1》DRBD介绍
1>数据镜像软件DRBD介绍
分布式块设备复制(Distributed Relicated Block Deivce,DRBD),是一种基于软件、基于网络的块复制存储解决方案,主要用于对服务器之间的磁盘分 区、逻辑卷等进行数据镜像,当用户将数据写入本地磁盘时,还会将数据发送到网络中另一台主机的磁盘上,这样的本地主机(主节点)与远程主机(备节点) 的数据就可以保证实时同步,当本地主机出现问题,远程主机上还保留着一份相同的数据,可以继续使用,保证了数据的安全;
2>DRBD的基本功能
DRBD的核心功能就是数据的镜像,其实现方式是通过网络来镜像整个磁盘设备或者磁盘分区,将一个节点的数据通过网络实时地传送到另外一个远 程节点,保证两个节点间数据的一致性,这有点类似于一个网络RAID1的功能,对于DRBD数据镜像来说,它具有如下特点:
实时性: 当应用对磁盘数据有修改操作时,数据复制立即发生;
透明性: 应用程序的数据存储在镜像设备上是透明和独立的,数据可以存储在基于网络不同服务器上;
同步镜像: 当本地应用申请写操作时,同时也在远程主机上开始进行写操作;
异步镜像: 当本地写操作已经完成时,才开始对远程主机上进行写操作;
3>DBRD的构成
DRBD是Linux内核存储层中的一个分布式存储系统,具体来说两部分构成,
(1) 一部分:内核模板,主要用于虚拟一个块设备;
(2) 一部分:是用户控件管理程序,主要用于和DRBD内核模块通信,以管理DRBD资源,
在DRBD中,资源主要包含DRBD设备,磁盘配置,网络配置等;
一个DRBD系统有两个以上的节点构成,分为主节点和备节点两个角色,在主节点上,可以对DRBD设备进行不受限制的读写操作,可以用初始化、创 建、挂在文件系统,在备节点上,DRBD设备无法挂载,只能用来接收主节点发送过来的数据,也就是说备节点不能用于读写访问,这样的目的是保证数据 缓冲区的一致性;
主用节点和备用节点不是一成不变的。可以通过手工的方式改变节点的角色,备用节点可以升级为主节点,主节点也降级为备节点;
DRBD设备在整个DRBD系统中位于物理块设备上,文件系统之下,在文件系统和物理磁盘之间形成了一个中间层,当用户在主节点的文件系统中写入 数据时,数据被正式写入磁盘前会被DRBD系统截获,同时,DRBD在捕捉到有磁盘写入的操作时,就会通知用户控件管理程序把这些数据复制一份。写入 远程主机的DRBD镜像,然后存入DRBD镜像所有映射的远程主机磁盘;
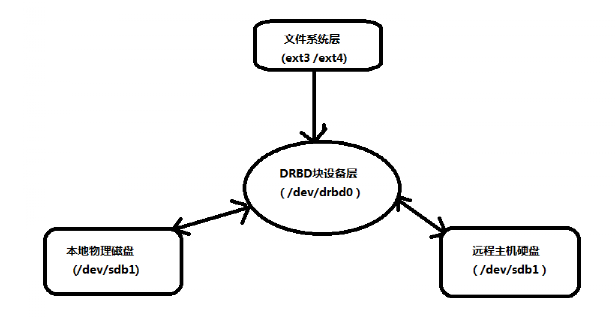
DRBD负责接收数据,把数据写到本地磁盘,然后发送给另一台主机,另一台主机再将数据存到自己的磁盘中,目前,DRBD每次只允许对一个节点 进行读写访问,这对于通常的故障切换高可用性集群来讲已经足够用了;
4>DRBD与集群的关系
DRBD由两个或者两个以上节点构成,与HA集群类似,也有主节点和备节点之分,因而经常用于高可用集群和负载集群系统中作,由于DRBD系 统是在IP网络运行,所以,在集群中使用DRBD作为共享存储设备,不需要任何硬件投资,可以节约很多成本,因为在价格上IP网络要比专用的存储网络更加 经济。另外DRBD也可以用于数据备份、数据容灾等方面;
5>DRBD的主要特性
DRBD系统在实现数据镜像方面有很多有用的特性,我们可以根据自己的需求和应用环境,选择合适自己的功能特性。下面介绍DRBD几个非常重要的特 性:
(1)单主模式:
这是使用最频繁的一种模式,主要用于在高可用集群的数据存储方面,解决集中数据共享的问题,在这种模式下,集群中只有一个主节点可以对数据 进行读写操作,可以用在这种模式下的文件系统有EXT3 EXT4 XFS等;
(2)双主模式:
这种模式只能在DRBD8.0以后的版本使用,主要用于负载均衡集中,解决数据共享和一致性问题,在这种模式下,集群中存在两个主节点,由于两个 主节点都有可能对数据进行并发操作的读写操作,因此单一的文件系统就无法满足需求了,因此需要共享的集群文件系统来解决并发读写问题,常用在这 种模式下的文件系统有GFS,OCFS2等,通过集群文件系统的分布式锁机制就可以解决集群中两个主节点同时操作数据的问题;
(3)复制模式
DRBD提供了三种不同的复制方式,分别是;
协议A: 只要本地磁盘写入已经完成,数据包已经在发送队列中,则认为一个写操作过程已经完成,这种方式在远程节点故障或者网络故障时,可能造成 数据丢失,因为要写入到远程节点的数据可能还在发送队列中;
协议B:只要本地磁盘写入已经完成,并且数据包已经到达远程节点,则认为一个写操作过程已经完成,这种方式在远程节点发生故障时,肯能造成数据丢 失;
