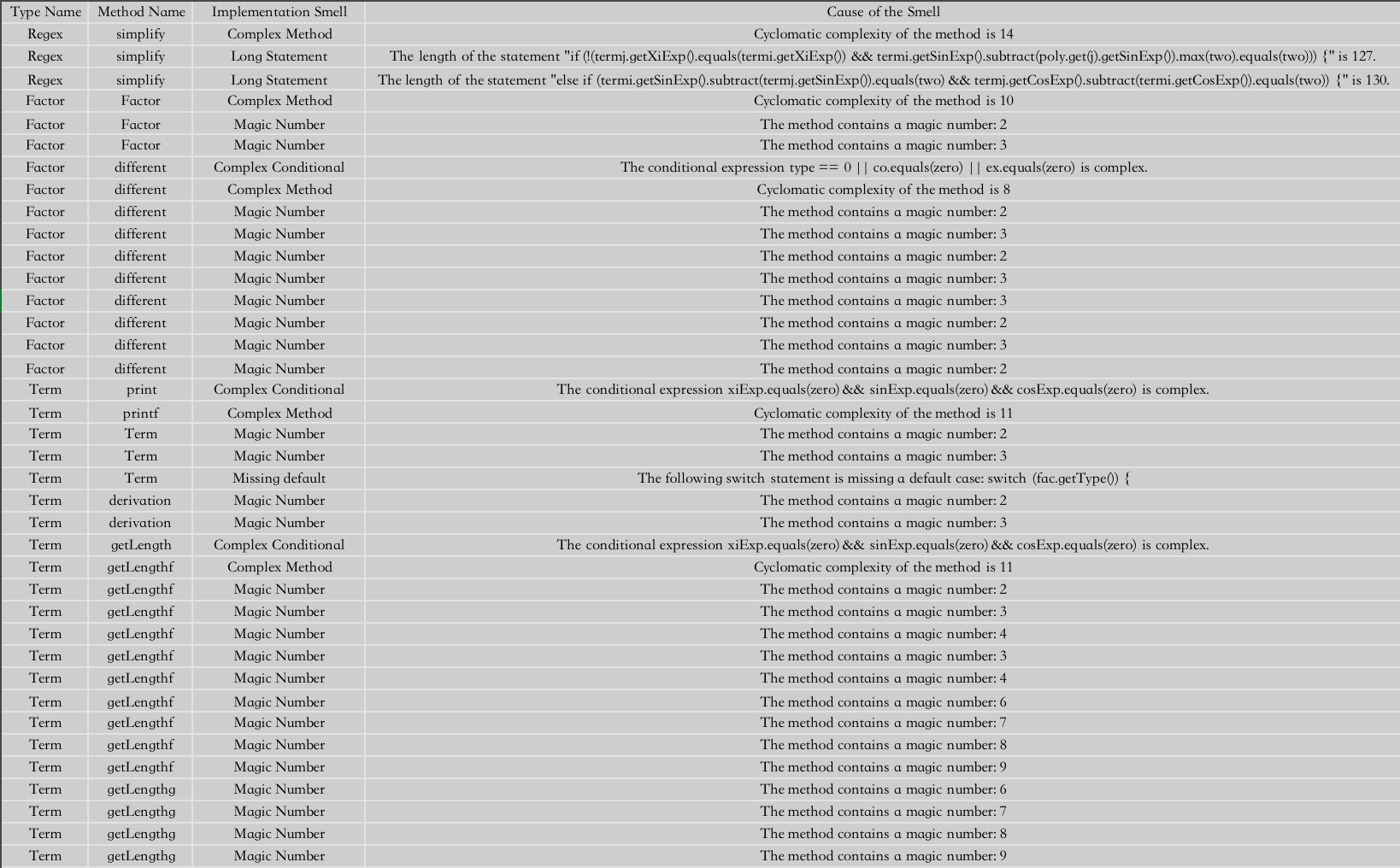
通过对于Regex和Term两个类的LOC和WMC比较多,说明这两个类已经显得有些臃肿了,可以将其中一些方法分化出来封装为新的一个类。尤其是Term类它的NOM和NOPM尤其多,作为承上启下的Term,可以将部分功能交给上面的Regex或者下层的Factor类。对于implemention smell的分析可以看出,仍然是那三个类存在着大量长方法或者复杂方法的引用,说明冗余较多,可以改进。然后从method metrics的统计来看,方法在print,printf,printg显得复杂,这是由于对性能进行改进而不断将一个方法扩充成三个方法的,这个问题应该交给Regex自上到下管理,而不应该完全交由底层否则就会有这样复杂的方法出现。另外PC比较多的是checkIt方法,是用来比较优化前和后长度的。这是由于我新建了许多Regex类进行克隆导致的,这在此也许不可避免,但是如果能换一种更好的比较方式就可以迎刃而解。
-
自己的BUG:
本地测试修复:
1.本次自己本地测出来自己cos(x)* sin(x)*5+4 *x**3这种cos和sin混合相乘有问题,发现是自己cos的求导规则写错了,并自行改正。
2.还发现对于常数和x**0的处理有时候会出错,原因是自己没有给幂函数单独设置指数为0的求导方式,程序并没有像我想的那样完全将指数为0的归为常数处理。
3.优化过程中合并需要修改多项式内容,应该对多项式进行复制,但是多项式中的类比较复杂,没有到最后一层嵌套的地方去复制,相当于直接对引用进行了复制,导致bug出现。
