1》查询语句的基本语法
语法:
SELECT 属性列表
FROM 表名
[WHERE 条件表达式 1]
[GROUP BY 属性名1 [HAVING 条件表达式2]]
[ORDER BY 属性名2 [ASC | DESC]]
属性列表表示需要查询的字段名
表名表示指的表名
WHERE 表示指定查询的条件
GROUP BY 指定的字段进行分组
如果GROUP BY 子句后面带着HAVING关键字,那么只有满足条件2才能输出。
2》在单表上查询数据:
v 列出表的所有字段
root@zytest 16:19>select order_num,order_date,cust_id from orders;
v 使用*查出单表所有字段
root@zytest 16:22>select * from orders;
v 查询指定的字段
在orders表中有3个字段,order_num、order_date、cust_id,我们查询其中2个。
root@zytest 16:22>select order_num,order_date from orders;
v where查询指定记录
root@zytest 16:53>select * from orders where cust_id=10003;
*****比较
root@zytest 16:53>select * from orders where cust_id<=10003;小于或者等于
root@zytest 16:56>select * from orders where cust_id>=10003;大于或者等于
root@zytest 16:56>select * from orders where cust_id>10003;大于
root@zytest 16:56>select * from orders where cust_id<10003;小于
root@zytest 16:57>select * from orders where cust_id != 10003; 不等于
root@zytest 16:57>select * from orders where cust_id <> 10003;排除掉10003
指定范围
root@zytest 16:57>select * from orders where cust_id between 10003 and 10004;
root@zytest 16:57>select * from orders where cust_id not between 10003 and 10004;
指定集合
root@zytest 16:57>select * from orders where cust_id in(10001,10004);
root@zytest 16:57>select * from orders where cust_id not in(10003,10004);
匹配字符
root@zytest 16:57>select * from orders where cust_id like ‘10001’;
root@zytest 16:57>select * from orders where cust_id not like ‘10001’;
是否为空值
root@zytest 16:57>select * from vendors where vend_state is null;
root@zytest 16:57>select * from vendors where vend_state is not null;
多条件查询
root@zytest 16:57>select * from orders where cust_id=10003 and order_num=20005;
root@zytest 16:57>select * from orders where cust_id=10003 or cust_id=10005;
查询结果不重复(distinct)字段名
语法:select distinct 字段名
select distinct cust_id from orders;
查询结果进行排序
语法:order by 属性名 [ASC|DESC]
select distinct cust_id from orders where cust_id>10003 order by cust_id desc;
查询数据进行分组group by
语法:group by 属性名 [having 条件表达式][with rollup]
having用来限制分组后的显示,满足条件表达式的结果将被显示
with rollup 关键字将会在所有记录的最后加上一条记录,该记录是上面所有记录的总和.
group关键字通常和group_concat()函数一起使用.group_concat把每个分组指定的字段值显示出来.
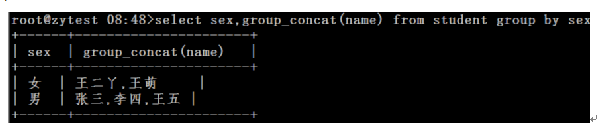
group by 使用having条件约束过滤having 跟where作用一样。但是having只能用于group by 。
select sex,count(sex),group_concat(name) from student group by sex having sex='女';
group by 多个字段进行分组
select sex,count(sex),group_concat(name) from student group by sex,user_id having sex='女';
group by 与with rollup一起使用
root@zytest 10:02>select sex,count(sex) from student group by sex;
得出了分组出来的数量。如果想得到分组出来的总和怎么办?
