Windows10制作LMDB详细教程
原创不易,转载请注明出处:https://www.cnblogs.com/xiaoboge/p/10678658.html
摘要:
当我们在使用Caffe做深度学习项目时,经常需要制作Caffe常用的数据类型lmdb、leveldb以及hdf5等(尽管可以使用原始图片,效率低),而不是我们常见的JPG、PNG、TIF。因此,我们需要对我们采集的数据进行格式转换,即通过输入我们自己的图片目录(包含有训练集和验证集的大量图片)转换成一个lmdb库文件的输出;这个过程一般是有Caffe工具中的convert_imageset.exe,该工具在编译过的Caffe中,具体位置是:D:你的根目录caffecaffe-windowsBuildx64Releaseconvert_imageset.exe。
开始正文:
格式转换的4个必要条件:
(1)编译好Caffe,而且convert_imageset.exe存在;
(2)需要被转换的图像和目录,注意它们是有要求的(请看稍后的文件目录架构);
(3)在将图像转换为lmdb格式之前,首先生成两个标签文件train.txt和val.txt(具体格式见下文);
(4)运行编辑修改好的create_imagenet.sh(最好将其制到你的项目文件夹下,不修改原始文件)生成lmdb文件。
所在位置:D:你的caffe根目录caffecaffe-windowsexamplesimagenet
1. 数据集的组织架构(文件目录结构)
接下来,我将会使用一个例子详细介绍即将要使用的数据集的目录结构。这里制作的是一个分类数据集,主要包括两个类别:dog和cat,我们用数字0表示dog的类别,数字1来表示cat类别。在总目录data_set文件夹下,包括两个子文件夹分别是train和val,它们分别存储着训练集和验证集的所有图片。在train文件夹下 也包含两个子文件夹,它们分别是“0”和“1”,里面分别存储的是dog和cat的所有图像。在val的文件夹下没有子文件夹(其实也可以像train一样),直接是将要用于验证的图像数据,我们可以根据图像的名字知道它所属的类别,便于写出val.txt文件。鉴于这一步是格式转换的基础,我将整个目录详细结构用图展示如下:

(1)数据集根目录所在路径:C:UsersAdministratorDesktop

(2)data_set的子文件夹:C:UsersAdministratorDesktopdata_set

(3)train的子文件夹:C:UsersAdministratorDesktopdata_set rain

(a)“0”文件夹下的文件:C:UsersAdministratorDesktopdata_set rain�
这里图片文件的名字其实可以随意,因为文件夹就指出了它所属的类别。

(b)“1”文件夹下的文件:C:UsersAdministratorDesktopdata_set rain1
这里图片文件的名字其实可以随意,因为文件夹就指出了它所属的类别。

(4)val的子文件夹:C:UsersAdministratorDesktopdata_setval
这里的图像文件的名字必须可以判断它所属的类别,我们使用python中的split()函数可以将文件名以“_”分隔开来获取图像所属类别,具体见程序。

至此,我已经详细介绍了整个数据集的详细目录结构,我相信这已经足够详细啦!接下来,我们开始更至关重要的一步操作。
2. 如何制作train.txt和val.txt
如果想要将图像数据转换为LMDB数据格式,不仅要使用上述的数据集文件目录,还需要这些图片存放的路径以及该图片的标签(属于哪个类);一般情况下,标签文件有两个,一个是描述训练集合的train.txt,另一个是描述验证集的val.txt,这两个文件的格式稍微有点差别,具体格式如下:
(1)train.txt的文件格式
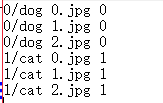
注意:该文件中分别存储了图像的路径和所属的类别,“0”表示dog,“1”表示cat。这里也没有打乱图像的顺序,可以在制作LMDB的时候打乱。
(2)val.txt的文件格式