但是在互测过程中被hack惨了(多惨我就不分享了)。
1.由于没有认真看指导书,导致指数绝对值等于10000的时候认定为WF。
2.对于出现的垂直制表符没有判断出WF,原因是不了解正则表达式中s包含各种制表空白符,所以改为Space即可。
3.对于优化的过程没有考虑到优化后的排序会改变整体的长度,因此出现了死循环,即发现排序后可以优化并进行了优化,但是优化的时候并没有排序,实质上并没有长度的缩短。
互测数据:
1.在知道了指数的真正范围后,我也开始测试其他小伙伴有没有指数为10000的时候出现了WF的情况,事实上还真发现了一位有缘的小伙伴和我错的一毛一样。
2.自己在测试的时候发现cos(x)**3*sin(x)**4这种类型的数据很容易出问题,尤其是不同类型的项组合到一起可以将问题放大更明显。
3.对于系数没有要求,所以用一些长数据的系数来测程序的鲁棒性。
4.在sin(x)的括号中加入制表符和空格等,或者说在能加空格的地方都加入空格测试程序对正则匹配的鲁棒性。
第三次作业
-
整体思路
又双叒叕重构了我自己的代码,本次重构的原因就是不能维持原有的
Term类的结构了,需要使得不止三个因子构成一个Term,而要一个Arraylist结构。也就是本次的结构就是各种因子都继承自Factor抽象类,Factor组成一个Arraylist变成Term,Term组成Arraylist变成Regex。同时对于读入也有了新的要求,也就是嵌套的要求。所以读入的时候需要预处理以及下降递归地正则匹配的思想,所以增加了嵌套层次。UML图如下所示。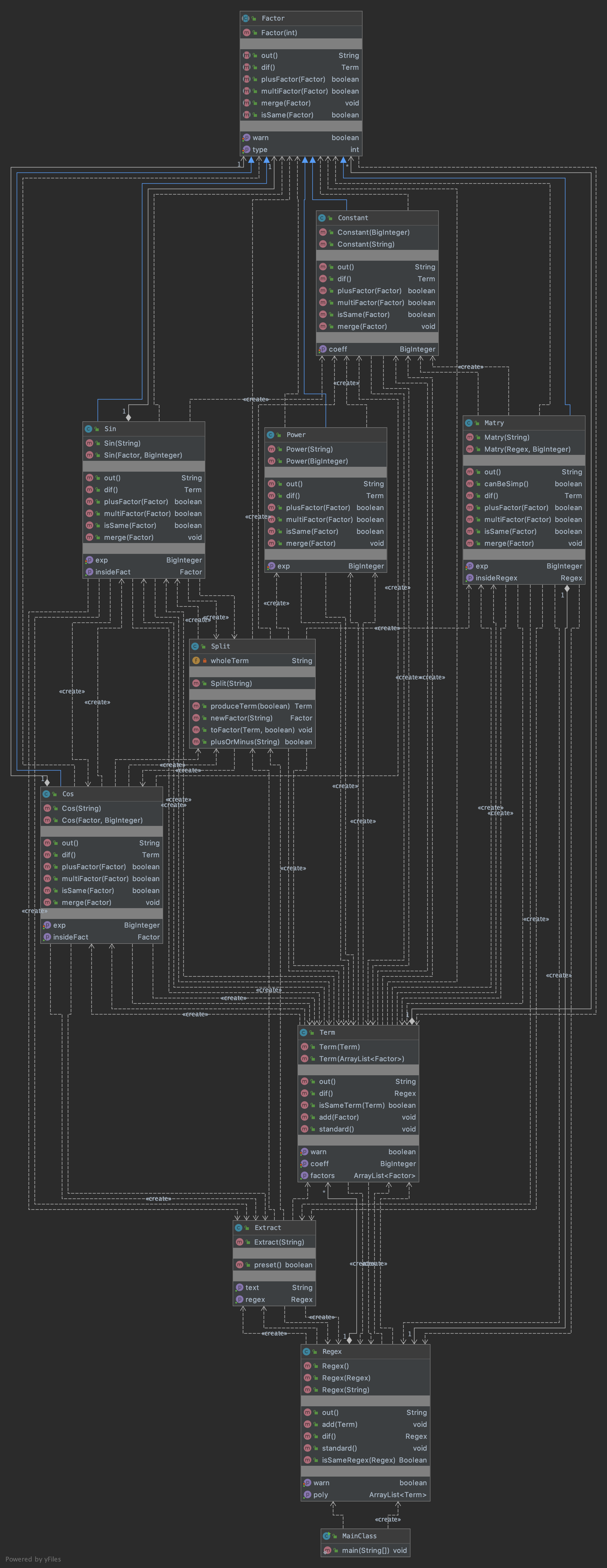
