1 神经网络模型
以下面神经网络模型为例,说明神经网络中正向传播和反向传播过程及代码实现
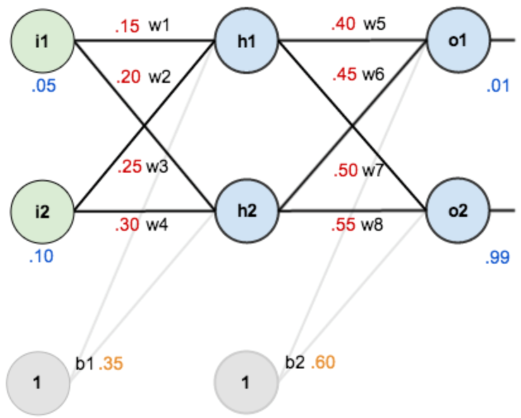
1.1 正向传播
(1)输入层神经元(i_1,i_2),输入层到隐藏层处理过程
(2)隐藏层:神经元(h_1,h_2),隐藏层到输出层处理过程
1.2 反向传播
反向传播是根据每次前向传播得到的误差来评估每个神经网络层中的权重对其的影响程度,再根据链式规则和梯度下降对权重进行更新的过程,下面以对更新权重(w_5和w_1)为例进行说明
- totalo1表示参考值0.01
- totalo2参考值0.99
1.2.1 更新权重w_5
其中:$$frac{partial totalo1}{partial o_1} = frac{partial frac{1}{2}{(totalo_1 - o_1)}^2}{partial o_1} = -(totalo_1 -o_1)$$
则:$$frac{partial totalo1}{partial w_5} = -(totalo_1 -o_1)o_1(1-o_1)h_1$$
更新w_5的值:$$w_5new = w_5 - learningrate * frac{partial totalo1}{partial w_5}$$
1.2.2 更新权重w_1
(求w_1的偏导与求w_5偏导唯一的区别在于,w_1的值影响了o_1和o_2),所以
接下来的求导思路和上面一样:
更新w_1的值:$$w_1new = w_1 - learningrate * frac{partial total}{partial w_1}$$
2. 代码实现正向和方向传播算法
import random
import math
class NeuralNetwork:
learning_rate = 0.5
def __init__(self,input_num,hidden_num,output_num,input_hidden_weights=None,
input_hidden_bias=None,hidden_output_weights=None,hidden_output_bias=None):
self.input_num = input_num
# 构建掩藏层
self.hidden_layer = NeuralLayer(hidden_num,input_hidden_bias)
# 构建输出层
self.output_layer = NeuralLayer(output_num,hidden_output_bias)
# 初始化输入层到隐藏层权重
self.init_input_to_hidden_weights(input_hidden_weights)
# 初始化隐藏层到输出层权重
self.init_hidden_to_output_weights(hidden_output_weights)
def init_input_to_hidden_weights(self,weights):
weight_num = 0
for i_num in range(len(self.hidden_layer.neurons)):
for o_num in range(self.input_num):
if weights is None:
self.hidden_layer.neurons[i_num].weights.append(random.random())
else:
self.hidden_layer.neurons[i_num].weights.append(weights[weight_num])
weight_num += 1
def init_hidden_to_output_weights(self,weights):
weight_num = 0
for i_num in range(len(self.output_layer.neurons)):
for o_num in range(len(self.hidden_layer.neurons)):
if weights is None:
self.output_layer.neurons[i_num].weights.append(random.random())
else:
self.output_layer.neurons[i_num].weights.append(weights[weight_num])
weight_num += 1
def inspect(self):
print('..................')
print('input inspect:',[i for i in self.inputs])
print('..................')
print('hidden inspect:')
self.hidden_layer.inspect()
print('..................')
print('output inspect:')
self.output_layer.inspect()
print('..................')