协议C: 只有本地和远程节点的磁盘已经都确认了写操作完成,则认为一个写操作过程已经完成,这种方式没有任何数据丢失,就目前而已应用最多,最广 泛的就是协议C,旦在此方式下磁盘的I/O的吞吐量依赖于网络带宽,建议在网络带宽比较好的情况下使用这种方式。
protocol C; #使用drbd的同步协议
(4)传输的完整性校验
这个特性在DRBD8.20及以后版本中可以使用,DRBD使用MD5、SHA-1,或者CRC 32C等加密算法对信息进行终端到终端的完整性验证,利用这个特 性,DRBD对每一个复制到远程节点数据都生成信息摘要,同时,远程节点也采用同样的方式对复制的数据块进行完整性验证,如果验证信息不对,就请求 主节点重新发送,通过这种方式保证镜像数据的完整性和一致性;
(5)脑裂通知和自动修复。
由于集群节点之间的网络连接临时故障、集群软件管理干预或者人为错误,导致DRBD两个节点都切换为主节点而断开连接,这就是DRBD的脑裂问 题,发生脑裂意味着数据不能同步从主节点复制到备用节点,这样导致DRBD两个节点的数据不一致,并且无法合并, 在DRBD8.0以及更高的版本,实现了 脑裂自动修复功能,在DRBD8.2.1之后。又实现了脑裂通知特性,在出现脑裂后,一般建议通过手工方式修复脑裂问题;
2》DRBD安装
1>环境描述
系统版本:redhat6.4 x64(内核2.6.32)
DRBD版本: DRBD-8.4.3
node1: 10.0.0.201(主机名:master)
node2: 10.0.0.202 (主机名:slave)
(node1)为仅主节点配置 Primary
(node2)为仅从节点配置Secondary
(node1,node2)为主从节点共同配置
2>服务器时间同步以及关闭防火墙Selinux
#/etc/init.d/iptables stop 关闭防火墙
#setenforce 0 关闭Selinux
# cat /etc/selinux/config
SELINUX=disabled
#ntpdate -u asia.pool.ntp.org 真实环境这样同步
# date –s “2014-09-24 15:55:33” 测试时间。临时可以这样同步,两台机器都迅速执行此命令
3>修改主机名
#:vim /etc/sysconfig/network 主节点 201
HOSTNAME=master
#:vim /etc/sysconfig/network 从节点202
HOSTNAME=slave
如果使用虚拟机器做测试,还没有增加硬盘的的话,请关闭虚拟机器,开始增加一块硬盘,如果原有的虚拟机硬盘还有空间的话。拿出一块空间,做一个分 区也行;
4>所有节点增加硬盘
在主节点201 和从节点202上。划分增加的/dev/sdb 硬盘。进行分区
# fdisk /dev/sdb
分一个叫做/dev/sdb1分区出来就可以,注意千万不要格式化它,划分出来就行了,不需要格式化;
5>所有的节点安装
在主节点201和从节点202上同时安装
# wget http://oss.linbit.com/drbd/8.4/drbd-8.4.3.tar.gz
# tar zxvf drbd-8.4.3.tar.gz
# cd drbd-8.4.3
# ./configure --prefix=/usr/local/drbd --with-km --with-heartbeat km代表开启内核模块
./configure命令中添加--with-heartbeat,安装完成后会在/usr/local/drbd/etc/ha.d /resource.d生成drbddisk和drbdupper文件,把这两个文件复制 到/usr/local/heartbeat/etc/ha.d /resource.d目录,命令cp -R /usr/local/drbd/etc/ha.d/resource.d/* /etc/ha.d/resource.d;
# make KDIR=/usr/src/kernels/2.6.32-279.el6.x86_64/
# make install
# mkdir -p /usr/local/drbd/var/run/drbd
# cp /usr/local/drbd/etc/rc.d/init.d/drbd /etc/rc.d/init.d
# chkconfig --add drbd
# chkconfig drbd on
加载DRBD模块:
# modprobe drbd
查看DRBD模块是否加载到内核:
# lsmod |grep drbd
6>所有节点配置文件
在主节点201和从节点202 配置文件保持一致。
