有类型操作
flatMap
通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset
val ds1=Seq("hello spark","hello hadoop").toDS()
ds1.flatMap(item => item.split(" ")).show()
map
可以将数据集中每条数据转为另一种形式
val ds2=Seq(Person("zhangsan",15),Person("lisi",32)).toDS()
ds2.map(p => Person(p.name,p.age*2)).show()
mapPartitions
mapPartitions 和 map 一样, 但是 map 的处理单位是每条数据, mapPartitions 的处理单位是每个分区
ds2.mapPartitions(item => { val persons = item.map(p => Person(p.name, p.age * 2)) persons }).show()
transform
map 和 mapPartitions 以及 transform 都是转换, map 和 mapPartitions 是针对数据, 而 transform 是针对整个数据集, 这种方式最大的区别就是 transform 可以直接拿到 Dataset 进行操作
@Test def transform(): Unit ={ val ds=spark.range(10) ds.transform(dataset => dataset.withColumn("doubleid",'id*2)).show() }
as
as[Type] 算子的主要作用是将弱类型的 Dataset 转为强类型的 Dataset,
@Test def as(): Unit ={ val structType = StructType( Seq( StructField("name", StringType), StructField("age", IntegerType), StructField("gpa", FloatType) ) ) val sourceDF = spark.read .schema(structType) .option("delimiter", " ") .csv("dataset/studenttab10k") val dataset = sourceDF.as[(String,Int,Float)] dataset.show() }
filter
用来按照条件过滤数据集
@Test def filter(): Unit ={ val ds=Seq(Person("zhangsan",15),Person("lisi",32)).toDS() ds.filter(person => person.age>20).show() }
groupByKey
grouByKey 算子的返回结果是 KeyValueGroupedDataset, 而不是一个 Dataset, 所以必须要先经过 KeyValueGroupedDataset 中的方法进行聚合, 再转回 Dataset, 才能使用 Action 得出结果
@Test def groupByKey(): Unit ={ val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS() val grouped = ds.groupByKey(p => p.name) val result: Dataset[(String, Long)] = grouped.count() result.show() }
randomSplit
randomSplit 会按照传入的权重随机将一个 Dataset 分为多个 Dataset, 传入 randomSplit 的数组有多少个权重, 最终就会生成多少个 Dataset, 这些权重的加倍和应该为 1, 否则将被标准化
@Test def randomSplit(): Unit ={ val ds = spark.range(15) val datasets: Array[Dataset[lang.Long]] = ds.randomSplit(Array[Double](2, 3)) datasets.foreach(dataset => dataset.show()) ds.sample(withReplacement = false, fraction = 0.4).show() }
orderBy
orderBy 配合 Column 的 API, 可以实现正反序排列
val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS()
ds.orderBy('age.desc).show() //select * from .. order by .. desc
sort
ds.sort('age.asc).show()
dropDuplicates
使用 dropDuplicates 可以去掉某一些列中重复的行
@Test def dropDuplicates(): Unit ={ val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS() ds.distinct().show() ds.dropDuplicates("age").show() }
distinct
根据所有列去重
ds.distinct().show()
集合操作
差集,交集,并集,limit
@Test def collection(): Unit ={ val ds1=spark.range(1,10) val ds2=spark.range(5,15) //差集 ds1.except(ds2).show() //交集 ds1.intersect(ds2).show() //并集 ds1.union(ds2).show() //limit ds1.limit(3).show() }
无类型转换
选择
select:选择某些列出现在结果集中
selectExpr :在 SQL 语句中, 经常可以在 select 子句中使用 count(age), rand() 等函数, 在 selectExpr 中就可以使用这样的 SQL 表达式, 同时使用 select 配合 expr 函数也可以做到类似的效果
@Test def select(): Unit ={ val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS() ds.select('name).show() ds.selectExpr("sum(age)").show() }
withColumn:通过 Column 对象在 Dataset 中创建一个新的列或者修改原来的列
withColumnRenamed:修改列名
@Test def withcolumn(): Unit ={ import org.apache.spark.sql.functions._ val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS() ds.withColumn("random",expr("rand()")).show() ds.withColumn("name_new",'name).show() ds.withColumn("name_jok",'name === "").show() ds.withColumnRenamed("name","new_name").show() }
剪除
drop:减掉某列
@Test def drop(): Unit ={ import spark.implicits._ val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() ds.drop('age).show() }
集合
groupBy:按给定的行进行分组
@Test def groupBy(): Unit ={ import spark.implicits._ val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() ds.groupBy('name).count().show() }
Column 对象
创建
val spark=SparkSession.builder().master("local[6]").appName("trans").getOrCreate()
import spark.implicits._
@Test