我们后面再加上with rollup就可以得出。
root@zytest 10:02>select sex,count(sex) from student group by sex with rollup;
对单个字段进行普通分组
root@zytest 06:56>select * from student group by address;
结合group_concat()进行指定每个分组的值
root@zytest 08:48>select sex,group_concat(name) from student group by sex;

使用limint限制查询结果的数量
root@zytest 10:07>select * from student where user_id >2 limit 2;
3》使用集合函数查询数据:
集合函数包括:
count() 用来统计记录的条数
sum() 用来计算字段的值和总数
avg() 用来计算字段的值的平均值
max() 用来查询字段的最大值
min() 用来查询字段的最小值
count()总计所有记录的条目总数
root@zytest 10:24>select count(*) from student;
sum字段值得总和
root@zytest 10:25>select sum(user_id) from student;
avg 取平均值
root@zytest 10:25>select avg(user_id) from student;
max()取字段值得最大值
root@zytest 10:27>select max(user_id) from student;
min()取字段值得最小值
root@zytest 10:28>select min(user_id) from student;
4》多表连接查询:
1>内连接
具有相同意义的字段,才可以进行内连接:
root@zytest 15:56>select cust_name,cust_address,order_date from customers,orders
where customers.cust_id=orders.cust_id;
2>外连接
外连接包括左查询和右查询
select属性名列表
from 表名1 left | right join 表名2 on 表名1.属性名=表名2.属性名;
左连接查询:
可以查询出表名1里面所有的数据,而表名2只能查出匹配的记录。
以下例子:表名1=vendors(主表)表名2=products(匹配表)
root@zytest 17:42>select vendors.vend_id,prod_name,prod_price from vendors left join products on
vendors.vend_id=products.vend_id;
右连接查询
可以查询出表名2所有的记录。而表名1只能查出匹配记录。
以下例子:表名2=products(主表) 表名1=vendors(匹配表)
root@zytest 17:52>select products.vend_id,prod_name from vendors right join products on
vendors.vend_id=products.vend_id;
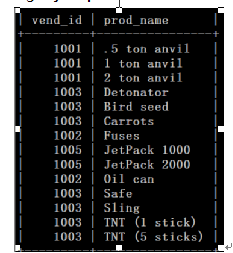
看不到1006?因为products里面没有1006,所以在vendors表中不匹配。这里用用vendors ID去匹配products。有则匹配。
复合查询:
在左连接或者右连接查询出来之后如何进一步过滤?
root@zytest 18:18>select products.vend_id,prod_name,vend_name,vendors.vend_id from vendors right
join products on vendors.vend_id=products.vend_id where products.prod_name='Safe';
在后面直接加where就行了。
5》子查询:
子查询时将一个查询语句内嵌到另个查询语句当中。内层查询的查询结果,可以为外层查询语句提供查询条件;
1>带IN关键字的子查询
insert into student values('10005','aaaaa','','aaaaaa');
insert into student values('10006','aaaaa','','aaaaaa');
insert into student values('10003','aaaaa','','aaaaaa');
root@zytest 18:40>select * from orders where cust_id in (select user_id from student);
root@zytest 18:55>select * from orders where cust_id in (select user_id from student) and cust_id>'10003';进一步过滤
6》合并查询:
有时候需要多个表进行合并数据。我们使用union和union all,使用union时系统会将合并的结果去掉重复。并且显示。但是union all恰恰相反,不会去掉 重复,会把所有的内容全部显示出来;
root@zytest 19:06>select vend_id from vendors union select vend_id from products;
root@zytest 19:07>select vend_id from vendors union all select vend_id from products;