# /usr/local/drbd/etc/drbd.conf
drbd.conf 包含了2个类型的文件。为了方便起见全局配置和资源配置分开了。global_common.conf为固定全局配置文件,*.res 可以包含多个,跟 Nginx虚拟机器一样*.res 带包含了所有的资源文件;
(1) 修改全局配置文件:
global {
usage-count yes; #是否参加drbd的使用者统计,默认此选项为yes
# minor-count dialog-refresh disable-ip-verification
}
common {
protocol C; #使用drbd的同步协议
handlers {
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when chosing your poison.
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; #默认 是注释的开启来
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; #默认是 注释的开启来
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f"; #默认是注释的开 启来
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
}
options {
# cpu-mask on-no-data-accessible
}
disk {
on-io-error detach; #配置I/O错误处理策略为分离
# size max-bio-bvecs on-io-error fencing disk-barrier disk-flushes
# disk-drain md-flushes resync-rate resync-after al-extents
# c-plan-ahead c-delay-target c-fill-target c-max-rate
# c-min-rate disk-timeout
}
net {
# protocol timeout max-epoch-size max-buffers unplug-watermark
# connect-int ping-int sndbuf-size rcvbuf-size ko-count
# allow-two-primaries cram-hmac-alg shared-secret after-sb-0pri
# after-sb-1pri after-sb-2pri always-asbp rr-conflict
# ping-timeout data-integrity-alg tcp-cork on-congestion
# congestion-fill congestion-extents csums-alg verify-alg
# use-rle
}
syncer {
rate 1024M; #设置主备节点同步时的网络速率
}
}
(2)创建资源配置文件
资源文件需要自己手工创建,目录是在/usr/local/drbd/etc/drbd.d下面
#cd /usr/local/drbd/etc/drbd.d
# vim drbd.res
resource r1 { #这个r1是定义资源的名字
on master{ #on开头,后面是主机名称
device /dev/drbd0; #drbd设备名称
disk /dev/sdb1; #drbd0使用的磁盘分区为sdb1
address 10.0.0.201:7789; #设置drbd监听地址与端口
meta-disk internal;
}
on slave{ #on开头,后面是主机名称
device /dev/drbd0; #drbd设备名称
disk /dev/sdb1; #drbd0使用的磁盘分区为sdb1
address 10.0.0.202:7789; #设置drbd监听地址与端口
meta-disk internal;
}
}
7>激活节点启动服务
在主节点201 从节点202 做同样的操作
(1)激活和创建设备块
# mknod /dev/drbd0 b 147 0
# drbdadm create-md r1 资源名称为r1
等待片刻,显示success表示drbd块创建成功
Writing meta data...
initializing activity log
NOT initializing bitmap
New drbd meta data block successfully created.
