诗词收集改进
改进
对formal形式为:七言,七言绝句,七言律诗的诗词进行收集
import pandas as pd
import re
#获取指定文件夹下的excel
import os
def get_filename(path,filetype): # 输入路径、文件类型例如'.xlsx'
name = []
for root,dirs,files in os.walk(path):
for i in files:
if os.path.splitext(i)[1]==filetype:
name.append(i)
return name # 输出由有后缀的文件名组成的列表
def read():
file = 'data/'
list = get_filename(file, '.xlsx')
qi_list=[]
for it in list:
newfile =file+it
print(newfile)
# 获取诗词内容
data = pd.read_excel(newfile)
formal=data.formal
content=data.content
for i in range(len(formal)):
fom=formal[i]
if fom=='七言绝句':
text=content[i].replace('\n','')
text_list=re.split('[,。]',text)
#print(text_list)
if len(text_list)==9 and len(text_list[len(text_list)-1])==0:
f = True
for i in range(len(text_list)-1):
it=text_list[i]
#print(len(it))
if len(it)!=7 or it.find('□')!=-1:
f=False
break
if f:
#print(text)
qi_list.append(text[:32])
qi_list.append(text[32:64])
elif fom=='七言':
text = content[i].replace('\n', '')
text_list = re.split('[,。]', text)
print(text_list)
if len(text_list)==5 and len(text_list[len(text_list)-1])==0:
f = True
for i in range(len(text_list)-1):
it=text_list[i]
print(len(it))
if len(it)!=7 or it.find('□')!=-1:
f=False
break
if f:
#print(text)
qi_list.append(text[:32])
elif fom=='七言律诗':
text = content[i].replace('\n', '')
text_list = re.split('[,。]', text)
print(text_list)
if len(text_list)==17 and len(text_list[len(text_list)-1])==0:
f = True
for i in range(len(text_list)-1):
it=text_list[i]
print(len(it))
if len(it)!=7 or it.find('□')!=-1:
f=False
break
if f:
#print(text)
qi_list.append(text[:32])
qi_list.append(text[32:64])
qi_list.append(text[64:96])
qi_list.append(text[96:128])
print(qi_list)
return qi_list
def write(content):
with open("./poem_train/qi_jueju.txt", "w", encoding="utf-8") as f:
for it in content:
f.write(it) # 自带文件关闭功能,不需要再写f.close()
f.write("\n")
if __name__ == '__main__':
content=read()
write(content)
成果
数据集扩充到4万条