本次的思路大致如下:
- 读取一行字符串,交给
Regex处理。
- 读取一行字符串,交给
-
Regex中先构造Extract,并调用getRegex方法getRegex先预处理,然后匹配出每一项,并分析取得符号,调用Split构造方法,处理每一项的因子。Split中对每个因子进行判断,并调用继承于Factor的各种因子的构造方法。- 将因子都添加进各自的项。
- 将项添加进
Regex类,到此建立项完成。 - 检测合法性,对
Regex使用getWarn方法,并向下递归调用。 - 自上向下递归求导。
Factor求导变Term,Term求导变Regex。 - 综合求导得出的
Regex变为新的Regex。 - 输出新的
Regex。
整体的思路与第二次作业相似,只不过加入了预处理功能,将
'('')'变成'l''r'然后先匹配大的项,然后下降递归,也就是在sin,cos和另外的括号括起来的项需要识别内部内容,这个时候只需要直接再构造Extract类的实例即可,继续同样的方法识别即可。但是由于本次的多项式结构比第二次作业更加简单直观,并运用了类的继承关系,所以结构比较直接,易于求导和整合,对每个类自己定义add方法即可。 另外此次的优化并没有对三角函数进行整合化简,而只是将可以省略的1以及0以及括号内直接套括号的情况进行了优化。
当然本次的方法设计基于复杂度分析可以发现很多弊端,如图所示:
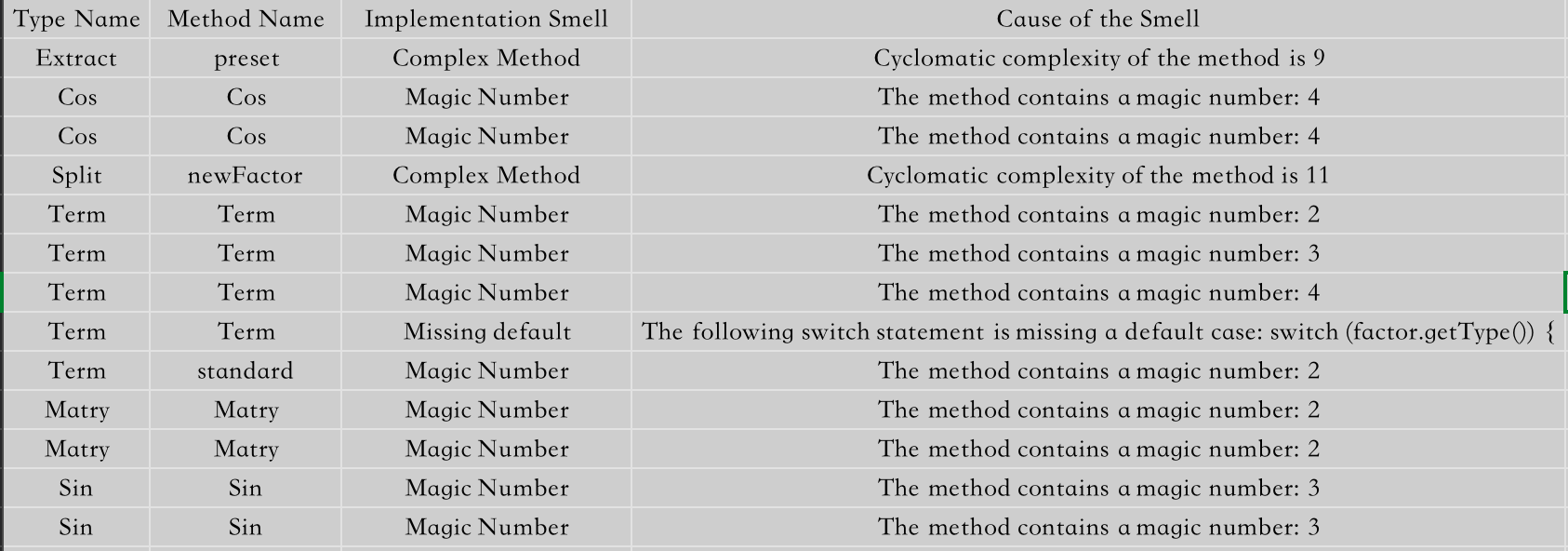
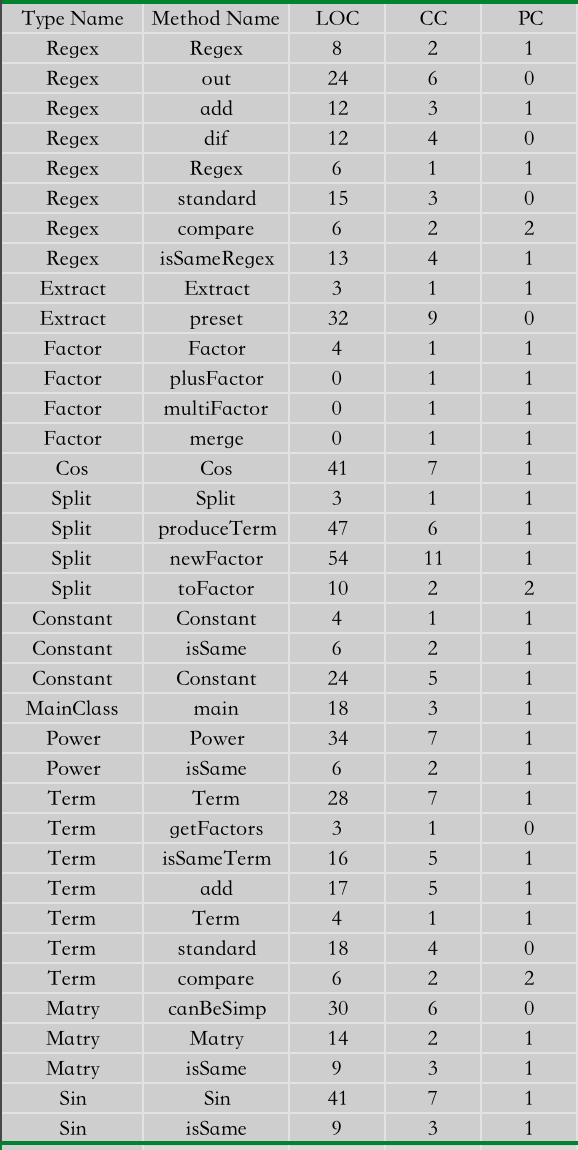
