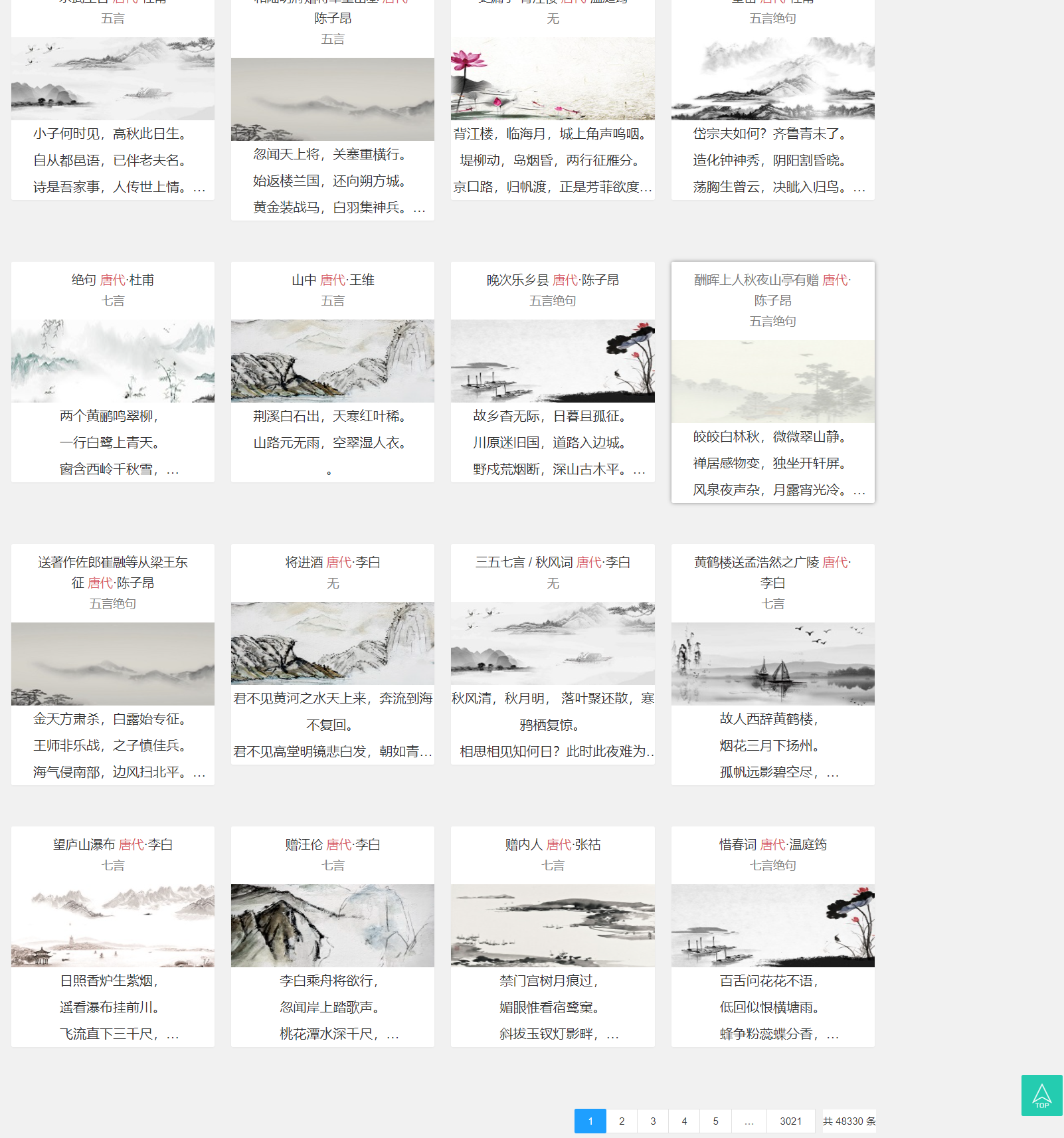
今日进度
诗人信息
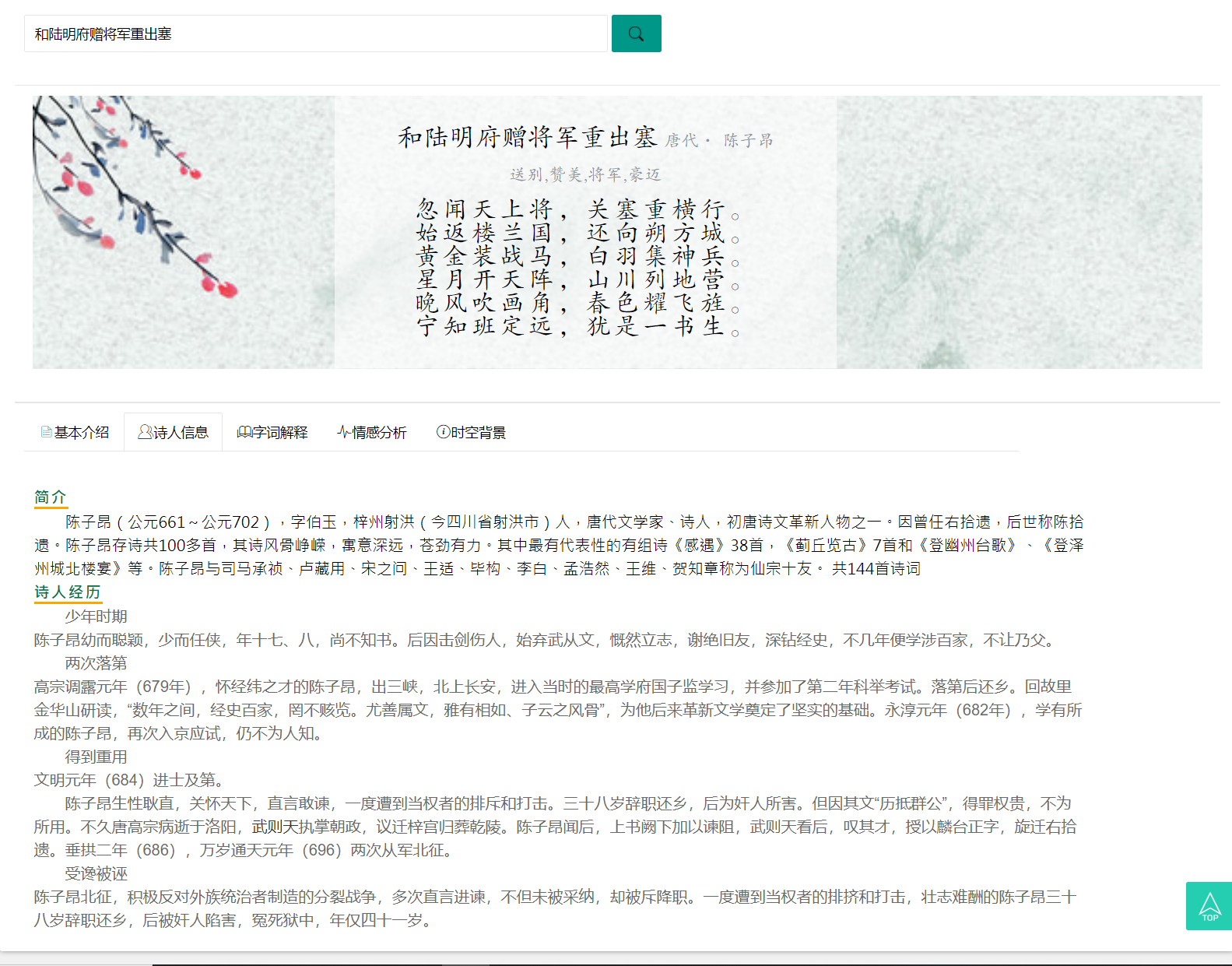
诗词注释
爬取诗词注释
import requests
from bs4 import BeautifulSoup
from lxml import etree
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息
pom_list=[]
k=1
for i in range(1,1000):
url='https://www.xungushici.com/shicis/cd-yuan-p-'+str(i)
r=requests.get(url,headers=headers)
content=r.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
hed=soup.find('div',class_='col col-sm-12 col-lg-9')
list=hed.find_all('div',class_="card mt-3")