注意:这里的验证集的标签文件无需分类存储(像train一样分成两个文件夹),但是我们必须可以判断每张图片的所属类别。
到目前为止,我们已经知道了所要制作的train.txt和val.txt的格式要求了;接下来就是怎样从我们的数据集出发,制作属于自己数据集的train.txt和val.txt,这个制作的过程并不是固定的,每个人可以根据自己的习惯使用熟悉的语言(例如,python、c++)去完成这一步骤。还有根据项目的实际不同需求,可能要写的程序也是不完全一样的,但是我想这一编程实现输出train.txt和val.txt对于一个程序员来说是非常基础操作。我在这里针对这个例子写一段python代码来实现这个操作,虽然写的不是很好,但是能够实现我们的需求,我也对它进行了详细的注释。代码展示如下(python语言所示),程序的名称是:generate_txt.py
1 # -*- coding: utf-8 -*- 2 # @Time : 2018/12/9 0009 12:04 3 # @Author : sunjianbo 4 # @Email : 1871593109@qq.com 5 # @Software: PyCharm 6 import os 7 #数据集根目录所在路径 8 root_data_path = r"C:UsersAdministratorDesktopdata_set" 9 #输出的TXT文件路径 10 traintxt_path = root_data_path + "\" + "train.txt" 11 valtxt_path = root_data_path + "\" + "val.txt" 12 13 #如果存在之前生成的TXT文件,先把它们删除 14 if os.path.exists(traintxt_path): 15 os.remove(traintxt_path) 16 if os.path.exists(valtxt_path): 17 os.remove(valtxt_path) 18 #返回数据集文件夹下的子文件夹 19 filenames = os.listdir(root_data_path) #["train", "val"] 20 21 #打开要存储的TXT文件 22 file_train = open(traintxt_path, "w") 23 file_val = open(valtxt_path, "w") 24 25 if len(filenames) > 0: 26 for fn in filenames: 27 #数据集根目录下的子文件夹路径,train和val的绝对路径 28 full_filename = os.path.join(root_data_path, fn) 29 30 # 判断是训练集文件夹,还是验证集文件夹 31 if fn == "train": 32 #找出训练集文件夹下的子文件夹名字,是每个类别的文件夹,0表示狗,1表示猫 33 file = os.listdir(full_filename) #["0", "1"] 34 for name in file: 35 #获得train文件夹下的子文件夹“0”和“1”的绝对路径 36 temp = os.path.join(full_filename, name) 37 for img in os.listdir(temp): #分别遍历两个文件夹["0", "1"]下的所有图像 38 #将图像的信息写入到train.txt文件 39 file_train.write(name + "/" + img + " " + name + " ") 40 elif fn == "val": #当进入到val文件夹后 41 for img in os.listdir(full_filename): #遍历所有的图像 42 category = img.split('_') #对图像的名字进行分割,返回的是一个列表 43 if category[0] == "dog": #当分割的结果可以判断是dog时,类别是“0” 44 file_val.write(img + " " + "0" + " ") 45 elif category[0] == "cat": #当分割的结果可以判断是cat时,类别是“1” 46 file_val.write(img + " " + "1" + " ") 47 else: 48 print("验证集中图片名字有误") 49 else: 50 print("存在错误文件夹") 51 else: 52 print("该文件夹下不存在子文件夹") 53 54 file_train.close() 55 file_val.close()
运行上面的程序:generate_txt.py,可以在数据集所在目录(data_set文件夹下面)生成两个train.txt和val.txt文件。生成之后的目录结构如下:

其中,两条黄色线连接的部分就是运行上面的generate_txt.py生成的。
现在,我们已经完成了转换LMDB数据格式最重要的一步了。接下来的步骤将很简单,我们继续往下走。
3. 开始制作LMDB格式的数据
在完成以上的工作的基础上,我们通过上面的4个文件(两个train和val的图像库,两个train.txt和val.txt标签列表),把图像的数据和其对应的标签打包起来,生成我们需要的LMDB格式的数据。
首先,我们需要找到制作LMDB格式的create_imagenet.sh,它的原始地址在D:program_filescaffecaffe-windowsexamplesimagenet,找到该文件之后将其复制到自己的项目文件夹(可以修改名称),我这里把它放在了data_set的文件夹下,然后进行相应的路径设置就可以运行create_imagenet.sh(或者是修改后的名称)。下面展示了原始的create_imagenet.sh文件,但是我对参数进行了注释和说明,并且添加了关于判断是否已经生成过LMDB文件的一步,如果存在删除它生成最新的。
(1)原始的create_imagenet.sh文件
1 #!/usr/bin/env sh 2 # Create the imagenet lmdb inputs #创建LMDB格式的文件输入 3 # N.B. set the path to the imagenet train + val data dirs #为train和val数据目录设置路径 4 5 EXAMPLE=examples/imagenet #生成模型训练数据的文件夹,即create_imagenet.sh(这里名字可以修改)所在文件夹,也就是最终的LMDB数据存储的位置。 6 DATA=data/ilsvrc12 #python脚本处理完的数据存储路径,也就是train.txt和val.txt的存储路径 7 TOOLS=build/tools #caffe的工具库,需要找到自己编译过的convert_imageset.exe,具体位置在D:/program_files/caffe/caffe-windows/Build/x64/Release 8 9 TRAIN_DATA_ROOT=/path/to/imagenet/train/ #待处理的图像训练数据的路径 10 VAL_DATA_ROOT=/path/to/imagenet/val/ #待处理的图像验证数据的路径 11 12 # Set RESIZE=true to resize the images to 256x256. Leave as false if images have 13 # already been resized using another tool. 14 RESIZE=false #是否对图片进行resize操作,如果是设置为True 15 if $RESIZE; then 16 RESIZE_HEIGHT=256 #resize的尺寸是256*256 17 RESIZE_WIDTH=256 18 else 19 RESIZE_HEIGHT=0 20 RESIZE_WIDTH=0 21 fi 22 23 if [ ! -d "$TRAIN_DATA_ROOT" ]; then 24 echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT" 25 echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" 26 "where the ImageNet training data is stored." 27 exit 1 28 fi 29 30 if [ ! -d "$VAL_DATA_ROOT" ]; then 31 echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT" 32 echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" 33 "where the ImageNet validation data is stored." 34 exit 1 35 fi 36 37 38 echo "if train.txt and val.txt are exist in EXAMPLE dir. clear all" 39 #删除已存在的lmdb格式文件,若在已存在lmdb格式的文件夹下再添加lmdb文件,会出现错误 40 rm -rf $EXAMPLE/train_lmdb 41 rm -rf $EXAMPLE/val_lmdb 42 43 44 echo "Creating train lmdb..." 45 46 GLOG_logtostderr=1 $TOOLS/convert_imageset #调用convert_imageset进行格式转换 47 --resize_height=$RESIZE_HEIGHT #将图片调整到固定尺寸 48 --resize_width=$RESIZE_WIDTH 49 --shuffle #打乱图像的顺序 50 $TRAIN_DATA_ROOT 51 $DATA/train.txt #这里的DATA是存放train.txt的路径 52 $EXAMPLE/ilsvrc12_train_lmdb #这里修改输出的训练集的LMDB的名称 53 54 echo "Creating val lmdb..." 55 56 GLOG_logtostderr=1 $TOOLS/convert_imageset #调用convert_imageset进行格式转换 57 --resize_height=$RESIZE_HEIGHT #将图片调整到固定尺寸 58 --resize_width=$RESIZE_WIDTH 59 --shuffle #打乱图像的顺序 60 $VAL_DATA_ROOT 61 $DATA/val.txt #这里的DATA是存放val.txt的路径 62 $EXAMPLE/ilsvrc12_val_lmdb #这里修改输出的验证集的LMDB的名称 63 64 echo "Done."
(2)基于本例子的修改后的create_imagenet.sh文件如下,名称改为:convert_my_LMDB.sh
1 #!/usr/bin/env sh 2 # Create the imagenet lmdb inputs #创建LMDB格式的文件输入 3 # N.B. set the path to the imagenet train + val data dirs #为train和val数据目录设置路径 4 5 EXAMPLE=C:/Users/Administrator/Desktop/data_set #生成模型训练数据的文件夹,即create_imagenet.sh(这里名字可以修改)所在文件夹。 6 DATA=C:/Users/Administrator/Desktop/data_set #python脚本处理完的数据存储路径,也就是train.txt和val.txt的存储路径 7 TOOLS=D:/program_files/caffe/caffe-windows/Build/x64/Release #caffe的工具库,找到自己的编译过的convert_imageset.exe所在的位置 8 9 TRAIN_DATA_ROOT=C:/Users/Administrator/Desktop/data_set/train/ #待处理的训练数据的路径 10 VAL_DATA_ROOT=C:/Users/Administrator/Desktop/data_set/val/ #待处理的验证数据的路径 11 12 # Set RESIZE=true to resize the images to 256x256. Leave as false if images have 13 # already been resized using another tool. 14 RESIZE=true #是否对图片进行resize操作,如果是设置为True 15 if $RESIZE; then 16 RESIZE_HEIGHT=256 #resize的尺寸是256*256 17 RESIZE_WIDTH=256 18 else 19 RESIZE_HEIGHT=0 20 RESIZE_WIDTH=0 21 fi 22 23 if [ ! -d "$TRAIN_DATA_ROOT" ]; then 24 echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT" 25 echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" 26 "where the ImageNet training data is stored." 27 exit 1 28 fi 29 30 if [ ! -d "$VAL_DATA_ROOT" ]; then 31 echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT" 32 echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" 33 "where the ImageNet validation data is stored." 34 exit 1 35 fi 36 37 38 echo "if train.txt and val.txt are exist in EXAMPLE dir. clear all" 39 #删除已存在的lmdb格式文件,若在已存在lmdb格式的文件夹下再添加lmdb文件,会出现错误 40 rm -rf $EXAMPLE/train_lmdb 41 rm -rf $EXAMPLE/val_lmdb 42 43 44 echo "Creating train lmdb..." 45 46 GLOG_logtostderr=1 $TOOLS/convert_imageset #调用convert_imageset进行格式转换 47 --resize_height=$RESIZE_HEIGHT #将图片调整到固定尺寸 48 --resize_width=$RESIZE_WIDTH 49 --shuffle #打乱图像的顺序 50 $TRAIN_DATA_ROOT 51 $DATA/train.txt #这里的DATA是存放train.txt的路径 52 $EXAMPLE/train_lmdb #这里修改输出的训练集的LMDB的名称 53 54 echo "Creating val lmdb..." 55 56 GLOG_logtostderr=1 $TOOLS/convert_imageset #调用convert_imageset进行格式转换 57 --resize_height=$RESIZE_HEIGHT #将图片调整到固定尺寸 58 --resize_width=$RESIZE_WIDTH 59 --shuffle #打乱图像的顺序 60 $VAL_DATA_ROOT 61 $DATA/val.txt #这里的DATA是存放val.txt的路径 62 $EXAMPLE/val_lmdb #这里修改输出的验证集的LMDB的名称 63 64 echo "Done."
read #最后加一行read,可以让窗口暂停等待,相当于pause。
这里修改的位置有:第5行、第6行、第9行、第10行、第14行、第52行、第62行。最终,在data_set文件夹下面生成了两个文件夹train_lmdb和val_lmdb,它们分别存储了训练集和测试集的转换数据和标签。在windows系统上不可以直接运行sh文件,因此我们需要去安装一下Git,并将安装好的Git的bin文件路径加入到环境变量,就可以双击执行sh文件啦。当sh文件运行完成之后(这里的运行其实是调用了D:program_filescaffecaffe-windowsBuildx64Releaseconvert_imageset.exe格式转换可执行程序),文件的目录结构图如下所示:

至此,我们的LMDB的数据格式就真正做完了,是不是并不是很难!
4. 另一种制作LMDB数据格式的方法(windows下不需要安装Git)
首先,我们看一下转换数据之前的文件目录结构(和之前一样):
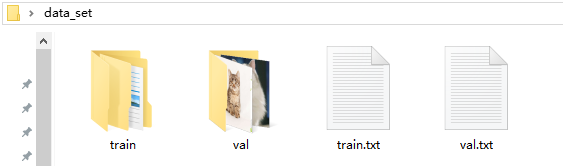
在以上四个文件的基础上进行转换,首先在data_set文件夹下创建一个convert_my_lmdb.txt文件,在该文件中写入一段批处理文件(详细内容如下),然后将文件格式修改为批处理文件即convert_my_lmdb.bat,他可以在windows环境下双击直接运行。
1 D:program_filescaffecaffe-windowsBuildx64Releaseconvert_imageset.exe --gray --resize_width=144 --resize_height=144 ./train/ train.txt train_lmdb -backend=lmdb 2 D:program_filescaffecaffe-windowsBuildx64Releaseconvert_imageset.exe --gray --resize_width=144 --resize_height=144 ./val/ val.txt val_lmdb -backend=lmdb 3 pause
其中,D:program_filescaffecaffe-windowsBuildx64Releaseconvert_imageset.exe,表示编译好之后的转换程序,及其所在的位置;
--gray,表示灰度化处理;
--resize_width=144 ,--resize_height=144,表示图像的resize处理;
./train/ train.txt,表示使用相对路径来获得train.txt位置,还有val.txt位置;
train_lmd,bval_lmdb,分别表示生成的训练集和验证集的LMDB格式文件夹的名称;
-backend=lmdb,表示转换的格式是LMDB
运行上述编辑好的convert_my_lmdb.bat,可以在data_set文件夹下生成我们想要的LMDB格式数据,结果如下所示:

OK,基本上结束了!接下来我会写一下注意事项!
5. 注意事项
(1)注意windows系统中路径问题,复制的路径是“”,在程序中需要的是“/”,注意对其修改,生成的train.txt和val.txt中的路径也是“/”。
(2)必须保证你的caffe编译成功
(3)修改convert_imageset.sh时,一定要注意路径问题,这里就是配置路径的很容易出错(具体请看上面的详细过程)。
(4)图像的名字中不要出现空格,否则会有问题(深刻的痛)。
(5)生成的train.txt文件中的图像路径问题:路径从train文件夹之后开始写,不包括train文件夹名称。
(6)如果之前生成过文件(不管是train.txt和val.txt,还是train_lmdb和val_lmdb),想重新生成,最好先删除之前的,有可能会有错误。
(7)请严格按照上述步骤一步一步进行,否则也可能会报错。
转载请注明:https://www.cnblogs.com/xiaoboge/p/10678658.html