可以看出本次的LOC和WMC都上升了一个档次,并且NOM和NOPF也较高,不得不说
Term类、Regex类和继承自Factor的每一个类都有重复或者相似的代码方法,但没有最终的化简。尤其是正则匹配中每一次正则的字符串都采用了冗余的形式存储,确实很难看。 另外
Split中的newFactor方法调用了许多因子的构造方法,以及preset方法和produceTerm中进行调用其他类构造方法的CC都比较高。所以以后要尽量简化调用,尽量减少套娃。
-
Bug测试
本地测试修复:
- 求导规则发生了错误,尤其是
cos和sin进行嵌套求导的时候,直接进行了改正。 - 对于匹配的懒惰式和贪婪式的错误用法, 导致很容易对
cos(x)*sin(x)进行最外侧两个括号的匹配,所以要采用懒惰式才能避免产生这种困扰。 - 优化过度,导致正负号都已经出现了错误甚至出现
sin(2*x)的情况。
互测数据:
在互测中,再次被hack惨,同时强测直接爆炸变成60分。
- 在括号内出现0的时候,会出现不输出的情况,是优化中产生的错误。
- 在判断两个
Term类是否完全一样可以合并的时候,没有判断系数是否一致而产生了错误。 - 导致发生错误最多的bug,最外层
Extract处理分析的时候忘记对嵌套部分采用懒惰式匹配,即少加了三个问号。
另外分享几个我测出别人bug的数据
(--(--(--(--x))))这个就是从水群中发现的很好用的兔斯基数据专门用于检测普通括号嵌套的函数。+-((-cos(x)+x))这个是普通的括号和三角函数的嵌套cos((-sin((2*x))))*x**3这个是三角函数嵌套和相乘的组合sin((3*cos((-5*cos((2*x**4))**5))**7))**9这个是三角函数的多层嵌套和指数的组合。
