类别型特征原始输入通常是字符串形式,除了决策树等少数模型能直接处理字符串形式的输入,对于逻辑回归、支持向量机等模型来说,类别型特征必须经过处理转换成数值型。Sklearn中提供了几个转换器来处理文本属性,下面将总结LabelEncode(序号编码)、OneHotEncoder(独热编码)和LabelBinarizer(二进制编码)转换器用法
1. 类图结构
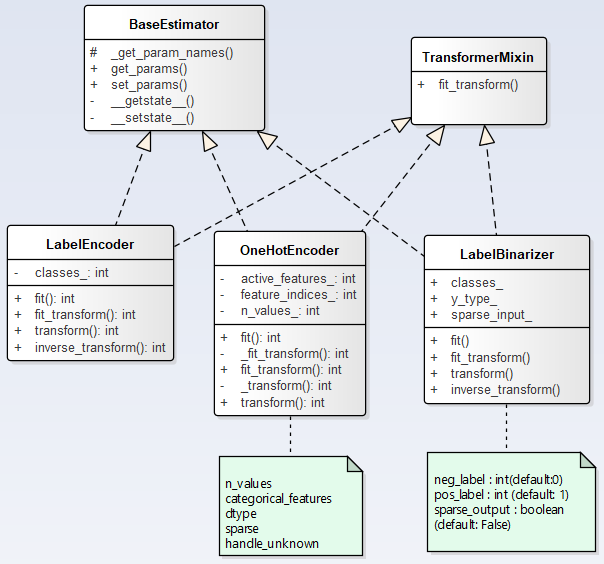
2. LabelEncode用法
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
示例:
labels = [1,2,2,6] le = LabelEncoder() le.fit(labels) print("classes_:",le.classes_) print("transform:",le.transform([1, 2, 2, 6])) print('fit_transform:',le.fit_transform(labels)) print('inverser_transform:',le.inverse_transform([0, 0, 1, 2]))
输出:

当labels换成文本标签时
labels = ['aa','cc','dd','bb'] le = LabelEncoder() le.fit(labels) print("classes_:",le.classes_) print("transform:",le.transform(['aa','cc','dd','bb'])) print('fit_transform:',le.fit_transform(labels)) print('inverser_transform:',le.inverse_transform([0, 2, 3, 1]))
输出:

3. OneHotEncoder用法
OneHotEncoder(n_values=’auto’, categorical_features=’all’, dtype=<class ‘numpy.float64’>, sparse=True, handle_unknown=’error’)
(1)参数
n_values = 'auto' --->表示每个特征使用几维的数值由数据集自动推断,即几种类别就使用几位来表示,还可以自己设置
- int : number of categorical values per feature. Each feature value should be in ``range(n_values)`` - array : ``n_values[i]`` is the number of categorical values in ``X[:, i]``. Each feature value should be in ``range(n_values[i])``
categorical_features = 'all' --->这个参数指定了对哪些特征进行编码,默认对所有类别都进行编码。也可以自己指定选择哪些特征,通过索引或者 bool 值来指定
enc = OneHotEncoder() enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) print(enc.transform([[0,1,3]]).toarray())
输出:

我们先来看第一个特征,即第一列 [0,1,0,1][0,1,0,1],也就是说它有两个取值 0 或者 1,那么 one-hot 就会使用两位来表示这个特征,[1,0][1,0] 表示 0, [0,1][0,1] 表示 1,在上例输出结果中的前两位 [1,0...][1,0...] 也就是表示该特征为 0
第二个特征,第二列 [0,1,2,0][0,1,2,0],它有三种值,那么 one-hot 就会使用三位来表示这个特征,[1,0,0][1,0,0] 表示 0, [0,1,0][0,1,0] 表示 1,[0,0,1][0,0,1] 表示 2,在上例输出结果中的第三位到第六位 [...0,1,0,0...][...0,1,0,0...] 也就是表示该特征为 1
第二个特征,第三列 [3,0,1,2][3,0,1,2],它有四种值,那么 one-hot 就会使用四位来表示这个特征,[1,0,0,0][1,0,0,0] 表示 0, [0,1,0,0][0,1,0,0] 表示 1,[0,0,1,0][0,0,1,0] 表示 2,[0,0,0,1][0,0,0,1] 表示 3,在上例输出结果中的最后四位 [...0,0,0,1][...0,0,0,1] 也就是表示该特征为 3
示例:
array = np.array([1,2,3]) ohe = OneHotEncoder() labels = ohe.fit_transform(array.reshape(-1,1)) print(labels.toarray())
[[ 1. 0. 0.] [ 0. 1. 0.] [ 0. 0. 1.]]
4. LabelBinarizer用法
(1)参数
neg_label : int (default: 0) Value with which negative labels must be encoded. pos_label : int (default: 1) Value with which positive labels must be encoded. sparse_output : boolean (default: False) True if the returned array from transform is desired to be in sparse CSR format.
(2)示例
使用LabelBinarizer可以一次性完成LabelEncoder和OneHotEncoder(从文本类别转化为整数类别,再从整数类别转换为独热向量)
lb = preprocessing.LabelBinarizer() lb.fit_transform(['yes', 'no', 'no', 'yes']) array([[1],[0],[0],[1]])