转自出处:
http://blog.csdn.net/walilk/article/details/50278697
符号说明:

以如下图为例:
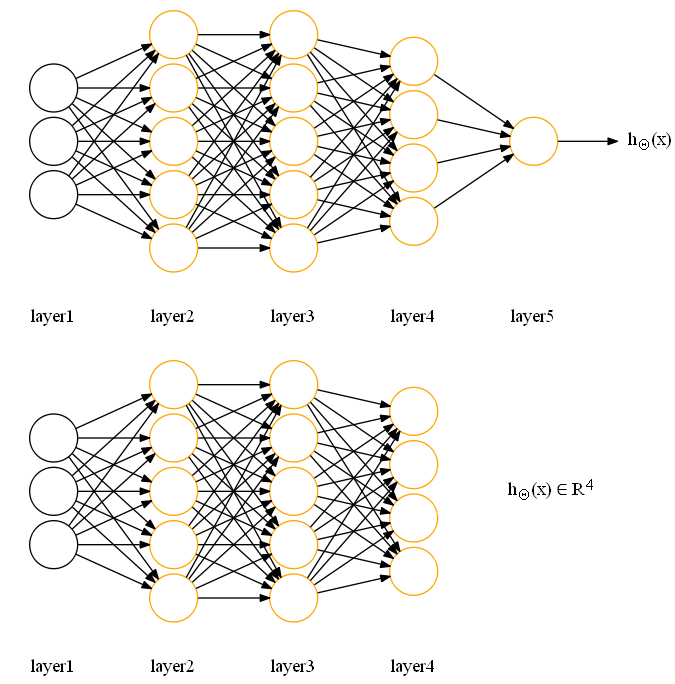
前面的网络结构对应二分类问题
后面的网络结构对应多分类问题
Layer层:
最左边的层为输入层(input layer),对应样本特征
最右边的层为输出层(output layer),对应预测结果
Node:
输入层节点:对应样本的特征输入,每一个节点表示样本的特征向量x中的一个特征变量或特征项
输出层节点:对应样本的预测输出,每个节点表示样本在不同类别下的预测概率
隐藏层节点:对应中间的激活计算,称为隐藏单元,在神经网络中隐藏单元的作用可以理解为对输入层的特征进行变换并将其进行层层转换传递到输出层进行类别预测
偏置单元:
它和线性方程y=wx+b中的b的意义是一致的,在y=wx+b中,b表示函数在y轴上的截距,控制着函数偏离原点的距离,在神经网络中偏置单元起到的是相同的作用。因此神经网络的参数表示为:(W,b),其中W表示参数矩阵,b表示偏置项或截距项
神经网络对偏置单元的处理方式分如下2种:
1、设置偏置单元=1,并在参数矩阵Θ中设置第0列对应偏置单元的参数,对应神经网络如下:
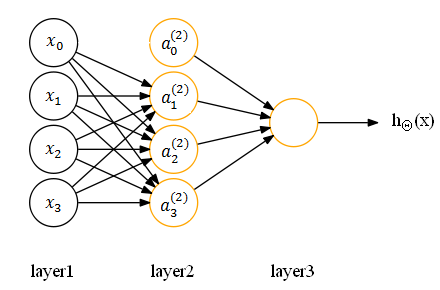
其中,x0是对应的偏置单元(设置1),![]() 表示对应偏置单元x0的参数,
表示对应偏置单元x0的参数,![]() 表示第二层的偏置单元,
表示第二层的偏置单元,![]() 是对应的参数。
是对应的参数。
计算激活函数以![]() 为例,按照如下来计算:
为例,按照如下来计算:
![]()
2、不在参数矩阵中设置偏置单元对应的参数,对应神经网络如下:
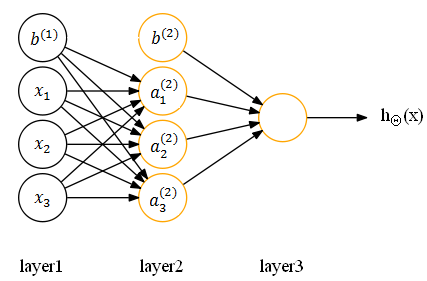
其中,![]() 是
是![]() 对应的偏置单元向量,
对应的偏置单元向量,![]() 是
是![]() 对应的偏置单元向量,
对应的偏置单元向量,![]() 是
是![]() 所对应的偏置单元,因而激活值可以表示为如下:
所对应的偏置单元,因而激活值可以表示为如下:
![]()
其表示形式与上一部分原理相同。
激活函数:
激活单元的计算过程称为激活,指一个神经元读入特征,执行计算并产生输出的过程。
激活函数是非线性函数,用于为神经网络模型加入非线性因素,使其能够处理复杂的非线性任务。一般情况下激活函数有如下几种方式:
(1)sigmoid函数(0~1):
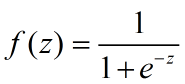
(2)tanh函数(-1~1):
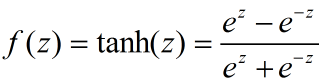
(3)ReLu函数(![]() )
)
![]()
目前ReLu函数在神经网络模型研究及实际应用中较多,因为sigmoid或tanh作为激活函数做无监督学习时,遇到梯度消失问题导致无法收敛,而ReLu可以避免这个问题,此外基于ReLu这种现行激活函数的神经网络计算开销较低。
注:
激活函数额作用可以看作是从原始特征学习出新特征,或是将原始特征从低维空间映射到高维空间。引入激活函数是神经网络具有优异性能的关键所在,多层级联的结构加上激活函数令多层神经网络可以逼近任意函数,从而学习出复杂的假设函数。
假设函数:
如果神经网络采用sigmoid函数作为激活函数,那么其假设函数就与逻辑回归模型一致,也是一个sigmoid函数,可以看作是一个条件概率:P(y=1|x;Θ)
对于神经网络,预测值的计算是一个逐层递进的过程,以神经网络为例:
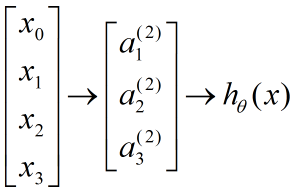
其预测值得计算过程如下:
计算隐藏单元的激活值:
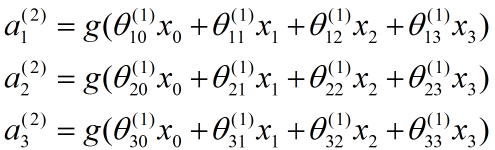
计算得到下一层的某节点输出:
![]()
可以发现,无论网络结构中有多少个隐藏层,在最后计算假设函数的时候,其实是和逻辑回归是一致的,只是逻辑回归直接对样本特征计算,而神经网络中是对隐藏单元的激活值计算。
从计算过程可以发现,神经网络在对样本进行预测时,从输入层开始,层层向前计算激活值,直观上是一种层层向前传播或是层层向前激活的过程,最终计算出![]() ,这个过程称为前向传播。
,这个过程称为前向传播。
注:
神经网络计算输出的过程称为前向传播,无论多复杂的神经网络,在前向传播过程中也是在不断的计算激活函数,从输入层一直计算到输出层,最后得到样本的预测标签。
模型对比:
1、基础模型对比
只具有一层(一个输入层)的神经网络模型,其实就是标准的逻辑回归模型(逻辑回归就是激活函数是sigmoid的单层简单神经网络)
注:sigmoid函数的表示形式:
![]()
对比如下:
逻辑回归:
![]()
神经网络:
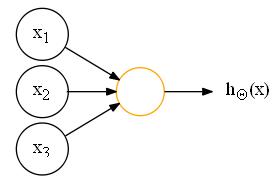
可以说,神经网络就是由一个个逻辑回归模型连接而成,它们彼此作为输入和输出。
2、多分类模型对比
在逻辑回归中,决策边界(用于对原始数据进行划分)由![]() 决定,随着参数项的增加,逻辑回归可以在原始特征空间学习出一个非常复杂的非线性决策边界(也就是一个复杂非线性方程);
决定,随着参数项的增加,逻辑回归可以在原始特征空间学习出一个非常复杂的非线性决策边界(也就是一个复杂非线性方程);
在神经网络中,决策边界由![]() 决定(这只是一个象征性表达式,Θ表示所有权重矩阵,x表示特征加上所有隐藏单元),神经网络并未直接在原始特征空间学习决策边界,而是将分类问题映射到新的特征空间,通过新特征空间学习决策边界,来解决原始特征空间的分类问题。
决定(这只是一个象征性表达式,Θ表示所有权重矩阵,x表示特征加上所有隐藏单元),神经网络并未直接在原始特征空间学习决策边界,而是将分类问题映射到新的特征空间,通过新特征空间学习决策边界,来解决原始特征空间的分类问题。
3、性能对比
在决策边界对比部分可以发现,逻辑回归和神经网络都可以学习复杂非线性边界,那么神经网络的相对优势在于:
如果给定基础特征的数量为100,在利用逻辑回归解决复杂分类问题时会遇到特征项爆炸增长,导致过拟合及运算量过大问题。
例:
在n=100情况下构建二次项特征变量,最终有5050个二次项,随着特征个数n的增加,二次项的个数大约以n^2的量级增长,其中n是原始项的个数,二次项的个数大约为(n^2)/2个
这种无法再一开始就进行优化,因为难确定哪一个高次项是有用的,因此必须找到所有的二次项进行训练,在训练后通过不同权重来判别
对于神经网络来说可以通过隐层数量和隐藏层单元数量来控制函数的复杂程度,并在计算时只计算一次项特征变量,本质上来说神经网络是通过这样一个网络结构隐含的找到了所需要的高次特征项,来简化计算。
现有常用的神经网络模型:
深度神经网络:从某种程度来说就是以前n-1层对训练样本进行特征提取,最后一层进入全连接层得到最终结果。