反思心得与体会
首先再总结一下重构的细节。本次总共三次作业每次都是重新写的。每次发现自己的代码兼容不了新的功能之后都会留下悔恨的泪水,哎我太难了!之后在重构过程中我会尝试着预留一下可以修改的空间,比如第三次的Factor类就是抽象类,其中Power等类都是继承于它,但是之后并没有更多的迭代作业了。但让还有第二次我对于Regex类的处理进行了扩展,但是第三次作业的嵌套功能过于复杂,并不能用到之前预留的功能。
所以本次的心得就是,能让一个类多封装一些东西就一定要设计好。如果没有提前想好,第一种就是像作业二一样出现太多的代码行数,只能采用多层方法调用,显得很复杂。要不然就是爸爸帮儿子写作业,导致某个类特别的臃肿。要不然就是,嗯,重构吧!!!!
另外本次的所有作业本人并没有搭建评测机,所以评测占用了我很多的时间,尤其是对每个人的代码挨个测试,当然也直接构造了一些复杂数据盲开枪。不过这也有好处,有一些极端的样例能轻松地构造出来,并且可以保证自己的程序不会在互测阶段受到极端样例的冲击,只不过对于很随机的样例程序有时候会垮掉。
当然讨论区和研讨课还给了我一种新的方法就是工厂模式,他可以完美解决我上述的代码复杂度分析中阐述的代码重复片段相似片段过高,尤其是调用构造方法的时候过于复杂的情况,所以在之后的程序中,构造也是需要集中思考一下的,不光是每个类的分工和职责。并且研讨课也有人提出了组合模式,这也是很好的组织架构。总之OO的课程让我认识到了好的程序不是机器能看懂,而是人能看懂的,希望自己之后能更好提取代码中的逻辑,写出好代码!