def forward(self,inputs):
hidden_layer_outout = self.hidden_layer.forward(inputs)
print('hidden_layer_outout',hidden_layer_outout)
ouput_layer_ouput = self.output_layer.forward(hidden_layer_outout)
print('ouput_layer_ouput',ouput_layer_ouput)
return ouput_layer_ouput
def train(self,x,y):
ouput_layer_ouput = self.forward(x)
# 求total / neto的偏导
total_o_pd = [0] * len(self.output_layer.neurons)
for o in range(len(self.output_layer.neurons)):
total_o_pd[o] = self.output_layer.neurons[o].calculate_total_net_pd(y[o])
# 求total / h的偏导 = total.1 / h的偏导 + total.2 / h的偏导
total_neth_pd = [0] * len(self.hidden_layer.neurons)
for h in range(len(self.hidden_layer.neurons)):
total_h_pd = 0
for o in range(len(self.output_layer.neurons)):
total_h_pd += total_o_pd[o] * self.hidden_layer.neurons[h].weights[o]
total_neth_pd[h] = total_h_pd * self.output_layer.neurons[h].calculate_output_net_pd()
# 更新输出层神经元权重
for o in range(len(self.output_layer.neurons)):
for ho_w in range(len(self.output_layer.neurons[o].weights)):
ho_w_gradient = total_o_pd[o] * self.output_layer.neurons[o].calculate_net_linear_pd(ho_w)
self.output_layer.neurons[o].weights[ho_w] -= self.learning_rate * ho_w_gradient
# 更新隐藏层神经元权重
for h in range(len(self.hidden_layer.neurons)):
for ih_w in range(len(self.hidden_layer.neurons[h].weights)):
ih_w_gradient = total_neth_pd[h] * self.hidden_layer.neurons[h].calculate_net_linear_pd(ih_w)
self.hidden_layer.neurons[h].weights[ih_w] -= self.learning_rate * ih_w_gradient
def calculate_total_error(self, training_sets):
total_error = 0
for t in range(len(training_sets)):
training_inputs, training_outputs = training_sets[t]
self.forward(training_inputs)
for o in range(len(training_outputs)):
total_error += self.output_layer.neurons[o].calculate_error(training_outputs[o])
return total_error
class NeuralLayer:
def __init__(self,neural_num,bias):
self.bias = bias if bias else random.random()
self.neurons = []
for i in range(neural_num):
self.neurons.append(Neuron(self.bias))
def inspect(self):
print('weights:',[neuron.weights for neuron in self.neurons])
print('bias:',[neuron.bias for neuron in self.neurons])
def get_output(self,inputs):
outputs = []
for neuron in self.neurons:
outputs.append(neuron.output)
return outputs
def forward(self,inputs):
outputs = []
for neuron in self.neurons:
outputs.append(neuron.calculate_output(inputs))
return outputs
class Neuron:
def __init__(self,bias):
self.bias = bias
self.weights = []
def calculate_output(self,inputs):
self.inputs = inputs
total_net_outputs = self.calculate_total_net_output()
self.output = self.sigmoid(total_net_outputs)
return self.output
def calculate_total_net_output(self):
total = 0
for i in range(len(self.inputs)):
total += self.inputs[i] * self.weights[i]
return total + self.bias
def sigmoid(self,total_net_input):
return 1 / (1 + math.exp(-total_net_input))
def calculate_total_output_pd(self,total_output):
return -(total_output - self.output)
def calculate_output_net_pd(self):
return self.output * (1 - self.output)
def calculate_total_net_pd(self,total_output):
return self.calculate_total_output_pd(total_output) * self.calculate_output_net_pd()
def calculate_net_linear_pd(self,index):
return self.inputs[index]
def calculate_error(self, target_output):
return 0.5 * (target_output - self.output) ** 2
nn = NeuralNetwork(2, 2, 2, input_hidden_weights=[0.15, 0.2, 0.25, 0.3], input_hidden_bias=0.35,
hidden_output_weights=[0.4, 0.45, 0.5, 0.55], hidden_output_bias=0.6)
for i in range(10000):
nn.train([0.05, 0.1], [0.01, 0.99])
print(i, round(nn.calculate_total_error([[[0.05, 0.1], [0.01, 0.99]]]), 9))
hidden_layer_outout [0.5932699921071872, 0.596884378259767]
ouput_layer_ouput [0.7513650695523157, 0.7729284653214625]
hidden_layer_outout [0.5932662857458805, 0.5968782561589732]
ouput_layer_ouput [0.7420894573166411, 0.775286681791022]
迭代1次 误差0.291028391
hidden_layer_outout [0.5932662857458805, 0.5968782561589732]
ouput_layer_ouput [0.7420894573166411, 0.775286681791022]
hidden_layer_outout [0.5932623797502049, 0.5968720205376407]
ouput_layer_ouput [0.7324789213021788, 0.7775850216973027]
迭代2次 误差 0.283547957
hidden_layer_outout [0.5932623797502049, 0.5968720205376407]
ouput_layer_ouput [0.7324789213021788, 0.7775850216973027]
hidden_layer_outout [0.5932582778661456, 0.5968656853189723]
ouput_layer_ouput [0.7225410209751278, 0.7798256906644981]
迭代3次 误差 0.275943973
hidden_layer_outout [0.5932582778661456, 0.5968656853189723]
ouput_layer_ouput [0.7225410209751278, 0.7798256906644981]
hidden_layer_outout [0.5932539857457403, 0.5968592652405116]
ouput_layer_ouput [0.7122866732919141, 0.7820107943242337]
迭代4次 误差0.268233041
...
...
...
hidden_layer_outout [0.5930355856011269, 0.5965960242813179]
ouput_layer_ouput [0.016365976874939202, 0.9836751989707726]
hidden_layer_outout [0.5930355857116121, 0.5965960243868048]
ouput_layer_ouput [0.016365393177895763, 0.9836757760229975]
迭代10000次 误差 4.0257e-05
迭代10000次后结果:
hidden_layer_outout [0.5930355856011269, 0.5965960242813179]
ouput_layer_ouput [0.016365976874939202, 0.9836751989707726]
hidden_layer_outout [0.5930355857116121, 0.5965960243868048]
ouput_layer_ouput [0.016365393177895763, 0.9836757760229975]
迭代10000次 误差 4.0257e-05
参考:https://www.cnblogs.com/charlotte77/p/5629865.html,感谢博主的分析