TF-IDF提取关键词
问题提出:对于一篇文章,我们应该用什么样的词或者词组来检索它?
解决方法:自动提取一篇很长文章的关键词,有一种方法呢是(TF-IDF)
方法思路:哪种词出现的次数最多,那么这个词就是要很重要,这就有了词频Term Frequency,也称为呢(TF)统计
step 1:当然,使用最多的一定是这样诸如“的”、“是”、“在” ,我们把它叫做停用词 stop words,表示对结果毫无帮助,必须要过滤的词。我们应对其进行过滤。
step 2: 我们将停用词过滤掉之后呢,只考虑剩下的具有实际含义的词。但是不同的词组即使出现的次数一样多,也并不能代表这些词组的权重就是一样。因为文章要有突出,要有重点,比如说“南海”、“非洲”、“火车”,异或是“”中国“”蜜蜂“养殖”,显然呢,这三个如果同时出现,因为中国是很常见的词,相对来说,蜜蜂和养殖就不那么常见,那么如果这三个词放在一篇文章而且出现的次数一样多的话,对于词的排序上,蜜蜂和养殖的重要程度要大于中国。也就是在关键词排序上,蜜蜂和养殖应该排在中国的前面。所以我们要有一个重要性的调整系数,用来很亮一个词是不是常见词,如果某个词比较少见,但是呢,它在这篇文章中多次出现,那么,他可能很好的反映了这篇文章的特性,正是我们需要的关键词 ,也就是说,在词频的基础上,要在对每个词分配一个重要性的权重。例如,最常见的“的”是“在”了“给予最小的权重,常见的词例如”中国“基于较小的权重,较少见的词,例如”养殖“”蜜蜂“我们给予较大的权重,这个赋予词的权重,这个权重称为逆文档频率Inverse document frequency 缩写为(IDF) ,即不常见的词权重给的大。
step 3: 有了(TF) 词频,有了(IDF) 逆文档频率,也就是词的权重,将这两个值相乘,即得到这个词的TD-IDF值,这个值越高,就越可能是这篇文章的关键词。
方法实现:
-
统计词频,某个词的TF=这个词在文章中出现的次数,因为呢,文章有长短之分,肯定是越长文章的某个词的TF值越大,故为了统一标准,对其“标准化”,这个标准化不是严格的概率论上的标准化,TF值=(某个词在文章中出现的次数/文章的总的词数) ,或者是某个词在文章中出现的次数/该文章中出现最多次数的词在文章中出现的次数。
-
计算IDF逆文档频率,需要一个语料库corpus,用来模拟语言的使用环境,逆文档频率IDF=log(语料库的文档总数/包含该词的文档数+1),如果这个词越常见,纳闷log里面的东西就越接近1,总的频率就接近0,分母之所以要加1,是为了避免如果该次在文档中没有出现,避免其值为0
-
计算TF-IDF,TF-IDF=词频TX( imes) 逆文档频率IDF,我们可以看到TF-IDF与一个词在文档中出现的次数成正比,与该词在整个语料库中出现的次数成反比。
所以,取得一篇文章的关键词,就是计算文章中每个词的TF-IDF值,也就是计算每个词在文章中的得分,降序排列,取排在最前面的几个词。
实例:以“中国蜜蜂养殖”为例,假定该长度为1000个词,中国,蜜蜂,养殖各出现20次,则这三个词频TF值均为0.02.然后,搜索google发现,包含”的“字的网页总共具有250亿张,假定这就是中文网页总数。包含中国的网页具有62,3亿张,包含蜜蜂的网页具有0.484亿张,包含养殖的网页为0.973亿张,则他们的逆文档频率IDF与TF-IDF值为
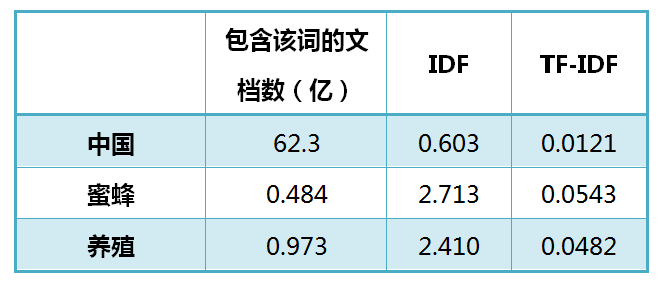
由表可以得到,蜜蜂的TF-IDE值最高,养殖其次,中国最低,要是还有计算TF-IDE的值,那会是极低。这个TD-IDF值不仅可知计算出文章的关键字,也可以对各个文章分别计算出文章中一组搜索词的TF-IDE值,,这个值最高的文档,就是搜索词最相关的文档。
TF-IDF优缺点:
- 缺点,单纯以词频来衡量一个词的重要性,不够全面,有时重要的词出现的次数可能并不多,其次,这种算法无法体现出有关于词的位置的信息,出现位置靠前的词与位置靠后的词,被视为相同的重要性,这是不正确的。解决方法呢,是赋予每段第一句话加大的权重。这个缺点主要是在TF方面。赋予每个位置的词不同的权重就可以解决。
总结TF-IDF有什么用:
- 总结出文章的关键词
- 对于要检索的一组词,找到所有文档中这一组词的TF-IDF值之和最高的文档,就是与要检索的一组词最相关的文档
- 对于相当大的检索目标,需要有一定的方式来检索最符合关键字的文档,比如LSH
来源:
大神1号