def column(): Unit ={
import spark.implicits._
val personDF = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDF()
val c1: Symbol ='name
val c2: ColumnName =$"name"
import org.apache.spark.sql.functions._
val c3: Column =col("name")
//val c4: Column =column("name")
val c5: Column =personDF.col("name")
val c6: Column =personDF.apply("name")
val c7: Column =personDF("name")
personDF.select(c1).show()
personDF.where(c1 ==="zhangsan").show()
}
别名和转换
@Test def as(): Unit ={ val personDF = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDF() import org.apache.spark.sql.functions._ //as 用法1:更换数据类型 personDF.select(col("age").as[Long]).show() personDF.select('age.as[Long]).show() //as:用法二 personDF.select(col("age").as("new_age")).show() personDF.select('age as 'new_age ).show() }
添加列
val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS()
//增加一列
ds.withColumn("doubled",'age *2).show()
操作
like:模糊查询;isin:是否含有;sort:排序
//模糊查询 ds.where('name like "zhang%").show() //排序 ds.sort('age asc).show() //枚举判断 ds.where('name isin("zhangsan","wangwu","wxlf")).show()
聚合
package cn.itcast.spark.sql import org.apache.spark.sql.{RelationalGroupedDataset, SparkSession} import org.apache.spark.sql.types.{DoubleType, IntegerType, StructField, StructType} import org.junit.Test class Aggprocessor { val spark=SparkSession.builder().master("local[6]").appName("trans").getOrCreate() import spark.implicits._ @Test def groupBy(): Unit ={ val schema = StructType( List( StructField("id", IntegerType), StructField("year", IntegerType), StructField("month", IntegerType), StructField("day", IntegerType), StructField("hour", IntegerType), StructField("season", IntegerType), StructField("pm", DoubleType) ) ) //读取数据集 val sourceDF=spark.read .schema(schema) .option("header",value = true) .csv("dataset/beijingpm_with_nan.csv") //去掉pm为空的 val clearDF=sourceDF.where('pm =!= Double.NaN) //分组 val groupedDF: RelationalGroupedDataset = clearDF.groupBy('year, 'month) import org.apache.spark.sql.functions._ //进行聚合 groupedDF.agg(avg('pm) as("pm_avg")) .orderBy('pm_avg desc) .show() //方法二 groupedDF.avg("pm") .select($"avg(pm)" as "pm_avg") .orderBy('pm_avg desc) .show() groupedDF.max("pm").show() groupedDF.min("pm").show() groupedDF.sum("pm").show() groupedDF.count().show() groupedDF.mean("pm").show() } }
连接
无类型连接 join
@Test def join(): Unit ={ val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 0)) .toDF("id", "name", "cityId") val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou")) .toDF("id", "name") val df=person.join(cities, person.col("cityId") === cities.col("id")) .select(person.col("id"), person.col("name"), cities.col("name") as "city") df.createOrReplaceTempView("user_city") spark.sql("select id ,name,city from user_city where city=='Beijing'") .show() }
连接类型
交叉连接:cross交叉连接就是笛卡尔积, 就是两个表中所有的数据两两结对
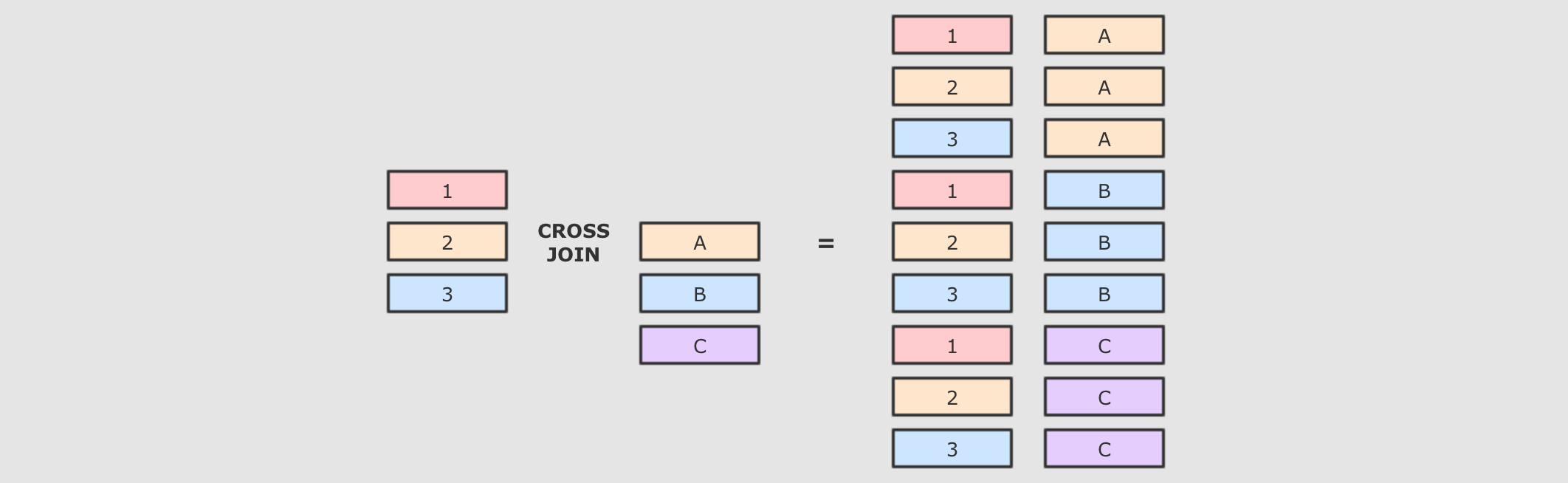
@Test def crossJoin(): Unit ={ person.crossJoin(cities) .where(person.col("cityId") === cities.col("id")) .show() spark.sql("select p.id,p.name,c.name from person p cross join cities c where p.cityId = c.id") .show() }
内连接:就是按照条件找到两个数据集关联的数据, 并且在生成的结果集中只存在能关联到的数据

@Test def inner(): Unit ={ person.join(cities,person.col("cityId")===cities.col("id"),joinType = "inner") .show() spark.sql("select p.id,p.name,c.name from person p inner join cities c on p.cityId=c.id").show() }
全外连接:

@Test def fullOuter(): Unit ={ person.join(cities,person.col("cityId") === cities.col("id"),joinType = "full") .show() spark.sql("select p.id,p.name,c.name from person p full outer join cities c on p.cityId=c.id") .show() }
左外连接

person.join(cities,person.col("cityId") === cities.col("id"),joinType = "left")
.show()
右外连接

person.join(cities,person.col("cityId") === cities.col("id"),joinType = "right")
.show()