7》为表和字段取别名:
为表取别名:
select * from student aa where aa.user_id='1';
为字段取别名:
select user_id as alvinzeng from student;
mysql> select * from yy1 aa where aa.user_id=1;
+---------+-----------+
| user_id | user_name |
+---------+-----------+
| 1 | zhangsan |
+---------+-----------+
1 row in set (0.00 sec)
8》使用正则查看:
在我们的mysql当中,照样可以使用正则表达式来查询结果;
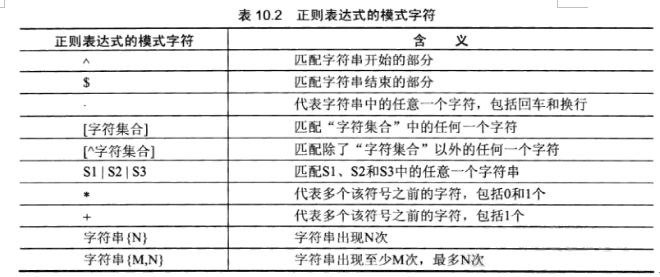
正则我们使用关键字“regexp”来连接正则
select * from vendors where vend_name regexp '^An';以An开头的
select * from vendors where vend_city regexp 's$';以s结尾的
select * from vendors where vend_city regexp '.d';如果字符后面包含d
select * from vendors where vend_city regexp 'd.'; d后面包含的任意字符
select * from vendors where vend_city regexp '[London]';只要包含中括号里面任意一个字符的都会被显示出来
select * from vendors where vend_city regexp '[^Paris]';匹配除了Paris以外的所有字符,也就是说Paris将被过滤掉了。
select * from vendors where vend_state regexp 'MI|OH';匹配MI或者OH任意一个满足都会被显示出来。
select * from vendors where vend_state regexp 'M*';匹配以包含M后面的任何字符。
select * from vendors where vend_name regexp 'll+';代表多个字符前面或者后面的任何字符
select * from vendors where vend_city regexp 'd{1}';查询d出现过1次或者N次
select * from vendors where vend_city regexp 'd{1,3}';查询d出现过1次,最多出现3次,
=====================Mysql存储过程与存储函数=================
1》创建存储过程:
语法:
MySQL中,创建存储过程的基本形式如下:
1>CREATE PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
create 是创建的的意思
procedure 是指的创建的类型是存储过程。
sp_name参数是存储过程的名称;
proc_parameter表示存储过程的参数列表;
characteristic参数指定存储过程的特性;
routine_body参数是SQL代码的内容,可以用BEGIN…END来标志SQL代码的开始和结束。
proc_parameter中的每个参数由3部分组成。这3部分分别是输入输出类型、参数名称和参数类型。其形式如下:
[ IN | OUT | INOUT ] param_name type
其中,IN表示输入参数;OUT表示输出参数; INOUT表示既可以是输入,也可以是输出; param_name参数是存储过程的参数名称;type参数指 定存储过程的参数类型,该类型可以是MySQL数据库的任意数据类型。
说明:MySQL中默认的语句结束符为分号(;)。存储过程中的SQL语句需要分号来 结束。为了避免冲突,首先用"DELIMITER &&"将MySQL的结束符 设置为&&。最后再用"DELIMITER ;"来将结束符恢复成分号。这与创建触发器时是一样的。
2>存储过程和存储函数的区别:
存储过程和函数目的是为了可重复地执行操作数据库的SQL语句的集合,区别是写法和调用上:
写法上:存储过程的参数列表可以有输入参数,输出参数,可以输入输出参数。函数的参数列表只有输入参数,并且有return<返回值类型,无长度说 明>
在返回值上的区别:存储过程的返回值,可以有多个值,函数返回值,只有一个值;
举例1:
需求一、存储过程一(功能返回Mysql的版本号、用户、所在数据库、用户连接数、)
Delimiter &&
create procedure alvin1(
out getversion varchar(30),
out userversion varchar(30),
out userdatabase varchar(30),
out userconnection int)
reads sql data
begin
select version() into getversion;
select user() into userversion;
select database() into userdatabase;
select connection_id() into userconnection;
end &&
delimiter ;
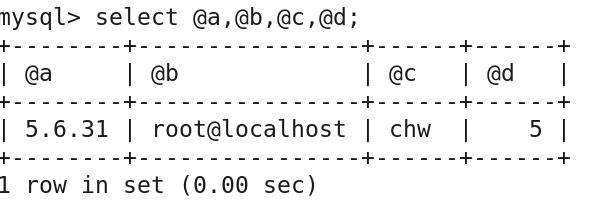
call alvin1(@a,@b,@c,@d);
select @a,@b,@c,@d;
需求二、统计student id的数据量总共是多少?