藏头诗生成
代码
import torch
import torch.nn as nn
import numpy as np
from gensim.models.word2vec import Word2Vec
import pickle
from torch.utils.data import Dataset,DataLoader
import os
def split_poetry(file='qi_jueju.txt'):
all_data=open(file,"r",encoding="utf-8").read()
all_data_split=" ".join(all_data)
with open("split.txt","w",encoding='utf-8') as f:
f.write(all_data_split)
def train_vec(split_file='split.txt',org_file='qi_jueju.txt'):
#word2vec模型
vec_params_file="vec_params.pkl"
#判断切分文件是否存在,不存在进行切分
if os.path.exists(split_file)==False:
split_poetry()
#读取切分的文件
split_all_data=open(split_file,"r",encoding="utf-8").read().split("\n")
#读取原始文件
org_data=open(org_file,"r",encoding="utf-8").read().split("\n")
#存在模型文件就去加载,返回数据即可
if os.path.exists(vec_params_file):
return org_data,pickle.load(open(vec_params_file,"rb"))
#词向量大小:vector_size,构造word2vec模型,字维度107,只要出现一次就统计该字,workers=6同时工作
embedding_num=128
model=Word2Vec(split_all_data,vector_size=embedding_num,min_count=1,workers=6)
#保存模型
pickle.dump((model.syn1neg,model.wv.key_to_index,model.wv.index_to_key),open(vec_params_file,"wb"))
return org_data,(model.syn1neg,model.wv.key_to_index,model.wv.index_to_key)
class MyDataset(Dataset):
#数据打包
#加载所有数据
#存储和初始化变量
def __init__(self,all_data,w1,word_2_index):
self.w1=w1
self.word_2_index=word_2_index
self.all_data=all_data
#获取一条数据,并做处理
def __getitem__(self, index):
a_poetry_words = self.all_data[index]
a_poetry_index = [self.word_2_index[word] for word in a_poetry_words]
xs_index = a_poetry_index[:-1]
ys_index = a_poetry_index[1:]
#取出31个字,每个字对应107维度向量,【31,107】
xs_embedding=self.w1[xs_index]
return xs_embedding,np.array(ys_index).astype(np.int64)
#获取数据总长度
def __len__(self):
return len(self.all_data)
class Mymodel(nn.Module):
def __init__(self,embedding_num,hidden_num,word_size):
super(Mymodel, self).__init__()
self.embedding_num=embedding_num
self.hidden_num = hidden_num
self.word_size = word_size
#num_layer:两层,代表层数,出来后的维度[5,31,64],设置hidden_num=64
self.lstm=nn.LSTM(input_size=embedding_num,hidden_size=hidden_num,batch_first=True,num_layers=2,bidirectional=False)
#做一个随机失活,防止过拟合,同时可以保持生成的古诗不唯一
self.dropout=nn.Dropout(0.3)
#做一个flatten,将维度合并【5*31,64】
self.flatten=nn.Flatten(0,1)
#加一个线性层:[64,词库大小]
self.linear=nn.Linear(hidden_num,word_size)
#交叉熵
self.cross_entropy=nn.CrossEntropyLoss()
def forward(self,xs_embedding,h_0=None,c_0=None):
xs_embedding=xs_embedding.to(device)
if h_0==None or c_0==None:
#num_layers,batch_size,hidden_size
h_0=torch.tensor(np.zeros((2,xs_embedding.shape[0],self.hidden_num),np.float32))
c_0 = torch.tensor(np.zeros((2, xs_embedding.shape[0], self.hidden_num),np.float32))
h_0=h_0.to(device)
c_0=c_0.to(device)
hidden,(h_0,c_0)=self.lstm(xs_embedding,(h_0,c_0))
hidden_drop=self.dropout(hidden)
flatten_hidden=self.flatten(hidden_drop)
pre=self.linear(flatten_hidden)
return pre,(h_0,c_0)
#给出开头一个字,自动生成诗
def generate_poetry_auto(res):
result=res
#随机产生第一个字的下标
# word_index=np.random.randint(0,word_size,1)[0]
# result += index_2_word[word_index]
word_index=word_2_index[res]
h_0 = torch.tensor(np.zeros((2, 1, hidden_num), np.float32))
c_0 = torch.tensor(np.zeros((2, 1, hidden_num), np.float32))
for i in range(31):
word_embedding=torch.tensor(w1[word_index].reshape(1,1,-1))
pre,(h_0,c_0)=model(word_embedding,h_0,c_0)
word_index=int(torch.argmax(pre))
result+=index_2_word[word_index]
print(result)
#藏头诗
def cang(res):
result=''
punctuation_list = [",", "。", ",", "。"]
for i in range(len(res)):
result+=res[i]
word_index = word_2_index[res[i]]
h_0 = torch.tensor(np.zeros((2, 1, hidden_num), np.float32))
c_0 = torch.tensor(np.zeros((2, 1, hidden_num), np.float32))
for j in range(6):
word_embedding = torch.tensor(w1[word_index].reshape(1, 1, -1))
pre, (h_0, c_0) = model(word_embedding, h_0, c_0)
word_index = int(torch.argmax(pre))
result += index_2_word[word_index]
result+=punctuation_list[i]
print(result)
if __name__ == '__main__':
device="cuda" if torch.cuda.is_available() else "cpu"
#print(device)
#源数据小了,batch不能太大
batch_size=128
all_data,(w1,word_2_index,index_2_word)=train_vec()
dataset=MyDataset(all_data,w1,word_2_index)
dataloader=DataLoader(dataset,batch_size=batch_size,shuffle=True)
epoch=1000
word_size , embedding_num=w1.shape
lr=0.003
hidden_num=128
model_result_file='model_lstm.pkl'
#测试代码
if os.path.exists(model_result_file):
model=pickle.load(open(model_result_file, "rb"))
# 开头字
# result=input("请输入一个字:")
#generate_poetry_auto(result)
#藏头诗
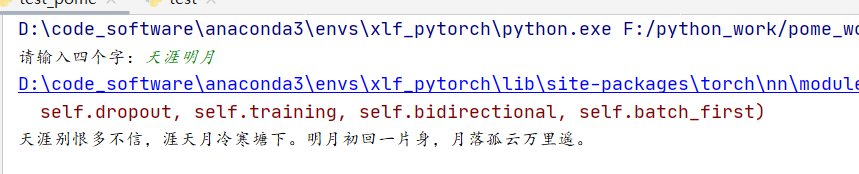
result=input("请输入四个字:")
cang(result)
结果
Snownlp正负情感分析
自定义数据集训练
源数据格式
三列:cat,label,review,我们只要后两列

先获取训练数据与测试数据
根据label标签,划分出积极和消极两种训练数据,保存到对应的csv进行训练
from snownlp import sentiment
import pandas as pd
def train_model():
data=pd.read_csv(r"DataSet.csv", header=0)
train=data.iloc[:40000,[1,2]]
test=data.iloc[40000:,[1,2]]
train_neg=train.iloc[:,1][train.label==0]
train_pos=train.iloc[:,1][train.label==1]
train_neg.to_csv(r"./neg.csv",index=0,header=0)
train_pos.to_csv(r"./pos.csv",index=0,header=0)
test.to_csv(r"./test.csv",index=0,columns=['label','review'])
sentiment.train(r'neg.csv', r'pos.csv')
sentiment.save(r'sentiment.marshal')
if __name__ == '__main__':
train_model()
测试集效果
对测试集数据提取review与label两列
用训练好的模型去评估,在于正确的label比对
其中:需要注意更换自己模型进行训练,需要找到该文件下的init,将默认的模型更换

import pandas as pd
from snownlp import SnowNLP
from snownlp import sentiment
if __name__ == '__main__':
test=pd.read_csv(r"test.csv")
review_list=[review for review in test['review']]
label_list=[label for label in test['label']]
list_test=[(label,review) for label,review in list(zip(label_list,review_list)) if type(review)!=float]
for j in list_test:
print(j[1],j[0],SnowNLP(j[1]).sentiments)
senti=[SnowNLP(review).sentiments for label,review in list_test]
newsenti=[]
for i in senti: #预测结果为pos的概率,大于0.6我们认定为积极评价
if(i>=0.6):
newsenti.append(1)
else:
newsenti.append(0)
counts=0
for i in range(len(list_test)):
if(newsenti[i]==list_test[i][0]):
counts+=1
accuracy=float(counts)/float(len(list_test))
print("准确率为:%.2f" %accuracy)
结果如下:

结语
摸索了情感分析后,它的整体流程大致这样,后续就要自己搭建模型进行情感分析
