1》HeartBeat介绍
Heartbeat 项目是 Linux-HA 工程的一个组成部分,它实现了一个高可用集群系统。心跳服务和集群通信是高可用集群的两个关键组件,在 Heartbeat 项目里, 由 heartbeat 模块实现了这两个功能;
2》HeartBeat的组成
Heartbeat内部结构由三大部分组成:
(1)集群成员一致性管理模块(CCM)
CCM用于管理集群节点成员,同时管理成员之间的关系和节点间资源的分配。Heartbeat模块负责检测主次节点的运行状态,以决定节点是否失效。ha- logd模块用于记录集群中所有模块和服务的运行信息;
(2)本地资源管理器(LRM)
LRM负责本地资源的启动、停止和监控,一般由LRM守护进程lrmd和节点监控进程Stonith Daemon组成。lrmd守护进程负责节点间的通信;Stonith Daemon通常是一个Fence设备,主要用于监控节点状态,当一个节点出现问题时处于正常状态的节点会通过Fence设备将其重启或关机以释放IP、 磁盘等资 源,始终保持资源被一个节点拥有,防止资源争用的发生;
REDHAT的fence device有两种,内部fence设备(如IBM RSAII卡,HP的iLO卡,Dell的DRAC,还有IPMI的设备等)和外部fence 设备(如UPS,SAN SWITCH,NETWORK SWITCH等):
对于外部fence 设备,可以做拔电源的测试,因为备机可以接受到fence device返回的信号,备机可以正常接管服务;
对于内部fence 设备,不能做拔电源的测试,因为主机断电后,备机接受不到主板芯片做为fence device返备的信号,就不能接管服务,clustat会看到资源的 属主是unknow,查看日志会看到持续报fence failed的信息;
(3)集群资源管理模块(CRM)
CRM用于处理节点和资源之间的依赖关系,同时,管理节点对资源的使用,一般由CRM守护进程crmd、集群策略引擎和集群转移引擎3个部分组成。 集 群策略引擎(Cluster policy engine)具体实施这些管理和依赖;集群转移引擎(Cluster transition engine)监控CRM模块的状态,当一个节点出现故障时,负 责协调另一个节点上的进程进行合理的资源接管;
3》 原理:
heartbeat (Linux-HA)的工作原理:heartbeat最核心的包括两个部分,心跳监测部分和资源接管部分,心跳监测可以通过网络链路和串口进行,而且支 持 冗 余链路(心跳一般会接2条跳线,1条冗余),它们之间相互发送报文来告诉对方自己当前的状态,如果在指定的时间内未收到对方发送的报文,那么就认为对 方失效,这时需启动资源接管模块来接管运 行在对方主机上的资源或者服务;

迷你机上安装时遇到问题解决方法:
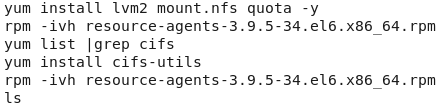
4》HeartBeat的使用:
1>HeartBeat安装
首先将本地YUM源头配置。在安装外部YUM源头的RPM包,保持你的机器可以上网。
# rpm –vih epel-release-6-8.noarch.rpm
# yum –y install heartbeat*
2>复制heartbeat的配置文件
Heartbeat的配置主要涉及到ha.cf、haresources、authkeys这三个文件。其中ha.cf是主配置文件,haresource用来配置要让Heartbeat托管的服 务,authkey是用来指定Heartbeat的认证方式;
#cp /usr/share/doc/heartbeat-3.0.4/ha.cf /etc/ha.d/
#cp /usr/share/doc/heartbeat-3.0.4/haresources /etc/ha.d/
#cp /usr/share/doc/heartbeat-3.0.4/authkeys /etc/ha.d
# cp -R /usr/local/drbd/etc/ha.d/resource.d/* /etc/ha.d/resource.d
3>authkeys配置
· authkeys的配置方式:
# vim authkeys
auth 1 //认证序号1
1 crc //序号1 采用crc
auth 后面填写序号,可任意填写,但第二行开头必须为序号名,然后为验证方式,支持三种( crc md5 sha1 )方式验证,最后面是自定义密钥;
· 需要保证authkeys有相应的读写权限:
# chmod 600 /etc/heartbeat/ha.d/authkeys
4>ha.cf主配置文件
# vim /etc/ha.d/ha.cf
debugfile /var/log/ha-debug #调试日志文件
logfile /var/log/ha-log #系统运行日志文件
logfacility local0 #日志记录等级
keepalive 2 #心跳频率,2表示2秒;200ms则表示200毫秒
deadtime 10 #节点死亡时间,就是过了10秒后还没有收到心跳就认为主节点死亡
warntime 5 #告警时间
initdead 120 #初始化时间
udpport 694 #心跳信息传递的udp端口
#bcast eth1 #采用udp广播播来通知心跳,建议在备用节点不只一台时使用
#mcast eth1 225.0.0.1 694 1 0 #采用udp多播来通知心跳,建议在备用节点不只一台时使用
bcast eth2 #采用udp单播来通知心跳,注意:这一项在2个节点IP
auto_failback on
#如果主节点重新恢复过来,主节点将主动将资源抢占过来,如果为off,则只当备用节点当掉后,主节点才取回资源
watchdog /dev/watchdog
#看门狗。如果本节点在超过1分钟后还没有发出心跳,那么本节点自动重启
node master #主节点名称,与uname -n显示必须一致
node slave #备用节点名称
respawn hacluster /usr/lib64/heartbeat/ipfail #
apiauth ipfail gid=haclient uid=hacluster
5>haresources资源配置文件
# vim /etc/ha.d/haresources
master IPaddr::10.0.0.215/16/eth1:0 drbddisk::r1 Filesystem::/dev/drbd0::/data::ext4
master是HA集群的主节点的主机名字,
IPaddr为heartbeat自带的一个执行脚
10.0.0.215/16/eth1:0 指的VIP在主节点的eth1:0这个接口上运行。
drbddisk::r1 是drbd在编译的加参数—with-heartbeat所产生的资源切换脚本。r1代表资源名称为r1,跟drbd里面的*.res配置文件保持一致。
Filesystem::/dev/drbd0::/data::ext4 带表系统所挂在的设备和目录以及文件系统格式。
其它的格式写法举例子:
node1 IPaddr::192.168.60.200/24/eth0/ Filesystem:: /dev/sdb5::/webdata::ext3 httpd tomcat
其中,node1是HA集群的主节点,IPaddr为heartbeat自带的一个执行脚 步,Heartbeat首先将执行/etc/ha.d/resource.d/IPaddr 192.168.60.200/24 start的操作,也就是虚拟出一个子网掩码为255.255.255.0,IP为192.168.60.200的地址。此IP为Heartbeat对外 提供服务的网络地 址,同时指定此IP使用的网络接口为eth0。接着,Heartbeat将执行共享磁盘分区的挂载操 作,"Filesystem::/dev/sdb5::/webdata::ext3"相当于在命令行下 执行mount操作,即"mount -t ext3 /dev/sdb5 /webdata",最后依次启动httpd和Tomcat服务;
5》验证和测试:
启动主节点和从节点的heartbeat服务.
# /etc/init.d/heartbeat start
# ip add list 查看主节点是否有VIP?
# df –lh 查看/dev/drbd0 设备是否挂在成功?
验证是否可以资源接管?
在主上,将/etc/init.d/heatbeat 服务停止。然后看看从服务器是否可以快速接管?
# /etc/init.d/heartbeat stop