create procedure alvin2(
out zycount int)
reads sql data
begin
select count(*) into zycount from student;
end&&
delimiter ;
call alvin2(@a);
select @a;
2》变量的使用:
在整个存储和函数中,可以定义和使用变量,用户可以使用declare关键字来定义变量,然后可以为变量赋值,这些变量的作用范围是begin…end程序 中。
1>定义变量
declare aa_id int default 10;
2>为变量赋值
set aa_id=1001;
IN参数例子:
root@zytest 23:15>delimiter &&
root@zytest 23:16>create procedure alvin1( #创建一个名字为alvin1存储过程
-> in p_in int) #设置传入的参数类型和变量
-> begin
-> select p_in; #查询第一次传进来的参数
-> set p_in=2; #:重新给p_in 赋值后。覆盖掉传进来的参数值
-> select p_in; #:在查询一次赋值
->end&&
root@zytest 23:19>delimiter ;
root@zytest 23:19>set @p_in=1;#开始传入参数赋值
root@zytest 23:19>call alvin1(@p_in);#调用存储过程
+------+
| p_in |
+------+
| 1| #传入的值为1,
+------+
1 row in set (0.03 sec)
+------+
| p_in |
+------+
| 2 | #过程当中的二次赋值
+------+
1 row in set (0.03 sec)
Query OK 0 rows affected (0.03 sec)
root@zytest 23:20>select @p_in; #查询外边传参赋值的结果
+-------+
| @p_in |
+-------+
| 1 |
+-------+
OUT参数例子:
root@zytest 23:41>delimiter &&
root@zytest 23:41>create procedure name_info(创建一个名称为name_info的存储过程
-> out p_out int) #定义输出的变量和数据类型
-> begin
-> select p_out; #查看输出参数
-> set p_out=2; #给参数赋值
-> select p_out; #查询赋值结果
->end&&
Query OK, 0 rows affected (0.00 sec)
root@zytest 23:42>delimiter ;
root@zytest 23:42>set @p_out=1; #传入一个参数。看看是否会在call调用的时候显示出来?
Query OK, 0 rows affected (0.00 sec)
root@zytest 23:42>call name_info(@p_out);
+-------+
| p_out |
+-------+
| NULL | #传入的参数为空
+-------+
1 row in set (0.01 sec)
+-------+
| p_out |
+-------+
| 2 | #存储函数里面赋值的参数调用成功
+-------+
1 row in set (0.01 sec)
root@zytest 23:42>select @p_out;
+--------+
| @p_out |
+--------+
| 2 | #:只看到存储函里面赋值的。传入的参数无效。
+--------+
1 row in set (0.00 sec)
INOUT参数列子:
root@zytest 00:03>delimiter &&
root@zytest 00:03>create procedure alvin_name( #创建一个名为alvin_name的函数
-> inout p_inout int) #创建一个可以传入和传出的p_inout的变量和数据类型
-> begin
-> select p_inout; #:查询传入的数据
-> set p_inout=2; #:给p_inout的赋值
-> select p_inout; #:在此查询p_inout的值
->end&&
root@zytest 00:04>delimiter ;
root@zytest 00:04>set @p_inout=1; #:开始传入参数
Query OK, 0 rows affected (0.00 sec)
root@zytest 00:04>call alvin_name(@p_inout); #:开始调用
+---------+
| p_inout |
+---------+
| 1 | #使用inout既可以传入可以传出
+---------+
1 row in set (0.00 sec)
+---------+
| p_inout |
+---------+
| 2 | #使用inout既可以传入可以传出
+---------+
1 row in set (0.00 sec)
root@zytest 00:04>select @p_inout; #查询最后结果
+----------+
| @p_inout |
+----------+
| 2 | #:可以传出也可以传入,最终返回结果为2,
+----------+
1 row in set (0.00 sec)
3》创建存储函数:
语法:create function sp_name([func_parameter[,…….]])