(2)如果卡主不动了。再次输入该命令:
# drbdadm create-md r1
成功激活r0
----------------
[need to type 'yes' to confirm] yes
Writing meta data...
initializing activity log
NOT initializing bitmap
New drbd meta data block successfully created.
(3)准备启动服务: 启动DRBD服务:(node1,node2)
注:需要主从共同启动方能生效
# service drbd start
(4)查看状态:(node1,node2)
# cat /proc/drbd 或 # service drbd status
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by root@server.alvin.com,
2013-05-27 20:45:19
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:1060184
这里ro:Secondary/Secondary表示两台主机的状态都是备机状态,ds是磁盘状态,显示的状态内容为“不一致”,这是因为DRBD无法判断哪一方 为主机,应以哪一方的磁盘数据作为标准;
(5)授权节点201为,主节点
# drbdsetup /dev/drbd0 primary --force
(6)分别查看主从DRBD状态:
1)(主节点201 node1)
# service drbd status
--------------------
drbd driver loaded OK; device status:
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by root@drbd1.example.com,
2017-10-16 20:45:19
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C
===============================================================================
.2)(从节点202 node2)
# service drbd status
drbd driver loaded OK; device status:
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by root@drbd2.example.com,
2017-10-16 20:49:06
m:res cs ro ds p mounted fstype
0:r0 Connected Secondary/Primary UpToDate/UpToDate C
---------------------
ro在主从服务器上分别显示 Primary/Secondary和Secondary/Primaryds显示UpToDate/UpToDate表示主从配置成功。
8>挂在drbd0设备(主节点201)
从刚才的状态上看到mounted和fstype参数为空,所以我们这步开始挂载DRBD到系统目录
# mkdir /data
# mkfs.ext4 /dev/drbd0
# mount /dev/drbd0 /data
注:Secondary节点上不允许对DRBD设备进行任何操作,包括只读,所有的读写操作只能在Primary节点上进行,只有当Primary节点挂掉时, Secondary节点才能提升为Primary节点继续工作
9>模拟DRBD1 故障,DRBD2()接管并提升为Primary
1)(节点201 node1) 故障
# cd /data
# touch 1 2 3 4 5
# cd ..
# umount /data
# drbdsetup /dev/drbd0 secondary 故障后。降级为从
注:这里实际生产环境若DRBD1宕机,在DRBD2状态信息中ro的值会显示为Secondary/Unknown,只需要进行DRBD提权操作即可。
# service drbd status
(节点202 node2 提权为主)
# drbdsetup /dev/drbd0 primary 提权为主
# mount /dev/drbd0 /data
# cd /data
# touch 6 7 8 9 10
# ls
1 10 2 3 4 5 6 7 8 9 lost+found
# service drbd status
不过如何保证DRBD主从结构的智能切换,实现高可用,这里就需要Heartbeat来实现了,Heartbeat会在DRBD主端挂掉的情况下,自动切换从端为主 端并自动挂载/data分区;
总结: 这里是DRBD官方推荐的手动恢复方案:
假设你把Primary的eth0宕掉,然后直接在Secondary上进行主Primary主机的提升,并且mount上,你可能会发现在 Primary上测试考入的文件确实同 步过来了,之后把Primary的eth0恢复后,看看有没有自动恢复 主从关系。经过查看,发现DRBD检测出了Split-Brain的状况,也就是两个节点都处于standalone 状态,故障描述如下:Split- Brain detected,dropping connection! 这就是传说中的“脑裂” ;
(node2)
# drbdadm secondary r0
# drbdadm disconnect all
# drbdadm --discard-my-data connect r0
(node1)
# drbdadm disconnect all
# drbdadm connect r0
# drbdsetup /dev/drbd0 primary