# print(len(list))
for it in list:
content = {}
#1.1获取单页所有诗集
href=it.find('h4',class_='card-title').a['href']
real_href='https://www.xungushici.com'+href
title=it.find('h4',class_='card-title').a.text
print(title)
#2.1爬取诗词
r2 = requests.get(real_href, headers=headers)
content2 = r2.content.decode('utf-8')
soup2 = BeautifulSoup(content2, 'html.parser')
zhu = ""
if soup2.find('div',class_='card mt-3')==[]:
zhu="无"
content['title'] = title
content['zhu'] = zhu
pom_list.append(content)
print("第" + str(k) + "个")
k = k + 1
continue
card_div=soup2.find('div',class_='card mt-3')
if card_div==None or card_div.find('div',class_='card-body')==[]:
zhu="无"
content['title'] = title
content['zhu'] = zhu
pom_list.append(content)
print("第" + str(k) + "个")
k = k + 1
continue
card_body=card_div.find('div',class_='card-body')
p_list=card_body.find_all('p')
flag=1
for it in p_list:
if str(it).find('strong')!=-1 and it.find('strong').text=='注释':
flag=0
continue
if flag==0:
zhu=zhu+str(it)
if len(zhu)==0:
zhu="无"
content['title']=title
content['zhu']=zhu
pom_list.append(content)
print("第"+str(k)+"个")
k=k+1
import xlwt
xl = xlwt.Workbook()
# 调用对象的add_sheet方法
sheet1 = xl.add_sheet('sheet1', cell_overwrite_ok=True)
sheet1.write(0,0,"title")
sheet1.write(0,12,'zhu')
for i in range(0,len(pom_list)):
sheet1.write(i+1,0,pom_list[i]['title'])
sheet1.write(i+1, 12, pom_list[i]['zhu'])
xl.save("yuan.xlsx")
# print(pom_list)
展示效果
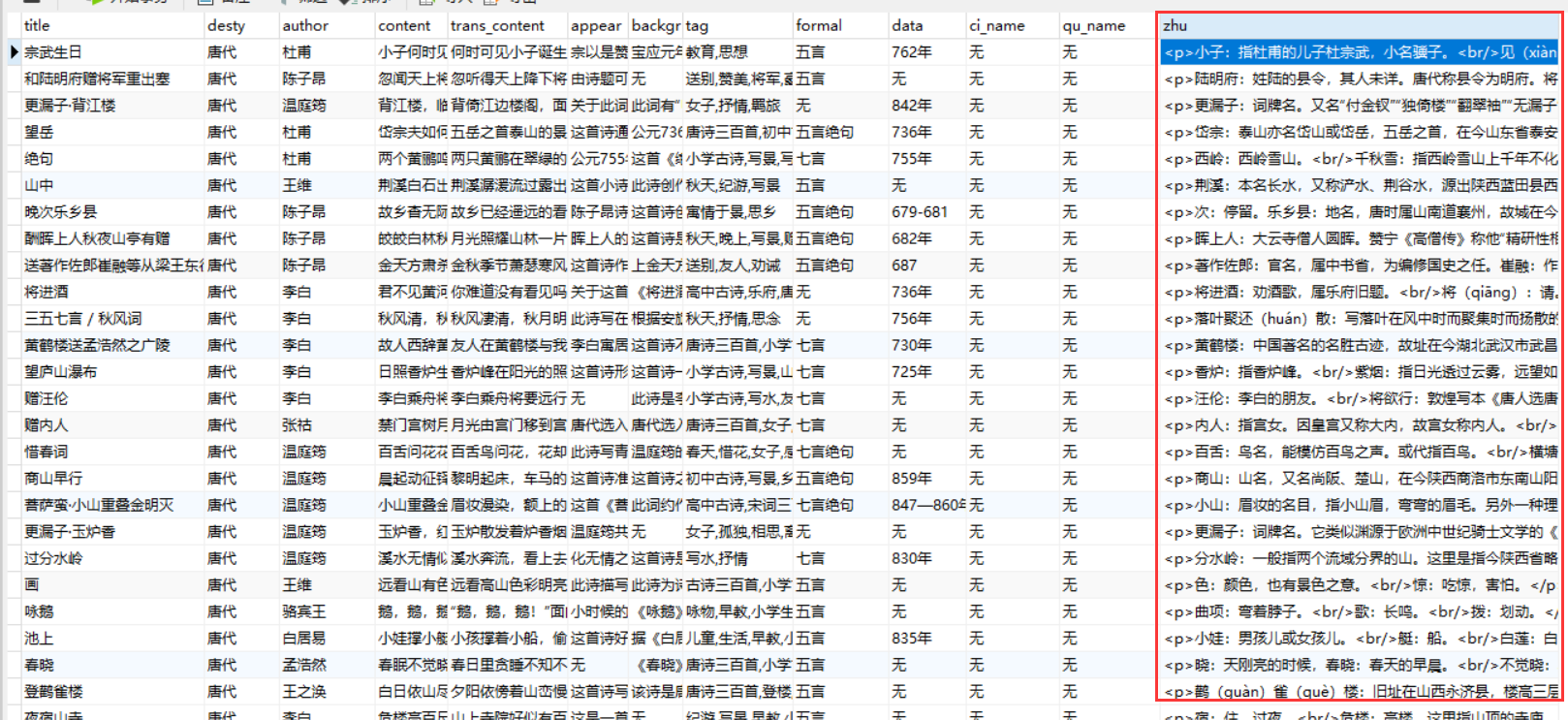
前端页面展示
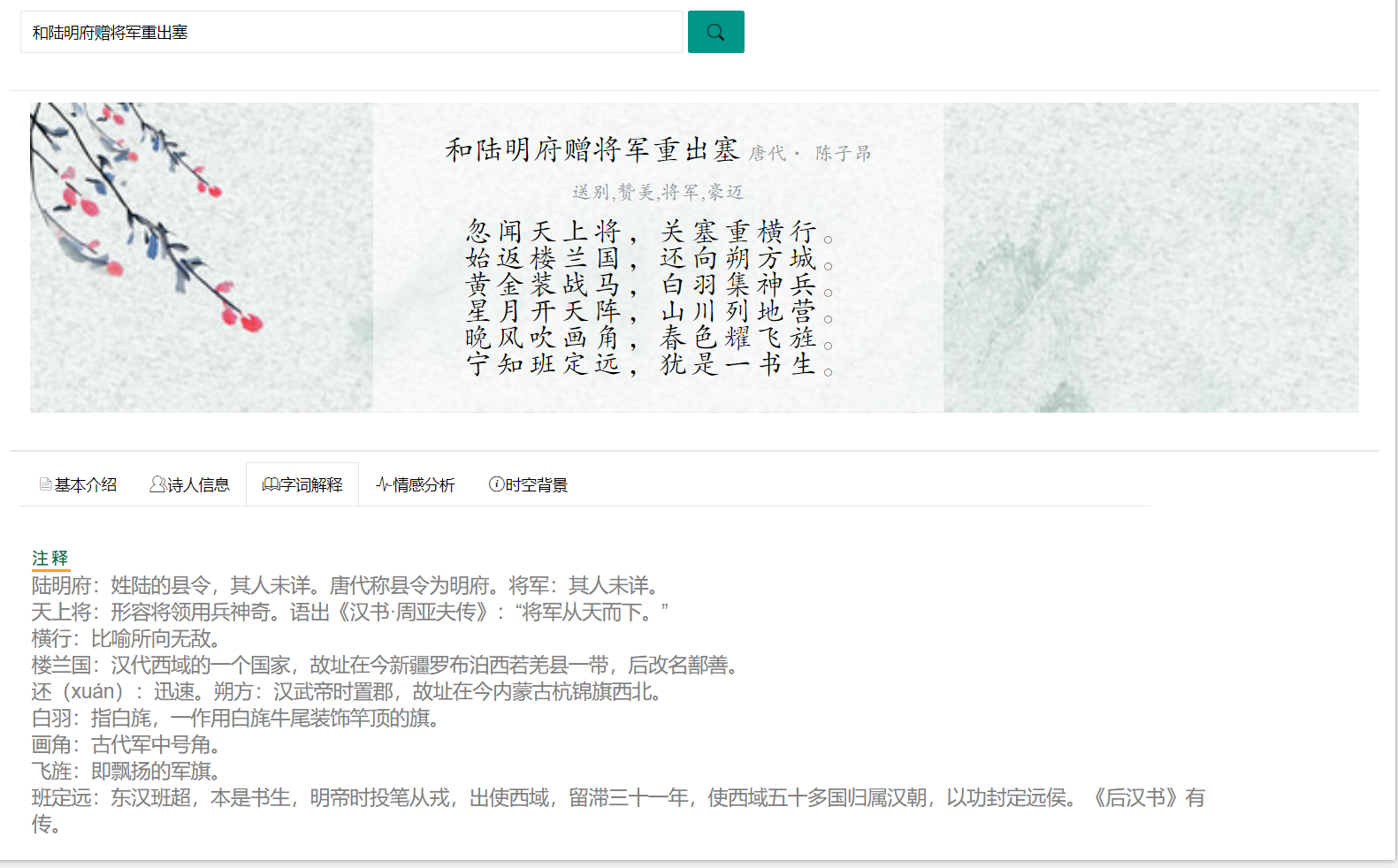
诗句美化
对句子按照句号分割展示,对于七言古诗按照逗号分行展示