Returns type
[characteristic…]routine_body。
其中,sp_name参数是存储函数的名称。
Func_parameter 表示存储函数的参数列表。
Returns type 指定返回的参数类型。
characteristic参数指定存储函数的特性。
routine_body参数是SQL代码的内容。
可以用BEGIN…END来标志 SQL代码开始和结束。
create function 函数名(参数1 数据类型[,参数2 数据类型,参数3 数据类型])returns 返回值类型
begin
任意系列的sql语句;
return 返回值;
end;
注:与储存过程不同
1、参数只有输入型
2、向调用方返回结果值
常见的错误:
This function has none of DETERMINISTIC, NO SQL解决办法
创建存储过程时
出错信息:
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
其中在function里面,只有 DETERMINISTIC, NO SQL 和 READS SQL DATA 被支持。如果我们开启了 bin-log, 我们就必须为我们的function指定一个参数。
解决方法:
SQL code
mysql> show variables like 'log_bin_trust_function_creators';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| log_bin_trust_function_creators | OFF |
+---------------------------------+-------+
mysql> set global log_bin_trust_function_creators=1;
mysql> show variables like 'log_bin_trust_function_creators';
+---------------------------------+-------+w
| Variable_name | Value |
+---------------------------------+-------+
| log_bin_trust_function_creators | ON |
+---------------------------------+-------+
这样添加了参数以后,如果mysqld重启,那个参数又会消失,因此记得在my.cnf配置文件中添加:
log_bin_trust_function_creators=1
举列:根据输入的vend_id查询到每个用户的vend_name。
delimiter&&
create function alvin11( #创建一个函数名称为alvin11
bb_id int)#定义一个参数类型和它的数据类型
returns varchar(20)#定义下面vend_name的返回数据类型
begin # 开始
return (select vend_name from vendors#返回 SQL语句查询的结果,
where vend_id=bb_id);
end && #结束
delimiter ;#跳出总体段落。
select alvin11(1001);#调用存储函数-查询结果
4》流程控制:
1>存储过程if语句使用方法:
delimiter&&
create procedure zy_if(in aa int,out bb int)
begin
if aa>20 then
set bb=30;
elseif aa=20
then
set bb=20;
else
set bb=15;
end if;
end&&
delimiter ;
开始调用1 aa=20
call zy_if(20,@bb);
select @bb;
开始调用2 aa=25
call zy_if(25,@bb);
select @bb;
开始调用3 aa=15
call zy_if(15,@bb);
select @bb;
2>存储过程case用法
delimiter&&
create procedure zy_case(in aa int,inout bb int)
begin
case
when aa=20 then set bb=20;
when aa>20 and aa<=50 then set bb=30;
when aa>51 then set bb=60;
else set bb=15;
end case;
end&&
delimiter ;
开始调用验证1
call zy_case(20,@bb);
select @bb;
开始调用验证2
call zy_case(21,@bb);
select @bb;
开始调用验证3
call zy_case(52,@bb);
select @bb;
开始调用验证4
call zy_case(10,@bb);
select @bb;
3>存储过程 while 循环使用,插入1万条数据
delimiter&&
create procedure zy_while()
begin
declare count int default 0;
while count < 10000 do
insert into zybb (user_id,name)values(count,'aa1');
set count = count + 1;
end while;
end&&
delimiter ;
call zy_while();调用存储过程
5》调用存储过程和函数:
1>调用方式call +存储过程名称+参数
如:call alvin_name(@p_inout);
2>查询结果
select @p_inout
6》查看存储过程和函数:
1>查询存储过程
show procedure status;
查询某具体存储过程详细
show create procedure alvin1G;
2>查询存储函数
show function status;
查询某个具体存储函数详细
show create function alvin10G;
7》删除存储过程和函数:
1>删除存储过程
drop procedure alvin1;
2>删除存储函数
drop function alvin1;